 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Task-oriented Agent: Proactive Long-term Intent Maintenance in Dynamic Environments
Jan 14, 2026Current large language model agents predominantly operate under a reactive paradigm, responding only to immediate user queries within short-term sessions. This limitation hinders their ability to maintain long-term user's intents and dynamically adapt to evolving external environments. In this paper, we propose a novel interaction paradigm for proactive Task-oriented Agents capable of bridging the gap between relatively static user's needs and a dynamic environment. We formalize proactivity through two key capabilities, (i) Intent-Conditioned Monitoring: The agent autonomously formulates trigger conditions based on dialog history; (ii) Event-Triggered Follow-up: The agent actively engages the user upon detecting useful environmental updates. We introduce a high-quality data synthesis pipeline to construct complex, multi-turn dialog data in a dynamic environment. Furthermore, we attempt to address the lack of evaluation criteria of task-oriented interaction in a dynamic environment by proposing a new benchmark, namely ChronosBench. We evaluated some leading close-source and open-source models at present and revealed their flaws in long-term task-oriented interaction. Furthermore, our fine-tuned model trained using synthetic data for supervised learning achieves a task completion rate of 85.19% for complex tasks including shifts in user intent, outperforming other models under test. And the result validated the effectiveness of our data-driven strategy.
Gamma: Toward Generic Image Assessment with Mixture of Assessment Experts
Mar 09, 2025

