 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUFF: Bayesian Uncertainty Guided Diffusion Probabilistic Model for Single Image Super-Resolution
Apr 04, 2025Super-resolution (SR) techniques are critical for enhancing image quality, particularly in scenarios where high-resolution imagery is essential yet limited by hardware constraints. Existing diffusion models for SR have relied predominantly on Gaussian models for noise generation, which often fall short when dealing with the complex and variable texture inherent in natural scenes. To address these deficiencies, we introduce the Bayesian Uncertainty Guided Diffusion Probabilistic Model (BUFF). BUFF distinguishes itself by incorporating a Bayesian network to generate high-resolution uncertainty masks. These masks guide the diffusion process, allowing for the adjustment of noise intensity in a manner that is both context-aware and adaptive. This novel approach not only enhances the fidelity of super-resolved images to their original high-resolution counterparts but also significantly mitigates artifacts and blurring in areas characterized by complex textures and fine details. The model demonstrates exceptional robustness against complex noise patterns and showcases superior adaptability in handling textures and edges within images. Empirical evidence, supported by visual results, illustrates the model's robustness, especially in challenging scenarios, and its effectiveness in addressing common SR issues such as blurring. Experimental evaluations conducted on the DIV2K dataset reveal that BUFF achieves a notable improvement, with a +0.61 increase compared to baseline in SSIM on BSD100, surpassing traditional diffusion approaches by an average additional +0.20dB PSNR gain. These findings underscore the potential of Bayesian methods in enhancing diffusion processes for SR, paving the way for future advancements in the field.
Gamma: Toward Generic Image Assessment with Mixture of Assessment Experts
Mar 09, 2025

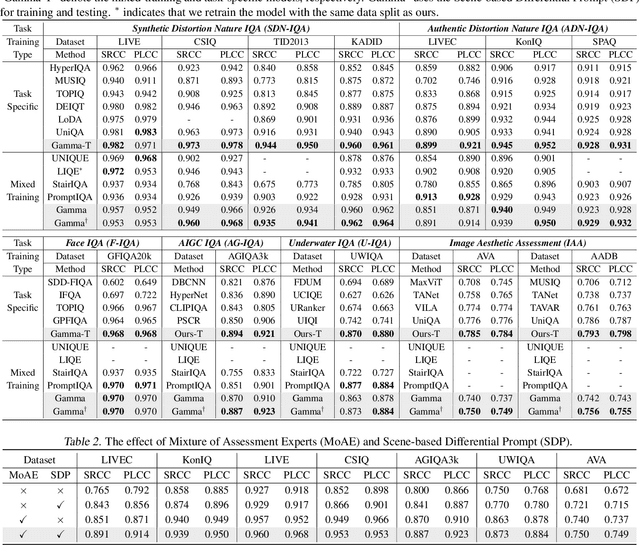

Image assessment aims to evaluate the quality and aesthetics of images and has been applied across various scenarios, such as natural and AIGC scenes. Existing methods mostly address these sub-tasks or scenes individually. While some works attempt to develop unified image assessment models, they have struggled to achieve satisfactory performance or cover a broad spectrum of assessment scenarios. In this paper, we present \textbf{Gamma}, a \textbf{G}eneric im\textbf{A}ge assess\textbf{M}ent model using \textbf{M}ixture of \textbf{A}ssessment Experts, which can effectively assess images from diverse scenes through mixed-dataset training. Achieving unified training in image assessment presents significant challenges due to annotation biases across different datasets. To address this issue, we first propose a Mixture of Assessment Experts (MoAE) module, which employs shared and adaptive experts to dynamically learn common and specific knowledge for different datasets, respectively. In addition, we introduce a Scene-based Differential Prompt (SDP) strategy, which uses scene-specific prompts to provide prior knowledge and guidance during the learning process, further boosting adaptation for various scenes. Our Gamma model is trained and evaluated on 12 datasets spanning 6 image assessment scenarios. Extensive experiments show that our unified Gamma outperforms other state-of-the-art mixed-training methods by significant margins while covering more scenes. Code: https://github.com/zht8506/Gamma.
