 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reasoning Hop Exposes Weaknesses: Demystifying and Improving Hop Generalization in Large Language Models
Jan 29, 2026Chain-of-thought (CoT) reasoning has become the standard paradigm for enabling Large Language Models (LLMs) to solve complex problems. However, recent studies reveal a sharp performance drop in reasoning hop generalization scenarios, where the required number of reasoning steps exceeds training distributions while the underlying algorithm remains unchanged. The internal mechanisms driving this failure remain poorly understood. In this work, we conduct a systematic study on tasks from multiple domains, and find that errors concentrate at token positions of a few critical error types, rather than being uniformly distributed. Closer inspection reveals that these token-level erroneous predictions stem from internal competition mechanisms: certain attention heads, termed erroneous processing heads (ep heads), tip the balance by amplifying incorrect reasoning trajectories while suppressing correct ones. Notably, removing individual ep heads during inference can often restore the correct predictions. Motivated by these insights, we propose test-time correction of reasoning, a lightweight intervention method that dynamically identifies and deactivates ep heads in the reasoning process. Extensive experiments across different tasks and LLMs show that it consistently improves reasoning hop generalization, highlighting both its effectiveness and potential.
Improving Alignment in LVLMs with Debiased Self-Judgment
Aug 28, 2025



The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations--where generated outputs are not grounded in the visual input--and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
AVFSNet: Audio-Visual Speech Separation for Flexible Number of Speakers with Multi-Scale and Multi-Task Learning
Jul 17, 2025Separating target speech from mixed signals containing flexible speaker quantities presents a challenging task. While existing methods demonstrate strong separation performance and noise robustness, they predominantly assume prior knowledge of speaker counts in mixtures. The limited research addressing unknown speaker quantity scenarios exhibits significantly constrained generalization capabilities in real acoustic environments. To overcome these challenges, this paper proposes AVFSNet -- an audio-visual speech separation model integrating multi-scale encoding and parallel architecture -- jointly optimized for speaker counting and multi-speaker separation tasks. The model independently separates each speaker in parallel while enhancing environmental noise adaptability through visual information integration. Comprehensive experimental evaluations demonstrate that AVFSNet achieves state-of-the-art results across multiple evaluation metrics and delivers outstanding performance on diverse datasets.
Automatic Expert Discovery in LLM Upcycling via Sparse Interpolated Mixture-of-Experts
Jun 14, 2025We present Sparse Interpolated Mixture-of-Experts (SIMoE) instruction-tuning, an end-to-end algorithm designed to fine-tune a dense pre-trained Large Language Model (LLM) into a MoE-style model that possesses capabilities in multiple specialized domains. During instruction-tuning, SIMoE automatically identifies multiple specialized experts under a specified sparsity constraint, with each expert representing a structurally sparse subset of the seed LLM's parameters that correspond to domain-specific knowledge within the data. SIMoE simultaneously learns an input-dependent expert merging strategy via a router network, leveraging rich cross-expert knowledge for superior downstream generalization that surpasses existing baselines. Empirically, SIMoE consistently achieves state-of-the-art performance on common instruction-tuning benchmarks while maintaining an optimal performance-compute trade-off compared to all baselines.
Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
Jun 06, 2025Low-rank adaptation (LoRA) has emerged as a leading parameter-efficient fine-tuning technique for adapting large foundation models, yet it often locks adapters into suboptimal minima near their initialization. This hampers model generalization and limits downstream operators such as adapter merging and pruning. Here, we propose CoTo, a progressive training strategy that gradually increases adapters' activation probability over the course of fine-tuning. By stochastically deactivating adapters, CoTo encourages more balanced optimization and broader exploration of the loss landscape. We provide a theoretical analysis showing that CoTo promotes layer-wise dropout stability and linear mode connectivity, and we adopt a cooperative-game approach to quantify each adapter's marginal contribution. Extensive experiments demonstrate that CoTo consistently boosts single-task performance, enhances multi-task merging accuracy, improves pruning robustness, and reduces training overhead, all while remaining compatible with diverse LoRA variants. Code is available at https://github.com/zwebzone/coto.
What Makes a Good Reasoning Chain? Uncovering Structural Patterns in Long Chain-of-Thought Reasoning
May 28, 2025



Recent advances in reasoning with large language models (LLMs) have popularized Long Chain-of-Thought (LCoT), a strategy that encourages deliberate and step-by-step reasoning before producing a final answer. While LCoTs have enabled expert-level performance in complex tasks, how the internal structures of their reasoning chains drive, or even predict, the correctness of final answers remains a critical yet underexplored question. In this work, we present LCoT2Tree, an automated framework that converts sequential LCoTs into hierarchical tree structures and thus enables deeper structural analysis of LLM reasoning. Using graph neural networks (GNNs), we reveal that structural patterns extracted by LCoT2Tree, including exploration, backtracking, and verification, serve as stronger predictors of final performance across a wide range of tasks and models. Leveraging an explainability technique, we further identify critical thought patterns such as over-branching that account for failures. Beyond diagnostic insights, the structural patterns by LCoT2Tree support practical applications, including improving Best-of-N decoding effectiveness. Overall, our results underscore the critical role of internal structures of reasoning chains, positioning LCoT2Tree as a powerful tool for diagnosing, interpreting, and improving reasoning in LLMs.
