 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs
Dec 16, 2025This paper does not introduce a novel method but instead establishes a straightforward, incremental, yet essential baseline for video temporal grounding (VTG), a core capability in video understanding. While multimodal large language models (MLLMs) excel at various video understanding tasks, the recipes for optimizing them for VTG remain under-explored. In this paper, we present TimeLens, a systematic investigation into building MLLMs with strong VTG ability, along two primary dimensions: data quality and algorithmic design. We first expose critical quality issues in existing VTG benchmarks and introduce TimeLens-Bench, comprising meticulously re-annotated versions of three popular benchmarks with strict quality criteria. Our analysis reveals dramatic model re-rankings compared to legacy benchmarks, confirming the unreliability of prior evaluation standards. We also address noisy training data through an automated re-annotation pipeline, yielding TimeLens-100K, a large-scale, high-quality training dataset. Building on our data foundation, we conduct in-depth explorations of algorithmic design principles, yielding a series of meaningful insights and effective yet efficient practices. These include interleaved textual encoding for time representation, a thinking-free reinforcement learning with verifiable rewards (RLVR) approach as the training paradigm, and carefully designed recipes for RLVR training. These efforts culminate in TimeLens models, a family of MLLMs with state-of-the-art VTG performance among open-source models and even surpass proprietary models such as GPT-5 and Gemini-2.5-Flash. All codes, data, and models will be released to facilitate future research.
ARC-Chapter: Structuring Hour-Long Videos into Navigable Chapters and Hierarchical Summaries
Nov 18, 2025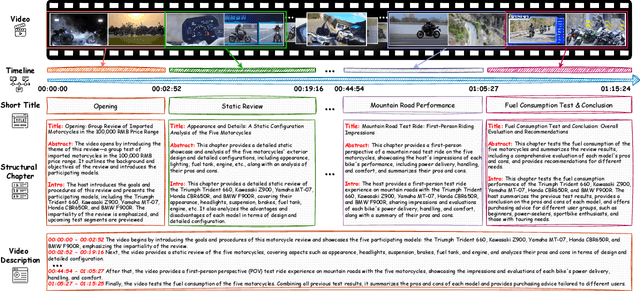
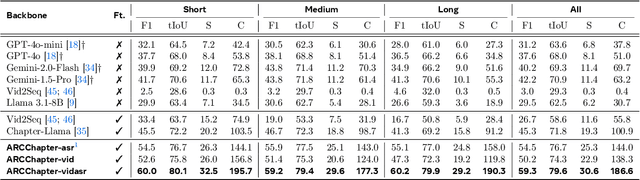
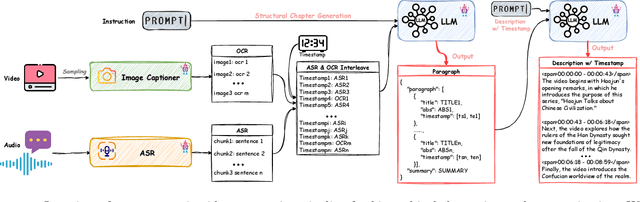
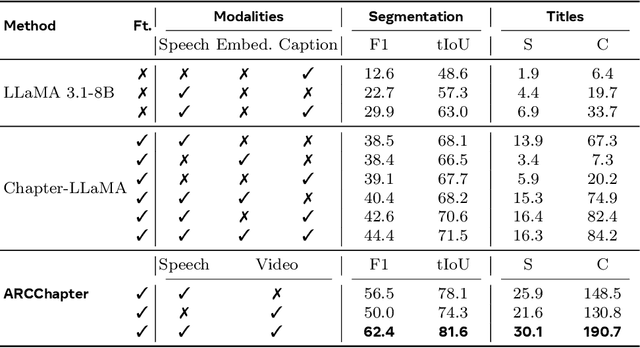
The proliferation of hour-long videos (e.g., lectures, podcasts, documentaries) has intensified demand for efficient content structuring. However, existing approaches are constrained by small-scale training with annotations that are typical short and coarse, restricting generalization to nuanced transitions in long videos. We introduce ARC-Chapter, the first large-scale video chaptering model trained on over million-level long video chapters, featuring bilingual, temporally grounded, and hierarchical chapter annotations. To achieve this goal, we curated a bilingual English-Chinese chapter dataset via a structured pipeline that unifies ASR transcripts, scene texts, visual captions into multi-level annotations, from short title to long summaries. We demonstrate clear performance improvements with data scaling, both in data volume and label intensity. Moreover, we design a new evaluation metric termed GRACE, which incorporates many-to-one segment overlaps and semantic similarity, better reflecting real-world chaptering flexibility. Extensive experiments demonstrate that ARC-Chapter establishes a new state-of-the-art by a significant margin, outperforming the previous best by 14.0% in F1 score and 11.3% in SODA score. Moreover, ARC-Chapter shows excellent transferability, improving the state-of-the-art on downstream tasks like dense video captioning on YouCook2.
