 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocateEdit-Bench: A Benchmark for Instruction-Based Editing Localization
Feb 05, 2026Recent advancements in image editing have enabled highly controllable and semantically-aware alteration of visual content, posing unprecedented challenges to manipulation localization. However, existing AI-generated forgery localization methods primarily focus on inpainting-based manipulations, making them ineffective against the latest instruction-based editing paradigms. To bridge this critical gap, we propose LocateEdit-Bench, a large-scale dataset comprising $231$K edited images, designed specifically to benchmark localization methods against instruction-driven image editing. Our dataset incorporates four cutting-edge editing models and covers three common edit types. We conduct a detailed analysis of the dataset and develop two multi-metric evaluation protocols to assess existing localization methods. Our work establishes a foundation to keep pace with the evolving landscape of image editing, thereby facilitating the development of effective methods for future forgery localization. Dataset will be open-sourced upon acceptance.
MeniMV: A Multi-view Benchmark for Meniscus Injury Severity Grading
Dec 20, 2025Precise grading of meniscal horn tears is critical in knee injury diagnosis but remains underexplored in automated MRI analysis. Existing methods often rely on coarse study-level labels or binary classification, lacking localization and severity information. In this paper, we introduce MeniMV, a multi-view benchmark dataset specifically designed for horn-specific meniscus injury grading. MeniMV comprises 3,000 annotated knee MRI exams from 750 patients across three medical centers, providing 6,000 co-registered sagittal and coronal images. Each exam is meticulously annotated with four-tier (grade 0-3) severity labels for both anterior and posterior meniscal horns, verified by chief orthopedic physicians. Notably, MeniMV offers more than double the pathology-labeled data volume of prior datasets while uniquely capturing the dual-view diagnostic context essential in clinical practice. To demonstrate the utility of MeniMV, we benchmark multiple state-of-the-art CNN and Transformer-based models. Our extensive experiments establish strong baselines and highlight challenges in severity grading, providing a valuable foundation for future research in automated musculoskeletal imaging.
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Apr 17, 2025Video Anomaly Detection~(VAD) focuses on identifying anomalies within videos. Supervised methods require an amount of in-domain training data and often struggle to generalize to unseen anomalies. In contrast, training-free methods leverage the intrinsic world knowledge of large language models (LLMs) to detect anomalies but face challenges in localizing fine-grained visual transitions and diverse events. Therefore, we propose EventVAD, an event-aware video anomaly detection framework that combines tailored dynamic graph architectures and multimodal LLMs through temporal-event reasoning. Specifically, EventVAD first employs dynamic spatiotemporal graph modeling with time-decay constraints to capture event-aware video features. Then, it performs adaptive noise filtering and uses signal ratio thresholding to detect event boundaries via unsupervised statistical features. The statistical boundary detection module reduces the complexity of processing long videos for MLLMs and improves their temporal reasoning through event consistency. Finally, it utilizes a hierarchical prompting strategy to guide MLLMs in performing reasoning before determining final decisions. We conducted extensive experiments on the UCF-Crime and XD-Violence datasets. The results demonstrate that EventVAD with a 7B MLLM achieves state-of-the-art (SOTA) in training-free settings, outperforming strong baselines that use 7B or larger MLLMs.
AV-GAN: Attention-Based Varifocal Generative Adversarial Network for Uneven Medical Image Translation
Apr 16, 2024Different types of staining highlight different structures in organs, thereby assisting in diagnosis. However, due to the impossibility of repeated staining, we cannot obtain different types of stained slides of the same tissue area. Translating the slide that is easy to obtain (e.g., H&E) to slides of staining types difficult to obtain (e.g., MT, PAS) is a promising way to solve this problem. However, some regions are closely connected to other regions, and to maintain this connection, they often have complex structures and are difficult to translate, which may lead to wrong translations. In this paper, we propose the Attention-Based Varifocal Generative Adversarial Network (AV-GAN), which solves multiple problems in pathologic image translation tasks, such as uneven translation difficulty in different regions, mutual interference of multiple resolution information, and nuclear deformation. Specifically, we develop an Attention-Based Key Region Selection Module, which can attend to regions with higher translation difficulty. We then develop a Varifocal Module to translate these regions at multiple resolutions. Experimental results show that our proposed AV-GAN outperforms existing image translation methods with two virtual kidney tissue staining tasks and improves FID values by 15.9 and 4.16 respectively in the H&E-MT and H&E-PAS tasks.
Efficient Prompt Tuning of Large Vision-Language Model for Fine-Grained Ship Classification
Mar 13, 2024Fine-grained ship classification in remote sensing (RS-FGSC) poses a significant challenge due to the high similarity between classes and the limited availability of labeled data, limiting the effectiveness of traditional supervised classification methods. Recent advancements in large pre-trained Vision-Language Models (VLMs) have demonstrated impressive capabilities in few-shot or zero-shot learning, particularly in understanding image content. This study delves into harnessing the potential of VLMs to enhance classification accuracy for unseen ship categories, which holds considerable significance in scenarios with restricted data due to cost or privacy constraints. Directly fine-tuning VLMs for RS-FGSC often encounters the challenge of overfitting the seen classes, resulting in suboptimal generalization to unseen classes, which highlights the difficulty in differentiating complex backgrounds and capturing distinct ship features. To address these issues, we introduce a novel prompt tuning technique that employs a hierarchical, multi-granularity prompt design. Our approach integrates remote sensing ship priors through bias terms, learned from a small trainable network. This strategy enhances the model's generalization capabilities while improving its ability to discern intricate backgrounds and learn discriminative ship features. Furthermore, we contribute to the field by introducing a comprehensive dataset, FGSCM-52, significantly expanding existing datasets with more extensive data and detailed annotations for less common ship classes. Extensive experimental evaluations demonstrate the superiority of our proposed method over current state-of-the-art techniques. The source code will be made publicly available.
XIMAGENET-12: An Explainable AI Benchmark Dataset for Model Robustness Evaluation
Oct 12, 2023



