 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Object Segmentation with Dynamic Query Modulation
Paper and Code

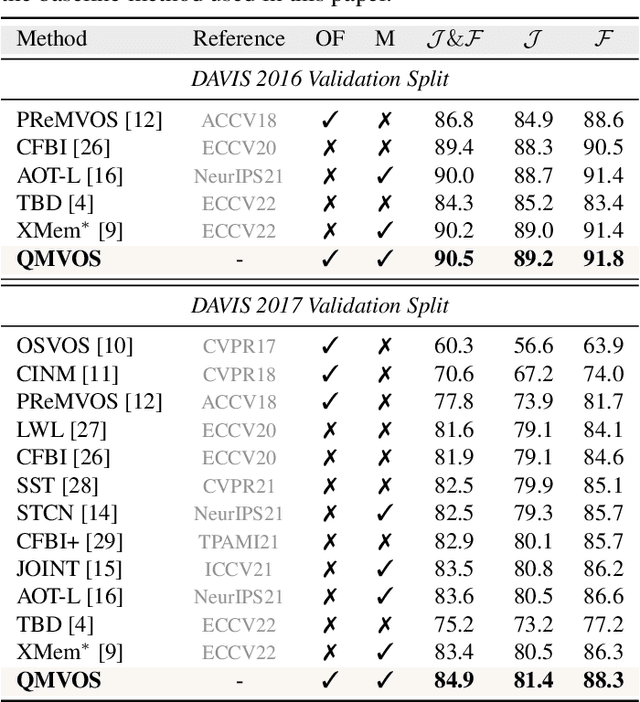


Storing intermediate frame segmentations as memory for long-range context modeling, spatial-temporal memory-based methods have recently showcased impressive results in semi-supervised video object segmentation (SVOS). However, these methods face two key limitations: 1) relying on non-local pixel-level matching to read memory, resulting in noisy retrieved features for segmentation; 2) segmenting each object independently without interaction. These shortcomings make the memory-based methods struggle in similar object and multi-object segmentation. To address these issues, we propose a query modulation method, termed QMVOS. This method summarizes object features into dynamic queries and then treats them as dynamic filters for mask prediction, thereby providing high-level descriptions and object-level perception for the model. Efficient and effective multi-object interactions are realized through inter-query attention. Extensive experiments demonstrate that our method can bring significant improvements to the memory-based SVOS method and achieve competitive performance on standard SVOS benchmarks. The code is available at https://github.com/zht8506/QMVOS.