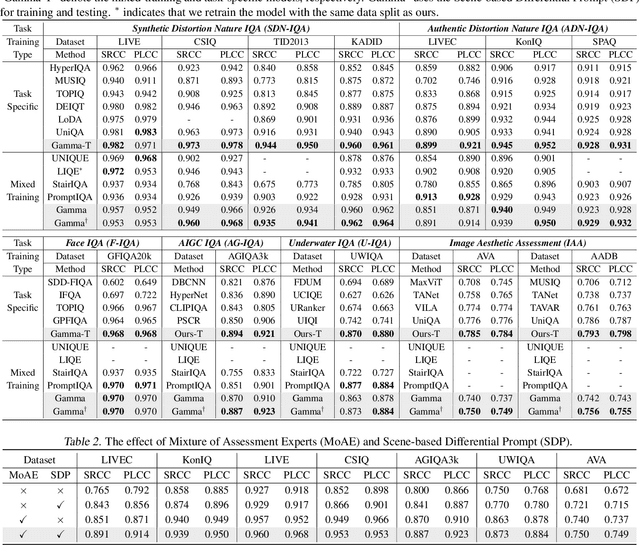

Image assessment aims to evaluate the quality and aesthetics of images and has been applied across various scenarios, such as natural and AIGC scenes. Existing methods mostly address these sub-tasks or scenes individually. While some works attempt to develop unified image assessment models, they have struggled to achieve satisfactory performance or cover a broad spectrum of assessment scenarios. In this paper, we present \textbf{Gamma}, a \textbf{G}eneric im\textbf{A}ge assess\textbf{M}ent model using \textbf{M}ixture of \textbf{A}ssessment Experts, which can effectively assess images from diverse scenes through mixed-dataset training. Achieving unified training in image assessment presents significant challenges due to annotation biases across different datasets. To address this issue, we first propose a Mixture of Assessment Experts (MoAE) module, which employs shared and adaptive experts to dynamically learn common and specific knowledge for different datasets, respectively. In addition, we introduce a Scene-based Differential Prompt (SDP) strategy, which uses scene-specific prompts to provide prior knowledge and guidance during the learning process, further boosting adaptation for various scenes. Our Gamma model is trained and evaluated on 12 datasets spanning 6 image assessment scenarios. Extensive experiments show that our unified Gamma outperforms other state-of-the-art mixed-training methods by significant margins while covering more scenes. Code: https://github.com/zht8506/Gamma.
Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models
Jul 07, 2024
This study addresses the Domain-Class Incremental Learning problem, a realistic but challenging continual learning scenario where both the domain distribution and target classes vary across tasks. To handle these diverse tasks, pre-trained Vision-Language Models (VLMs) are introduced for their strong generalizability. However, this incurs a new problem: the knowledge encoded in the pre-trained VLMs may be disturbed when adapting to new tasks, compromising their inherent zero-shot ability. Existing methods tackle it by tuning VLMs with knowledge distillation on extra datasets, which demands heavy computation overhead. To address this problem efficiently, we propose the Distribution-aware Interference-free Knowledge Integration (DIKI) framework, retaining pre-trained knowledge of VLMs from a perspective of avoiding information interference. Specifically, we design a fully residual mechanism to infuse newly learned knowledge into a frozen backbone, while introducing minimal adverse impacts on pre-trained knowledge. Besides, this residual property enables our distribution-aware integration calibration scheme, explicitly controlling the information implantation process for test data from unseen distributions. Experiments demonstrate that our DIKI surpasses the current state-of-the-art approach using only 0.86% of the trained parameters and requiring substantially less training time. Code is available at: https://github.com/lloongx/DIKI .
RoboGolf: Mastering Real-World Minigolf with a Reflective Multi-Modality Vision-Language Model
Jun 14, 2024Minigolf, a game with countless court layouts, and complex ball motion, constitutes a compelling real-world testbed for the study of embodied intelligence. As it not only challenges spatial and kinodynamic reasoning but also requires reflective and corrective capacities to address erroneously designed courses. We introduce RoboGolf, a framework that perceives dual-camera visual inputs with nested VLM-empowered closed-loop control and reflective equilibrium loop. Extensive experiments demonstrate the effectiveness of RoboGolf on challenging minigolf courts including those that are impossible to finish.
UniQA: Unified Vision-Language Pre-training for Image Quality and Aesthetic Assessment
Jun 03, 2024

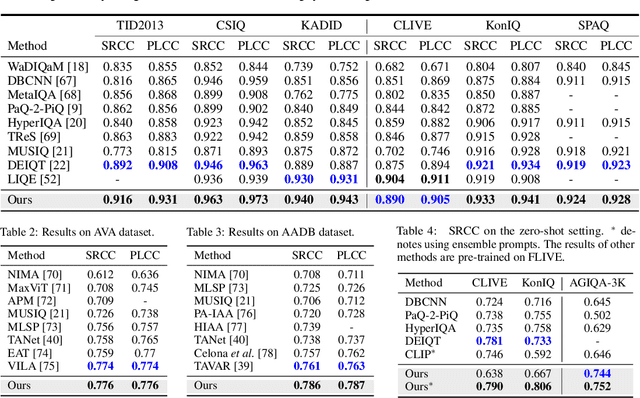

Image Quality Assessment (IQA) and Image Aesthetic Assessment (IAA) aim to simulate human subjective perception of image visual quality and aesthetic appeal. Existing methods typically address these tasks independently due to distinct learning objectives. However, they neglect the underlying interconnectedness of both tasks, which hinders the learning of task-agnostic shared representations for human subjective perception. To confront this challenge, we propose Unified vision-language pre-training of Quality and Aesthetics (UniQA), to learn general perceptions of two tasks, thereby benefiting them simultaneously. Addressing the absence of text in the IQA datasets and the presence of textual noise in the IAA datasets, (1) we utilize multimodal large language models (MLLMs) to generate high-quality text descriptions; (2) the generated text for IAA serves as metadata to purify noisy IAA data. To effectively adapt the pre-trained UniQA to downstream tasks, we further propose a lightweight adapter that utilizes versatile cues to fully exploit the extensive knowledge of the pre-trained model. Extensive experiments demonstrate that our approach attains a new state-of-the-art performance on both IQA and IAA tasks, while concurrently showcasing exceptional zero-shot and few-label image assessment capabilities. The source code will be available at https://github.com/zht8506/UniQA.
Video Object Segmentation with Dynamic Query Modulation
Mar 18, 2024
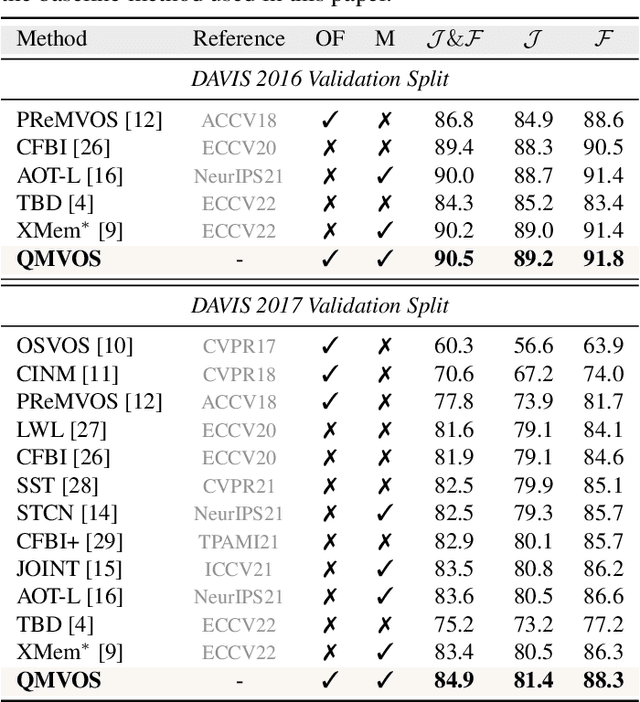


