 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROMAS: A Role-Based Multi-Agent System for Database monitoring and Planning
Dec 18, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in data analytics when integrated with Multi-Agent Systems (MAS). However, these systems often struggle with complex tasks that involve diverse functional requirements and intricate data processing challenges, necessitating customized solutions that lack broad applicability. Furthermore, current MAS fail to emulate essential human-like traits such as self-planning, self-monitoring, and collaborative work in dynamic environments, leading to inefficiencies and resource wastage. To address these limitations, we propose ROMAS, a novel Role-Based M ulti-A gent System designed to adapt to various scenarios while enabling low code development and one-click deployment. ROMAS has been effectively deployed in DB-GPT [Xue et al., 2023a, 2024b], a well-known project utilizing LLM-powered database analytics, showcasing its practical utility in real-world scenarios. By integrating role-based collaborative mechanisms for self-monitoring and self-planning, and leveraging existing MAS capabilities to enhance database interactions, ROMAS offers a more effective and versatile solution. Experimental evaluations of ROMAS demonstrate its superiority across multiple scenarios, highlighting its potential to advance the field of multi-agent data analytics.
LLMOPT: Learning to Define and Solve General Optimization Problems from Scratch
Oct 17, 2024



Optimization problems are prevalent across various scenarios. Formulating and then solving optimization problems described by natural language often requires highly specialized human expertise, which could block the widespread application of optimization-based decision making. To make problem formulating and solving automated, leveraging large language models (LLMs) has emerged as a potential way. However, this kind of way suffers from the issue of optimization generalization. Namely, the accuracy of most current LLM-based methods and the generality of optimization problem types that they can model are still limited. In this paper, we propose a unified learning-based framework called LLMOPT to boost optimization generalization. Starting from the natural language descriptions of optimization problems and a pre-trained LLM, LLMOPT constructs the introduced five-element formulation as a universal model for learning to define diverse optimization problem types. Then, LLMOPT employs the multi-instruction tuning to enhance both problem formalization and solver code generation accuracy and generality. After that, to prevent hallucinations in LLMs, such as sacrificing solving accuracy to avoid execution errors, model alignment and self-correction mechanism are adopted in LLMOPT. We evaluate the optimization generalization ability of LLMOPT and compared methods across six real-world datasets covering roughly 20 fields such as health, environment, energy and manufacturing, etc. Extensive experiment results show that LLMOPT is able to model various optimization problem types such as linear/nonlinear programming, mixed integer programming and combinatorial optimization, and achieves a notable 11.08% average solving accuracy improvement compared with the state-of-the-art methods. The code is available at https://github.com/caigaojiang/LLMOPT.
Interpretable Catastrophic Forgetting of Large Language Model Fine-tuning via Instruction Vector
Jun 18, 2024



Fine-tuning large language models (LLMs) can cause them to lose their general capabilities. However, the intrinsic mechanisms behind such forgetting remain unexplored. In this paper, we begin by examining this phenomenon by focusing on knowledge understanding and instruction following, with the latter identified as the main contributor to forgetting during fine-tuning. Consequently, we propose the Instruction Vector (IV) framework to capture model representations highly related to specific instruction-following capabilities, thereby making it possible to understand model-intrinsic forgetting. Through the analysis of IV dynamics pre and post-training, we suggest that fine-tuning mostly adds specialized reasoning patterns instead of erasing previous skills, which may appear as forgetting. Building on this insight, we develop IV-guided training, which aims to preserve original computation graph, thereby mitigating catastrophic forgetting. Empirical tests on three benchmarks confirm the efficacy of this new approach, supporting the relationship between IVs and forgetting. Our code will be made available soon.
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024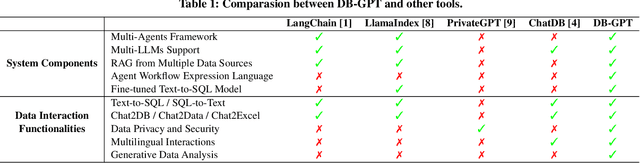
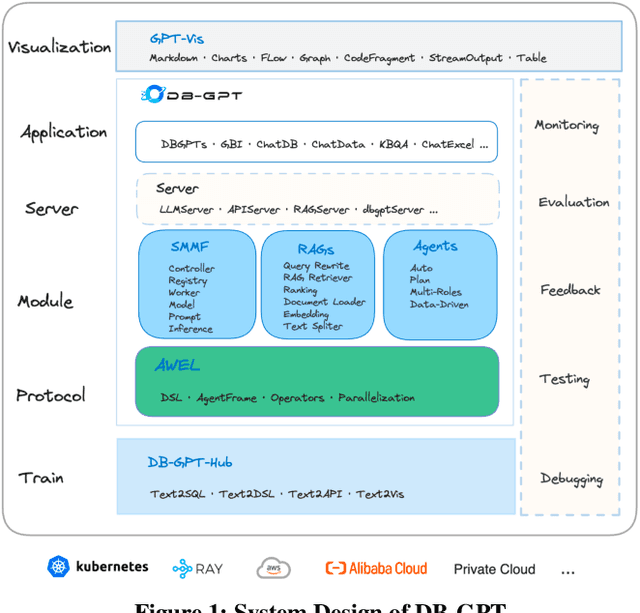

