 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
End-to-End Vision Tokenizer Tuning
May 15, 2025Existing vision tokenization isolates the optimization of vision tokenizers from downstream training, implicitly assuming the visual tokens can generalize well across various tasks, e.g., image generation and visual question answering. The vision tokenizer optimized for low-level reconstruction is agnostic to downstream tasks requiring varied representations and semantics. This decoupled paradigm introduces a critical misalignment: The loss of the vision tokenization can be the representation bottleneck for target tasks. For example, errors in tokenizing text in a given image lead to poor results when recognizing or generating them. To address this, we propose ETT, an end-to-end vision tokenizer tuning approach that enables joint optimization between vision tokenization and target autoregressive tasks. Unlike prior autoregressive models that use only discrete indices from a frozen vision tokenizer, ETT leverages the visual embeddings of the tokenizer codebook, and optimizes the vision tokenizers end-to-end with both reconstruction and caption objectives. ETT can be seamlessly integrated into existing training pipelines with minimal architecture modifications. Our ETT is simple to implement and integrate, without the need to adjust the original codebooks or architectures of the employed large language models. Extensive experiments demonstrate that our proposed end-to-end vision tokenizer tuning unlocks significant performance gains, i.e., 2-6% for multimodal understanding and visual generation tasks compared to frozen tokenizer baselines, while preserving the original reconstruction capability. We hope this very simple and strong method can empower multimodal foundation models besides image generation and understanding.
Taming Scalable Visual Tokenizer for Autoregressive Image Generation
Dec 03, 2024



Existing vector quantization (VQ) methods struggle with scalability, largely attributed to the instability of the codebook that undergoes partial updates during training. The codebook is prone to collapse as utilization decreases, due to the progressively widening distribution gap between non-activated codes and visual features. To solve the problem, we propose Index Backpropagation Quantization (IBQ), a new VQ method for the joint optimization of all codebook embeddings and the visual encoder. Applying a straight-through estimator on the one-hot categorical distribution between the encoded feature and codebook, all codes are differentiable and maintain a consistent latent space with the visual encoder. IBQ enables scalable training of visual tokenizers and, for the first time, achieves a large-scale codebook ($2^{18}$) with high dimension ($256$) and high utilization. Experiments on the standard ImageNet benchmark demonstrate the scalability and superiority of IBQ, achieving competitive results on both reconstruction ($1.00$ rFID) and autoregressive visual generation ($2.05$ gFID). The code and models are available at https://github.com/TencentARC/SEED-Voken.
Open-MAGVIT2: An Open-Source Project Toward Democratizing Auto-regressive Visual Generation
Sep 06, 2024We present Open-MAGVIT2, a family of auto-regressive image generation models ranging from 300M to 1.5B. The Open-MAGVIT2 project produces an open-source replication of Google's MAGVIT-v2 tokenizer, a tokenizer with a super-large codebook (i.e., $2^{18}$ codes), and achieves the state-of-the-art reconstruction performance (1.17 rFID) on ImageNet $256 \times 256$. Furthermore, we explore its application in plain auto-regressive models and validate scalability properties. To assist auto-regressive models in predicting with a super-large vocabulary, we factorize it into two sub-vocabulary of different sizes by asymmetric token factorization, and further introduce "next sub-token prediction" to enhance sub-token interaction for better generation quality. We release all models and codes to foster innovation and creativity in the field of auto-regressive visual generation.
HDC: Hierarchical Semantic Decoding with Counting Assistance for Generalized Referring Expression Segmentation
May 24, 2024



The newly proposed Generalized Referring Expression Segmentation (GRES) amplifies the formulation of classic RES by involving multiple/non-target scenarios. Recent approaches focus on optimizing the last modality-fused feature which is directly utilized for segmentation and object-existence identification. However, the attempt to integrate all-grained information into a single joint representation is impractical in GRES due to the increased complexity of the spatial relationships among instances and deceptive text descriptions. Furthermore, the subsequent binary target justification across all referent scenarios fails to specify their inherent differences, leading to ambiguity in object understanding. To address the weakness, we propose a $\textbf{H}$ierarchical Semantic $\textbf{D}$ecoding with $\textbf{C}$ounting Assistance framework (HDC). It hierarchically transfers complementary modality information across granularities, and then aggregates each well-aligned semantic correspondence for multi-level decoding. Moreover, with complete semantic context modeling, we endow HDC with explicit counting capability to facilitate comprehensive object perception in multiple/single/non-target settings. Experimental results on gRefCOCO, Ref-ZOM, R-RefCOCO, and RefCOCO benchmarks demonstrate the effectiveness and rationality of HDC which outperforms the state-of-the-art GRES methods by a remarkable margin. Code will be available $\href{https://github.com/RobertLuo1/HDC}{here}$.
1st Place Solution for 5th LSVOS Challenge: Referring Video Object Segmentation
Jan 01, 2024