Boosting CLIP Adaptation for Image Quality Assessment via Meta-Prompt Learning and Gradient Regularization
Sep 09, 2024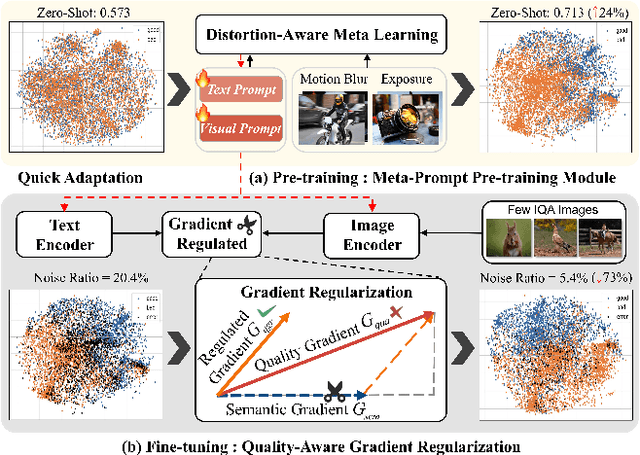
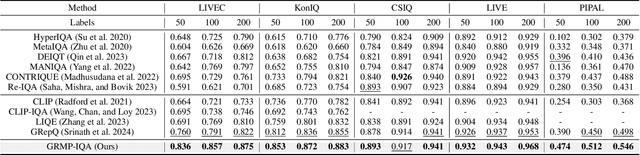


Image Quality Assessment (IQA) remains an unresolved challenge in the field of computer vision, due to complex distortion conditions, diverse image content, and limited data availability. The existing Blind IQA (BIQA) methods heavily rely on extensive human annotations to train models, which is both labor-intensive and costly due to the demanding nature of creating IQA datasets. To mitigate the dependence on labeled samples, this paper introduces a novel Gradient-Regulated Meta-Prompt IQA Framework (GRMP-IQA). This framework aims to fast adapt the powerful visual-language pre-trained model, CLIP, to downstream IQA tasks, significantly improving accuracy in scenarios with limited data. Specifically, the GRMP-IQA comprises two key modules: Meta-Prompt Pre-training Module and Quality-Aware Gradient Regularization. The Meta Prompt Pre-training Module leverages a meta-learning paradigm to pre-train soft prompts with shared meta-knowledge across different distortions, enabling rapid adaptation to various IQA tasks. On the other hand, the Quality-Aware Gradient Regularization is designed to adjust the update gradients during fine-tuning, focusing the model's attention on quality-relevant features and preventing overfitting to semantic information. Extensive experiments on five standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods under limited data setting, i.e., achieving SRCC values of 0.836 (vs. 0.760 on LIVEC) and 0.853 (vs. 0.812 on KonIQ). Notably, utilizing just 20\% of the training data, our GRMP-IQA outperforms most existing fully supervised BIQA methods.
UniQA: Unified Vision-Language Pre-training for Image Quality and Aesthetic Assessment
Jun 03, 2024

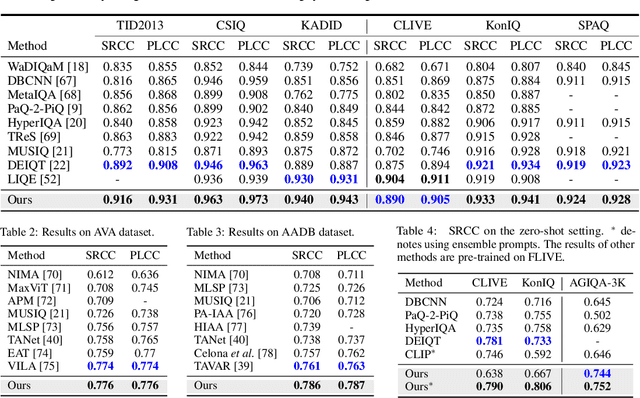

Image Quality Assessment (IQA) and Image Aesthetic Assessment (IAA) aim to simulate human subjective perception of image visual quality and aesthetic appeal. Existing methods typically address these tasks independently due to distinct learning objectives. However, they neglect the underlying interconnectedness of both tasks, which hinders the learning of task-agnostic shared representations for human subjective perception. To confront this challenge, we propose Unified vision-language pre-training of Quality and Aesthetics (UniQA), to learn general perceptions of two tasks, thereby benefiting them simultaneously. Addressing the absence of text in the IQA datasets and the presence of textual noise in the IAA datasets, (1) we utilize multimodal large language models (MLLMs) to generate high-quality text descriptions; (2) the generated text for IAA serves as metadata to purify noisy IAA data. To effectively adapt the pre-trained UniQA to downstream tasks, we further propose a lightweight adapter that utilizes versatile cues to fully exploit the extensive knowledge of the pre-trained model. Extensive experiments demonstrate that our approach attains a new state-of-the-art performance on both IQA and IAA tasks, while concurrently showcasing exceptional zero-shot and few-label image assessment capabilities. The source code will be available at https://github.com/zht8506/UniQA.