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
Aug 27, 2025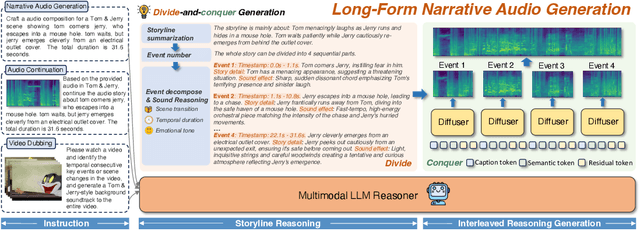
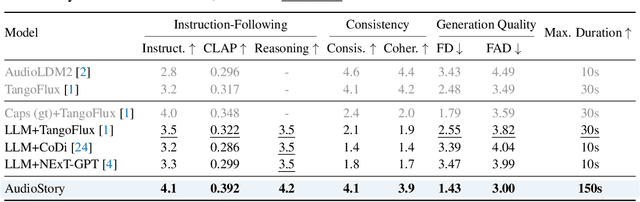
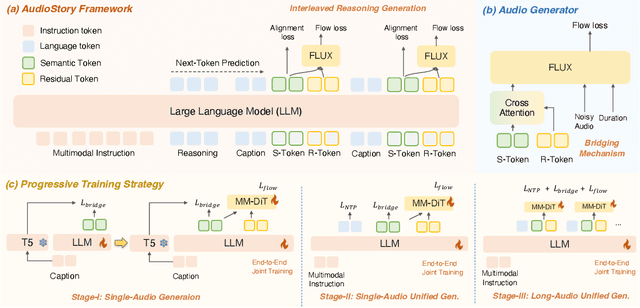

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features: (1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components, i.e., a bridging query for intra-event semantic alignment and a residual query for cross-event coherence preservation. (2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components. Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives. Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity. Our code is available at https://github.com/TencentARC/AudioStory
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025



Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.
Aligning Latent Spaces with Flow Priors
Jun 05, 2025This paper presents a novel framework for aligning learnable latent spaces to arbitrary target distributions by leveraging flow-based generative models as priors. Our method first pretrains a flow model on the target features to capture the underlying distribution. This fixed flow model subsequently regularizes the latent space via an alignment loss, which reformulates the flow matching objective to treat the latents as optimization targets. We formally prove that minimizing this alignment loss establishes a computationally tractable surrogate objective for maximizing a variational lower bound on the log-likelihood of latents under the target distribution. Notably, the proposed method eliminates computationally expensive likelihood evaluations and avoids ODE solving during optimization. As a proof of concept, we demonstrate in a controlled setting that the alignment loss landscape closely approximates the negative log-likelihood of the target distribution. We further validate the effectiveness of our approach through large-scale image generation experiments on ImageNet with diverse target distributions, accompanied by detailed discussions and ablation studies. With both theoretical and empirical validation, our framework paves a new way for latent space alignment.
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
May 27, 2025Recent advances in CoT reasoning and RL post-training have been reported to enhance video reasoning capabilities of MLLMs. This progress naturally raises a question: can these models perform complex video reasoning in a manner comparable to human experts? However, existing video benchmarks primarily evaluate visual perception and grounding abilities, with questions that can be answered based on explicit prompts or isolated visual cues. Such benchmarks do not fully capture the intricacies of real-world reasoning, where humans must actively search for, integrate, and analyze multiple clues before reaching a conclusion. To address this issue, we present Video-Holmes, a benchmark inspired by the reasoning process of Sherlock Holmes, designed to evaluate the complex video reasoning capabilities of MLLMs. Video-Holmes consists of 1,837 questions derived from 270 manually annotated suspense short films, which spans seven carefully designed tasks. Each task is constructed by first identifying key events and causal relationships within films, and then designing questions that require models to actively locate and connect multiple relevant visual clues scattered across different video segments. Our comprehensive evaluation of state-of-the-art MLLMs reveals that, while these models generally excel at visual perception, they encounter substantial difficulties with integrating information and often miss critical clues. For example, the best-performing model, Gemini-2.5-Pro, achieves an accuracy of only 45%, with most models scoring below 40%. We aim that Video-Holmes can serve as a "Holmes-test" for multimodal reasoning, motivating models to reason more like humans and emphasizing the ongoing challenges in this field. The benchmark is released in https://github.com/TencentARC/Video-Holmes.
TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation
May 08, 2025Pioneering token-based works such as Chameleon and Emu3 have established a foundation for multimodal unification but face challenges of high training computational overhead and limited comprehension performance due to a lack of high-level semantics. In this paper, we introduce TokLIP, a visual tokenizer that enhances comprehension by semanticizing vector-quantized (VQ) tokens and incorporating CLIP-level semantics while enabling end-to-end multimodal autoregressive training with standard VQ tokens. TokLIP integrates a low-level discrete VQ tokenizer with a ViT-based token encoder to capture high-level continuous semantics. Unlike previous approaches (e.g., VILA-U) that discretize high-level features, TokLIP disentangles training objectives for comprehension and generation, allowing the direct application of advanced VQ tokenizers without the need for tailored quantization operations. Our empirical results demonstrate that TokLIP achieves exceptional data efficiency, empowering visual tokens with high-level semantic understanding while enhancing low-level generative capacity, making it well-suited for autoregressive Transformers in both comprehension and generation tasks. The code and models are available at https://github.com/TencentARC/TokLIP.
AnimeGamer: Infinite Anime Life Simulation with Next Game State Prediction
Apr 01, 2025Recent advancements in image and video synthesis have opened up new promise in generative games. One particularly intriguing application is transforming characters from anime films into interactive, playable entities. This allows players to immerse themselves in the dynamic anime world as their favorite characters for life simulation through language instructions. Such games are defined as infinite game since they eliminate predetermined boundaries and fixed gameplay rules, where players can interact with the game world through open-ended language and experience ever-evolving storylines and environments. Recently, a pioneering approach for infinite anime life simulation employs large language models (LLMs) to translate multi-turn text dialogues into language instructions for image generation. However, it neglects historical visual context, leading to inconsistent gameplay. Furthermore, it only generates static images, failing to incorporate the dynamics necessary for an engaging gaming experience. In this work, we propose AnimeGamer, which is built upon Multimodal Large Language Models (MLLMs) to generate each game state, including dynamic animation shots that depict character movements and updates to character states, as illustrated in Figure 1. We introduce novel action-aware multimodal representations to represent animation shots, which can be decoded into high-quality video clips using a video diffusion model. By taking historical animation shot representations as context and predicting subsequent representations, AnimeGamer can generate games with contextual consistency and satisfactory dynamics. Extensive evaluations using both automated metrics and human evaluations demonstrate that AnimeGamer outperforms existing methods in various aspects of the gaming experience. Codes and checkpoints are available at https://github.com/TencentARC/AnimeGamer.
Exploring the Effect of Reinforcement Learning on Video Understanding: Insights from SEED-Bench-R1
Mar 31, 2025



Recent advancements in Chain of Thought (COT) generation have significantly improved the reasoning capabilities of Large Language Models (LLMs), with reinforcement learning (RL) emerging as an effective post-training approach. Multimodal Large Language Models (MLLMs) inherit this reasoning potential but remain underexplored in tasks requiring both perception and logical reasoning. To address this, we introduce SEED-Bench-R1, a benchmark designed to systematically evaluate post-training methods for MLLMs in video understanding. It includes intricate real-world videos and complex everyday planning tasks in the format of multiple-choice questions, requiring sophisticated perception and reasoning. SEED-Bench-R1 assesses generalization through a three-level hierarchy: in-distribution, cross-environment, and cross-environment-task scenarios, equipped with a large-scale training dataset with easily verifiable ground-truth answers. Using Qwen2-VL-Instruct-7B as a base model, we compare RL with supervised fine-tuning (SFT), demonstrating RL's data efficiency and superior performance on both in-distribution and out-of-distribution tasks, even outperforming SFT on general video understanding benchmarks like LongVideoBench. Our detailed analysis reveals that RL enhances visual perception but often produces less logically coherent reasoning chains. We identify key limitations such as inconsistent reasoning and overlooked visual cues, and suggest future improvements in base model reasoning, reward modeling, and RL robustness against noisy signals.