The recent transformer-based models have dominated the Referring Video Object Segmentation (RVOS) task due to the superior performance. Most prior works adopt unified DETR framework to generate segmentation masks in query-to-instance manner. In this work, we integrate strengths of that leading RVOS models to build up an effective paradigm. We first obtain binary mask sequences from the RVOS models. To improve the consistency and quality of masks, we propose Two-Stage Multi-Model Fusion strategy. Each stage rationally ensembles RVOS models based on framework design as well as training strategy, and leverages different video object segmentation (VOS) models to enhance mask coherence by object propagation mechanism. Our method achieves 75.7% J&F on Ref-Youtube-VOS validation set and 70% J&F on test set, which ranks 1st place on 5th Large-scale Video Object Segmentation Challenge (ICCV 2023) track 3. Code is available at https://github.com/RobertLuo1/iccv2023_RVOS_Challenge.
Bridging the Gap: A Unified Video Comprehension Framework for Moment Retrieval and Highlight Detection
Nov 28, 2023Video Moment Retrieval (MR) and Highlight Detection (HD) have attracted significant attention due to the growing demand for video analysis. Recent approaches treat MR and HD as similar video grounding problems and address them together with transformer-based architecture. However, we observe that the emphasis of MR and HD differs, with one necessitating the perception of local relationships and the other prioritizing the understanding of global contexts. Consequently, the lack of task-specific design will inevitably lead to limitations in associating the intrinsic specialty of two tasks. To tackle the issue, we propose a Unified Video COMprehension framework (UVCOM) to bridge the gap and jointly solve MR and HD effectively. By performing progressive integration on intra and inter-modality across multi-granularity, UVCOM achieves the comprehensive understanding in processing a video. Moreover, we present multi-aspect contrastive learning to consolidate the local relation modeling and global knowledge accumulation via well aligned multi-modal space. Extensive experiments on QVHighlights, Charades-STA, TACoS , YouTube Highlights and TVSum datasets demonstrate the effectiveness and rationality of UVCOM which outperforms the state-of-the-art methods by a remarkable margin.
SOC: Semantic-Assisted Object Cluster for Referring Video Object Segmentation
May 26, 2023

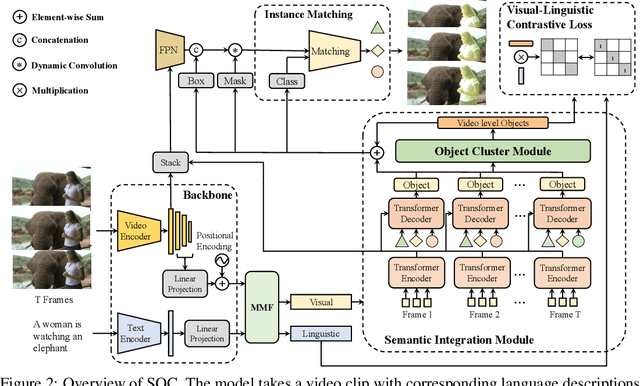

This paper studies referring video object segmentation (RVOS) by boosting video-level visual-linguistic alignment. Recent approaches model the RVOS task as a sequence prediction problem and perform multi-modal interaction as well as segmentation for each frame separately. However, the lack of a global view of video content leads to difficulties in effectively utilizing inter-frame relationships and understanding textual descriptions of object temporal variations. To address this issue, we propose Semantic-assisted Object Cluster (SOC), which aggregates video content and textual guidance for unified temporal modeling and cross-modal alignment. By associating a group of frame-level object embeddings with language tokens, SOC facilitates joint space learning across modalities and time steps. Moreover, we present multi-modal contrastive supervision to help construct well-aligned joint space at the video level. We conduct extensive experiments on popular RVOS benchmarks, and our method outperforms state-of-the-art competitors on all benchmarks by a remarkable margin. Besides, the emphasis on temporal coherence enhances the segmentation stability and adaptability of our method in processing text expressions with temporal variations. Code will be available.