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024



Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
Video Object Segmentation with Dynamic Query Modulation
Mar 18, 2024
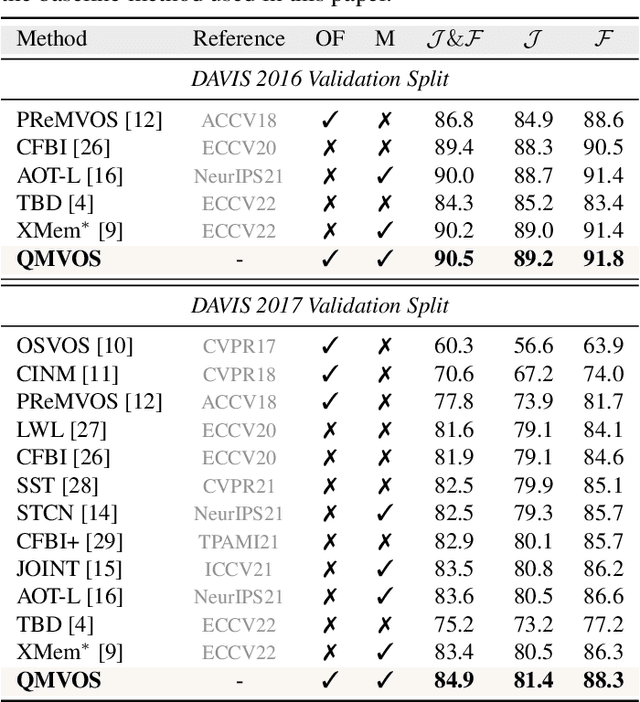


Storing intermediate frame segmentations as memory for long-range context modeling, spatial-temporal memory-based methods have recently showcased impressive results in semi-supervised video object segmentation (SVOS). However, these methods face two key limitations: 1) relying on non-local pixel-level matching to read memory, resulting in noisy retrieved features for segmentation; 2) segmenting each object independently without interaction. These shortcomings make the memory-based methods struggle in similar object and multi-object segmentation. To address these issues, we propose a query modulation method, termed QMVOS. This method summarizes object features into dynamic queries and then treats them as dynamic filters for mask prediction, thereby providing high-level descriptions and object-level perception for the model. Efficient and effective multi-object interactions are realized through inter-query attention. Extensive experiments demonstrate that our method can bring significant improvements to the memory-based SVOS method and achieve competitive performance on standard SVOS benchmarks. The code is available at https://github.com/zht8506/QMVOS.
Concealed Object Segmentation with Hierarchical Coherence Modeling
Jan 22, 2024



Concealed object segmentation (COS) is a challenging task that involves localizing and segmenting those concealed objects that are visually blended with their surrounding environments. Despite achieving remarkable success, existing COS segmenters still struggle to achieve complete segmentation results in extremely concealed scenarios. In this paper, we propose a Hierarchical Coherence Modeling (HCM) segmenter for COS, aiming to address this incomplete segmentation limitation. In specific, HCM promotes feature coherence by leveraging the intra-stage coherence and cross-stage coherence modules, exploring feature correlations at both the single-stage and contextual levels. Additionally, we introduce the reversible re-calibration decoder to detect previously undetected parts in low-confidence regions, resulting in further enhancing segmentation performance. Extensive experiments conducted on three COS tasks, including camouflaged object detection, polyp image segmentation, and transparent object detection, demonstrate the promising results achieved by the proposed HCM segmenter.