Mixture of Low Rank Adaptation with Partial Parameter Sharing for Time Series Forecasting
May 23, 2025Multi-task forecasting has become the standard approach for time-series forecasting (TSF). However, we show that it suffers from an Expressiveness Bottleneck, where predictions at different time steps share the same representation, leading to unavoidable errors even with optimal representations. To address this issue, we propose a two-stage framework: first, pre-train a foundation model for one-step-ahead prediction; then, adapt it using step-specific LoRA modules.This design enables the foundation model to handle any number of forecast steps while avoiding the expressiveness bottleneck. We further introduce the Mixture-of-LoRA (MoLA) model, which employs adaptively weighted LoRA experts to achieve partial parameter sharing across steps. This approach enhances both efficiency and forecasting performance by exploiting interdependencies between forecast steps. Experiments show that MoLA significantly improves model expressiveness and outperforms state-of-the-art time-series forecasting methods. Code is available at https://anonymous.4open.science/r/MoLA-BC92.
TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation
May 08, 2025Pioneering token-based works such as Chameleon and Emu3 have established a foundation for multimodal unification but face challenges of high training computational overhead and limited comprehension performance due to a lack of high-level semantics. In this paper, we introduce TokLIP, a visual tokenizer that enhances comprehension by semanticizing vector-quantized (VQ) tokens and incorporating CLIP-level semantics while enabling end-to-end multimodal autoregressive training with standard VQ tokens. TokLIP integrates a low-level discrete VQ tokenizer with a ViT-based token encoder to capture high-level continuous semantics. Unlike previous approaches (e.g., VILA-U) that discretize high-level features, TokLIP disentangles training objectives for comprehension and generation, allowing the direct application of advanced VQ tokenizers without the need for tailored quantization operations. Our empirical results demonstrate that TokLIP achieves exceptional data efficiency, empowering visual tokens with high-level semantic understanding while enhancing low-level generative capacity, making it well-suited for autoregressive Transformers in both comprehension and generation tasks. The code and models are available at https://github.com/TencentARC/TokLIP.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025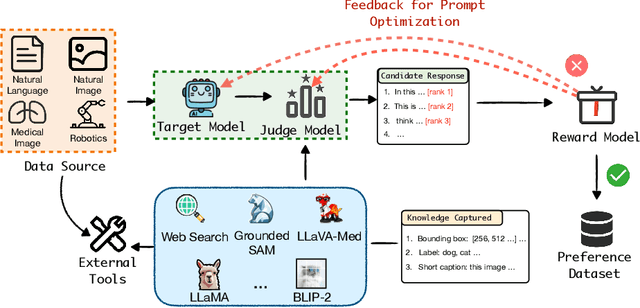
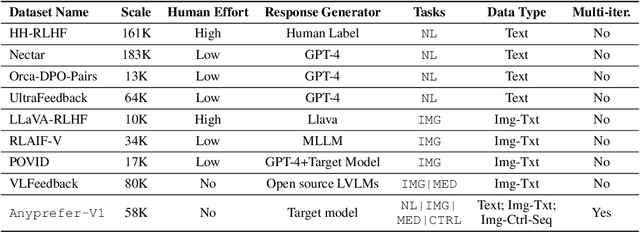
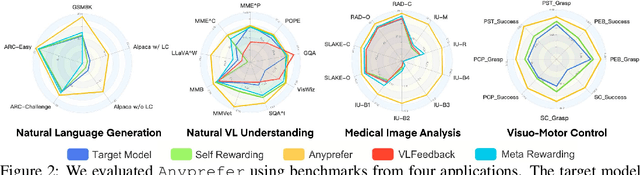
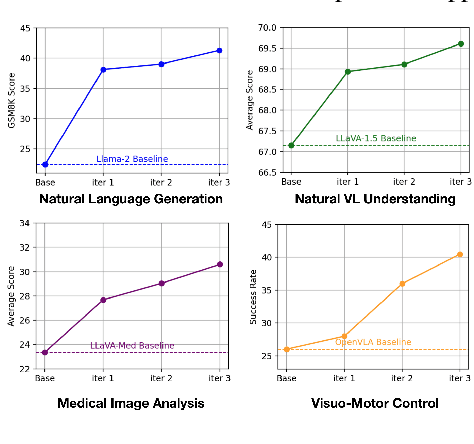
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.