The lack of standardized robustness metrics and the widespread reliance on numerous unrelated benchmark datasets for testing have created a gap between academically validated robust models and their often problematic practical adoption. To address this, we introduce XIMAGENET-12, an explainable benchmark dataset with over 200K images and 15,600 manual semantic annotations. Covering 12 categories from ImageNet to represent objects commonly encountered in practical life and simulating six diverse scenarios, including overexposure, blurring, color changing, etc., we further propose a novel robustness criterion that extends beyond model generation ability assessment. This benchmark dataset, along with related code, is available at https://sites.google.com/view/ximagenet-12/home. Researchers and practitioners can leverage this resource to evaluate the robustness of their visual models under challenging conditions and ultimately benefit from the demands of practical computer vision systems.
SOC: Semantic-Assisted Object Cluster for Referring Video Object Segmentation
May 26, 2023

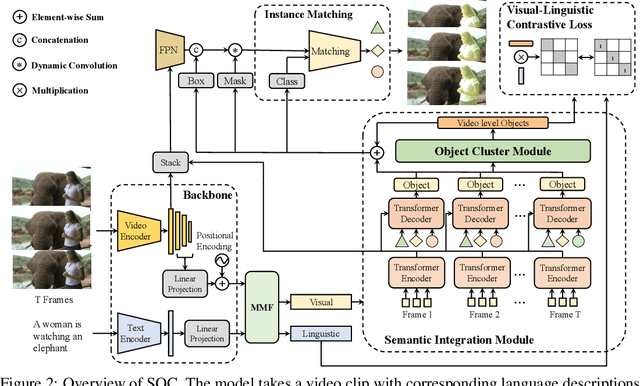

This paper studies referring video object segmentation (RVOS) by boosting video-level visual-linguistic alignment. Recent approaches model the RVOS task as a sequence prediction problem and perform multi-modal interaction as well as segmentation for each frame separately. However, the lack of a global view of video content leads to difficulties in effectively utilizing inter-frame relationships and understanding textual descriptions of object temporal variations. To address this issue, we propose Semantic-assisted Object Cluster (SOC), which aggregates video content and textual guidance for unified temporal modeling and cross-modal alignment. By associating a group of frame-level object embeddings with language tokens, SOC facilitates joint space learning across modalities and time steps. Moreover, we present multi-modal contrastive supervision to help construct well-aligned joint space at the video level. We conduct extensive experiments on popular RVOS benchmarks, and our method outperforms state-of-the-art competitors on all benchmarks by a remarkable margin. Besides, the emphasis on temporal coherence enhances the segmentation stability and adaptability of our method in processing text expressions with temporal variations. Code will be available.
Towards Realizing the Value of Labeled Target Samples: a Two-Stage Approach for Semi-Supervised Domain Adaptation
Apr 21, 2023Semi-Supervised Domain Adaptation (SSDA) is a recently emerging research topic that extends from the widely-investigated Unsupervised Domain Adaptation (UDA) by further having a few target samples labeled, i.e., the model is trained with labeled source samples, unlabeled target samples as well as a few labeled target samples. Compared with UDA, the key to SSDA lies how to most effectively utilize the few labeled target samples. Existing SSDA approaches simply merge the few precious labeled target samples into vast labeled source samples or further align them, which dilutes the value of labeled target samples and thus still obtains a biased model. To remedy this, in this paper, we propose to decouple SSDA as an UDA problem and a semi-supervised learning problem where we first learn an UDA model using labeled source and unlabeled target samples and then adapt the learned UDA model in a semi-supervised way using labeled and unlabeled target samples. By utilizing the labeled source samples and target samples separately, the bias problem can be well mitigated. We further propose a consistency learning based mean teacher model to effectively adapt the learned UDA model using labeled and unlabeled target samples. Experiments show our approach outperforms existing methods.
SSGD: A smartphone screen glass dataset for defect detection
Mar 12, 2023



Interactive devices with touch screen have become commonly used in various aspects of daily life, which raises the demand for high production quality of touch screen glass. While it is desirable to develop effective defect detection technologies to optimize the automatic touch screen production lines, the development of these technologies suffers from the lack of publicly available datasets. To address this issue, we in this paper propose a dedicated touch screen glass defect dataset which includes seven types of defects and consists of 2504 images captured in various scenarios.All data are captured with professional acquisition equipment on the fixed workstation. Additionally, we benchmark the CNN- and Transformer-based object detection frameworks on the proposed dataset to demonstrate the challenges of defect detection on high-resolution images. Dataset and related code will be available at https://github.com/Yangr116/SSGDataset.
SemanticAC: Semantics-Assisted Framework for Audio Classification
Feb 12, 2023



In this paper, we propose SemanticAC, a semantics-assisted framework for Audio Classification to better leverage the semantic information. Unlike conventional audio classification methods that treat class labels as discrete vectors, we employ a language model to extract abundant semantics from labels and optimize the semantic consistency between audio signals and their labels. We verify that simple textual information from labels and advanced pretraining models enable more abundant semantic supervision for better performance. Specifically, we design a text encoder to capture the semantic information from the text extension of labels. Then we map the audio signals to align with the semantics of corresponding class labels via an audio encoder and a similarity calculation module so as to enforce the semantic consistency. Extensive experiments on two audio datasets, ESC-50 and US8K demonstrate that our proposed method consistently outperforms the compared audio classification methods.