Feature Denoising Diffusion Model for Blind Image Quality Assessment
Jan 22, 2024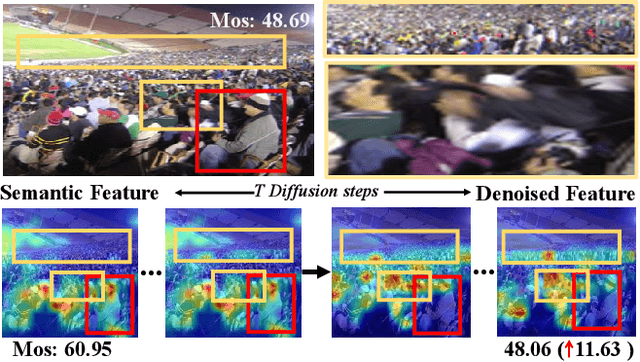
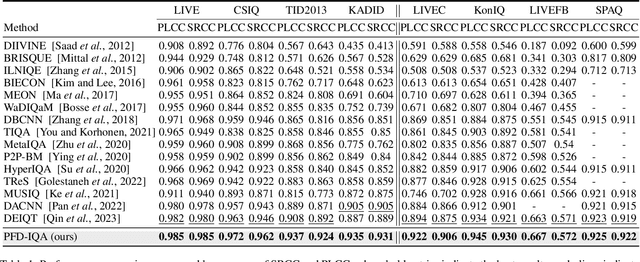
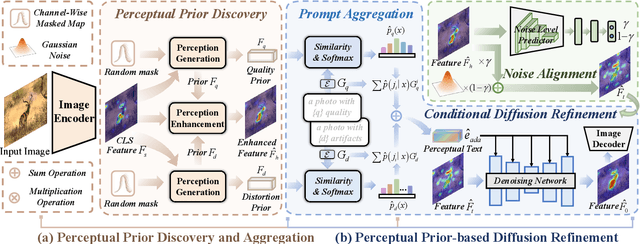
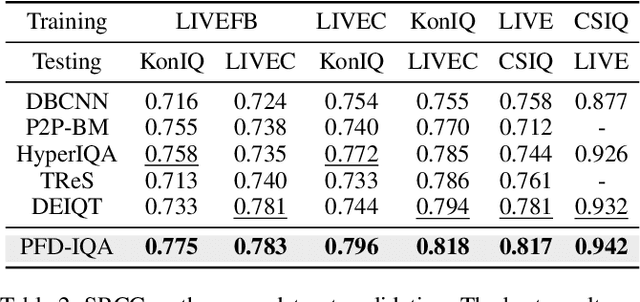
Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).