Storing intermediate frame segmentations as memory for long-range context modeling, spatial-temporal memory-based methods have recently showcased impressive results in semi-supervised video object segmentation (SVOS). However, these methods face two key limitations: 1) relying on non-local pixel-level matching to read memory, resulting in noisy retrieved features for segmentation; 2) segmenting each object independently without interaction. These shortcomings make the memory-based methods struggle in similar object and multi-object segmentation. To address these issues, we propose a query modulation method, termed QMVOS. This method summarizes object features into dynamic queries and then treats them as dynamic filters for mask prediction, thereby providing high-level descriptions and object-level perception for the model. Efficient and effective multi-object interactions are realized through inter-query attention. Extensive experiments demonstrate that our method can bring significant improvements to the memory-based SVOS method and achieve competitive performance on standard SVOS benchmarks. The code is available at https://github.com/zht8506/QMVOS.
UniHead: Unifying Multi-Perception for Detection Heads
Sep 23, 2023



The detection head constitutes a pivotal component within object detectors, tasked with executing both classification and localization functions. Regrettably, the commonly used parallel head often lacks omni perceptual capabilities, such as deformation perception, global perception and cross-task perception. Despite numerous methods attempt to enhance these abilities from a single aspect, achieving a comprehensive and unified solution remains a significant challenge. In response to this challenge, we have developed an innovative detection head, termed UniHead, to unify three perceptual abilities simultaneously. More precisely, our approach (1) introduces deformation perception, enabling the model to adaptively sample object features; (2) proposes a Dual-axial Aggregation Transformer (DAT) to adeptly model long-range dependencies, thereby achieving global perception; and (3) devises a Cross-task Interaction Transformer (CIT) that facilitates interaction between the classification and localization branches, thus aligning the two tasks. As a plug-and-play method, the proposed UniHead can be conveniently integrated with existing detectors. Extensive experiments on the COCO dataset demonstrate that our UniHead can bring significant improvements to many detectors. For instance, the UniHead can obtain +2.7 AP gains in RetinaNet, +2.9 AP gains in FreeAnchor, and +2.1 AP gains in GFL. The code will be publicly available. Code Url: https://github.com/zht8506/UniHead.
SemanticAC: Semantics-Assisted Framework for Audio Classification
Feb 12, 2023



In this paper, we propose SemanticAC, a semantics-assisted framework for Audio Classification to better leverage the semantic information. Unlike conventional audio classification methods that treat class labels as discrete vectors, we employ a language model to extract abundant semantics from labels and optimize the semantic consistency between audio signals and their labels. We verify that simple textual information from labels and advanced pretraining models enable more abundant semantic supervision for better performance. Specifically, we design a text encoder to capture the semantic information from the text extension of labels. Then we map the audio signals to align with the semantics of corresponding class labels via an audio encoder and a similarity calculation module so as to enforce the semantic consistency. Extensive experiments on two audio datasets, ESC-50 and US8K demonstrate that our proposed method consistently outperforms the compared audio classification methods.