 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Manifold Learning for No-Reference Image Quality Assessment
Jun 27, 2024



Contrastive learning has considerably advanced the field of Image Quality Assessment (IQA), emerging as a widely adopted technique. The core mechanism of contrastive learning involves minimizing the distance between quality-similar (positive) examples while maximizing the distance between quality-dissimilar (negative) examples. Despite its successes, current contrastive learning methods often neglect the importance of preserving the local manifold structure. This oversight can result in a high degree of similarity among hard examples within the feature space, thereby impeding effective differentiation and assessment. To address this issue, we propose an innovative framework that integrates local manifold learning with contrastive learning for No-Reference Image Quality Assessment (NR-IQA). Our method begins by sampling multiple crops from a given image, identifying the most visually salient crop. This crop is then used to cluster other crops from the same image as the positive class, while crops from different images are treated as negative classes to increase inter-class distance. Uniquely, our approach also considers non-saliency crops from the same image as intra-class negative classes to preserve their distinctiveness. Additionally, we employ a mutual learning framework, which further enhances the model's ability to adaptively learn and identify visual saliency regions. Our approach demonstrates a better performance compared to state-of-the-art methods in 7 standard datasets, achieving PLCC values of 0.942 (compared to 0.908 in TID2013) and 0.914 (compared to 0.894 in LIVEC).
Cantor: Inspiring Multimodal Chain-of-Thought of MLLM
Apr 24, 2024With the advent of large language models(LLMs) enhanced by the chain-of-thought(CoT) methodology, visual reasoning problem is usually decomposed into manageable sub-tasks and tackled sequentially with various external tools. However, such a paradigm faces the challenge of the potential "determining hallucinations" in decision-making due to insufficient visual information and the limitation of low-level perception tools that fail to provide abstract summaries necessary for comprehensive reasoning. We argue that converging visual context acquisition and logical reasoning is pivotal for tackling visual reasoning tasks. This paper delves into the realm of multimodal CoT to solve intricate visual reasoning tasks with multimodal large language models(MLLMs) and their cognitive capability. To this end, we propose an innovative multimodal CoT framework, termed Cantor, characterized by a perception-decision architecture. Cantor first acts as a decision generator and integrates visual inputs to analyze the image and problem, ensuring a closer alignment with the actual context. Furthermore, Cantor leverages the advanced cognitive functions of MLLMs to perform as multifaceted experts for deriving higher-level information, enhancing the CoT generation process. Our extensive experiments demonstrate the efficacy of the proposed framework, showing significant improvements in multimodal CoT performance across two complex visual reasoning datasets, without necessitating fine-tuning or ground-truth rationales. Project Page: https://ggg0919.github.io/cantor/ .
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024



Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
Adaptive Feature Selection for No-Reference Image Quality Assessment using Contrastive Mitigating Semantic Noise Sensitivity
Dec 11, 2023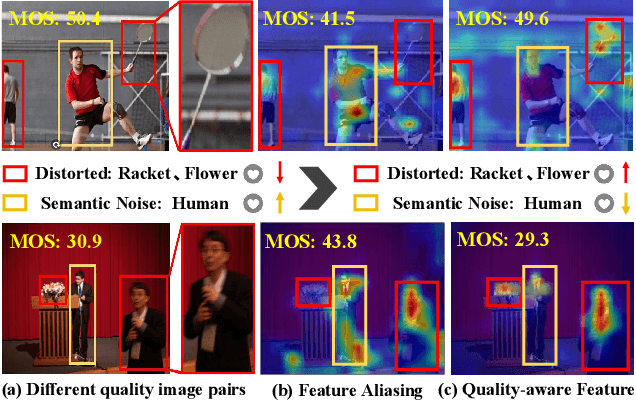
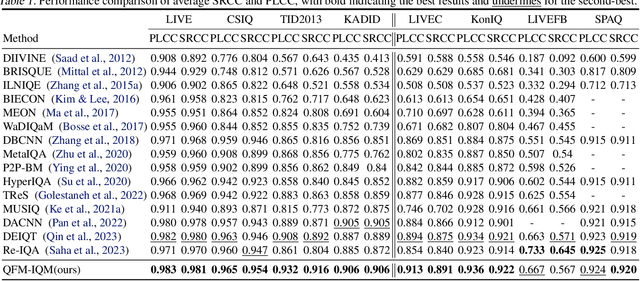
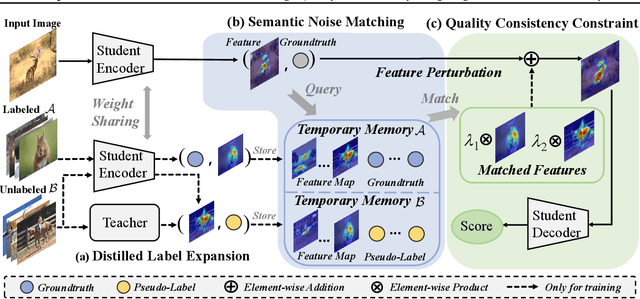
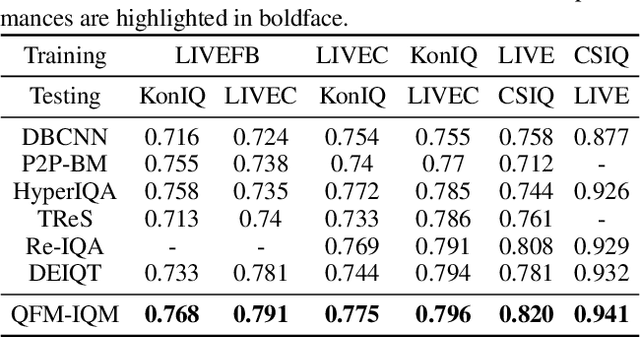
The current state-of-the-art No-Reference Image Quality Assessment (NR-IQA) methods typically use feature extraction in upstream backbone networks, which assumes that all extracted features are relevant. However, we argue that not all features are beneficial, and some may even be harmful, necessitating careful selection. Empirically, we find that many image pairs with small feature spatial distances can have vastly different quality scores. To address this issue, we propose a Quality-Aware Feature Matching IQA metric(QFM-IQM) that employs contrastive learning to remove harmful features from the upstream task. Specifically, our approach enhances the semantic noise distinguish capabilities of neural networks by comparing image pairs with similar semantic features but varying quality scores and adaptively adjusting the upstream task's features by introducing disturbance. Furthermore, we utilize a distillation framework to expand the dataset and improve the model's generalization ability. Our approach achieves superior performance to the state-of-the-art NR-IQA methods on 8 standard NR-IQA datasets, achieving PLCC values of 0.932 (vs. 0.908 in TID2013) and 0.913 (vs. 0.894 in LIVEC).