Adaptive Feature Selection for No-Reference Image Quality Assessment using Contrastive Mitigating Semantic Noise Sensitivity
Dec 11, 2023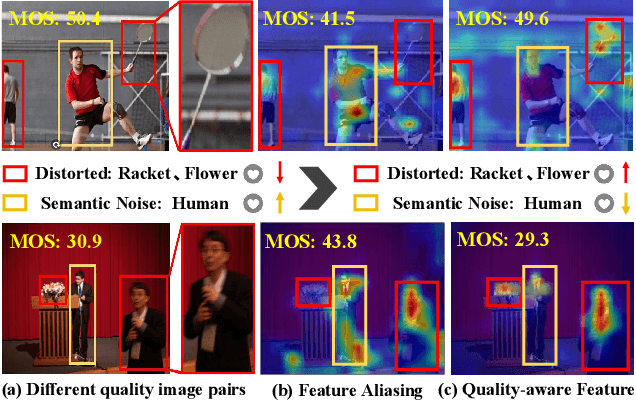
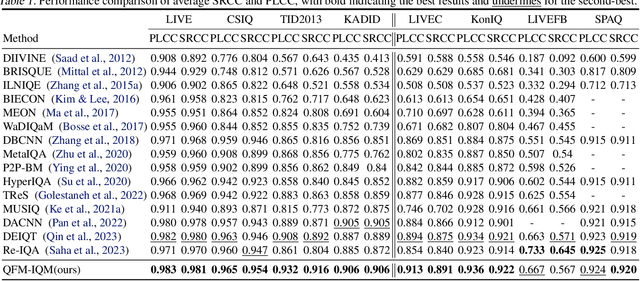
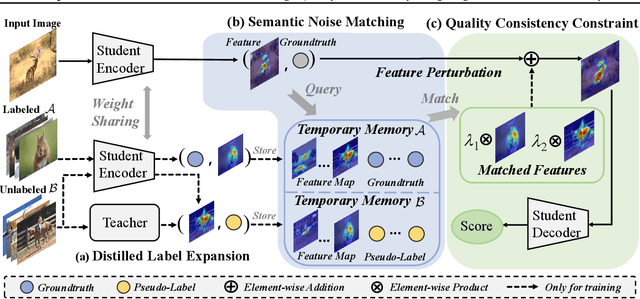
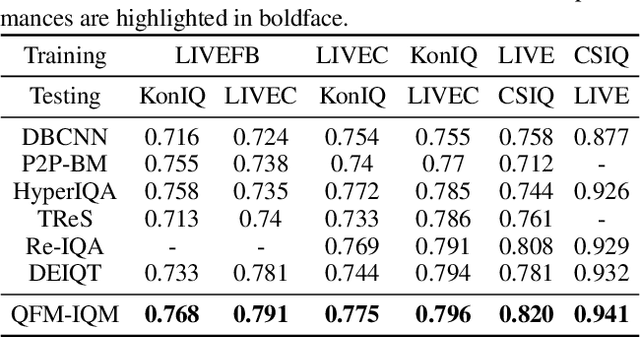
The current state-of-the-art No-Reference Image Quality Assessment (NR-IQA) methods typically use feature extraction in upstream backbone networks, which assumes that all extracted features are relevant. However, we argue that not all features are beneficial, and some may even be harmful, necessitating careful selection. Empirically, we find that many image pairs with small feature spatial distances can have vastly different quality scores. To address this issue, we propose a Quality-Aware Feature Matching IQA metric(QFM-IQM) that employs contrastive learning to remove harmful features from the upstream task. Specifically, our approach enhances the semantic noise distinguish capabilities of neural networks by comparing image pairs with similar semantic features but varying quality scores and adaptively adjusting the upstream task's features by introducing disturbance. Furthermore, we utilize a distillation framework to expand the dataset and improve the model's generalization ability. Our approach achieves superior performance to the state-of-the-art NR-IQA methods on 8 standard NR-IQA datasets, achieving PLCC values of 0.932 (vs. 0.908 in TID2013) and 0.913 (vs. 0.894 in LIVEC).
Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment
Dec 01, 2023Image Quality Assessment (IQA) with reference images have achieved great success by imitating the human vision system, in which the image quality is effectively assessed by comparing the query image with its pristine reference image. However, for the images in the wild, it is quite difficult to access accurate reference images. We argue that it is possible to learn reference knowledge under the No-Reference Image Quality Assessment (NR-IQA) setting, which is effective and efficient empirically. Concretely, by innovatively introducing a novel feature distillation method in IQA, we propose a new framework to learn comparative knowledge from non-aligned reference images. And then, to achieve fast convergence and avoid overfitting, we further propose an inductive bias regularization. Such a framework not only solves the congenital defects of NR-IQA but also improves the feature extraction framework, enabling it to express more abundant quality information. Surprisingly, our method utilizes less input while obtaining a more significant improvement compared to the teacher models. Extensive experiments on eight standard NR-IQA datasets demonstrate the superior performance to the state-of-the-art NR-IQA methods, i.e., achieving the PLCC values of 0.917 (vs. 0.884 in LIVEC) and 0.686 (vs. 0.661 in LIVEFB).