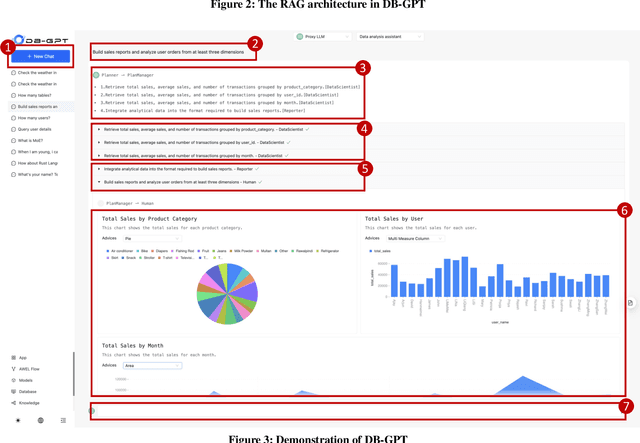
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
Towards Anytime Fine-tuning: Continually Pre-trained Language Models with Hypernetwork Prompt
Oct 19, 2023


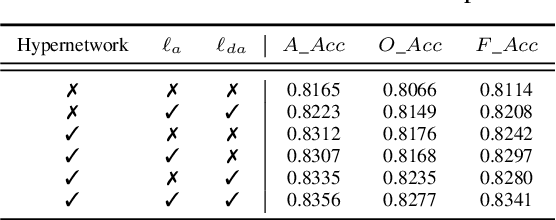
Continual pre-training has been urgent for adapting a pre-trained model to a multitude of domains and tasks in the fast-evolving world. In practice, a continually pre-trained model is expected to demonstrate not only greater capacity when fine-tuned on pre-trained domains but also a non-decreasing performance on unseen ones. In this work, we first investigate such anytime fine-tuning effectiveness of existing continual pre-training approaches, concluding with unanimously decreased performance on unseen domains. To this end, we propose a prompt-guided continual pre-training method, where we train a hypernetwork to generate domain-specific prompts by both agreement and disagreement losses. The agreement loss maximally preserves the generalization of a pre-trained model to new domains, and the disagreement one guards the exclusiveness of the generated hidden states for each domain. Remarkably, prompts by the hypernetwork alleviate the domain identity when fine-tuning and promote knowledge transfer across domains. Our method achieved improvements of 3.57% and 3.4% on two real-world datasets (including domain shift and temporal shift), respectively, demonstrating its efficacy.
Prompt-augmented Temporal Point Process for Streaming Event Sequence
Oct 13, 2023


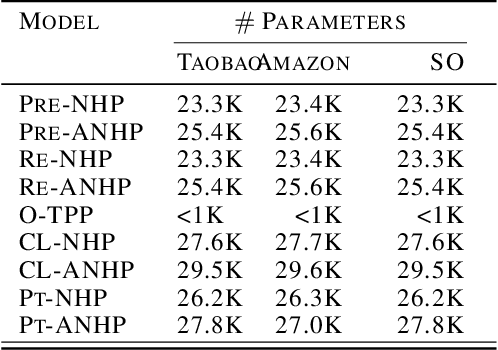
Neural Temporal Point Processes (TPPs) are the prevalent paradigm for modeling continuous-time event sequences, such as user activities on the web and financial transactions. In real-world applications, event data is typically received in a \emph{streaming} manner, where the distribution of patterns may shift over time. Additionally, \emph{privacy and memory constraints} are commonly observed in practical scenarios, further compounding the challenges. Therefore, the continuous monitoring of a TPP to learn the streaming event sequence is an important yet under-explored problem. Our work paper addresses this challenge by adopting Continual Learning (CL), which makes the model capable of continuously learning a sequence of tasks without catastrophic forgetting under realistic constraints. Correspondingly, we propose a simple yet effective framework, PromptTPP\footnote{Our code is available at {\small \url{ https://github.com/yanyanSann/PromptTPP}}}, by integrating the base TPP with a continuous-time retrieval prompt pool. The prompts, small learnable parameters, are stored in a memory space and jointly optimized with the base TPP, ensuring that the model learns event streams sequentially without buffering past examples or task-specific attributes. We present a novel and realistic experimental setup for modeling event streams, where PromptTPP consistently achieves state-of-the-art performance across three real user behavior datasets.
Enhancing Event Sequence Modeling with Contrastive Relational Inference
Sep 06, 2023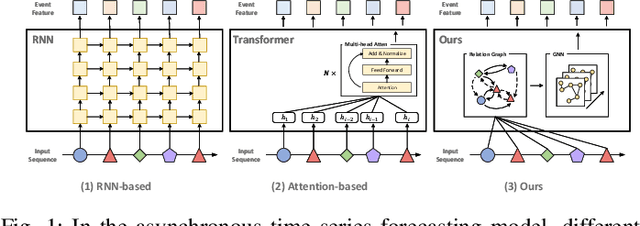
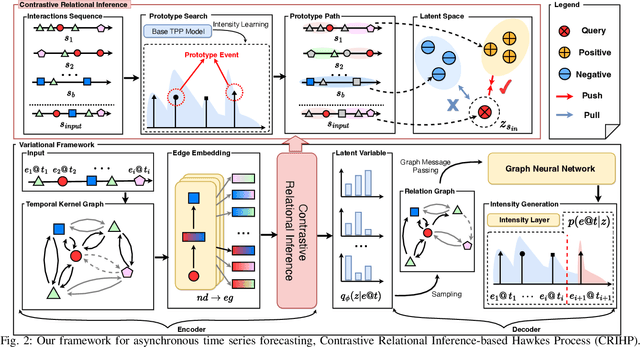
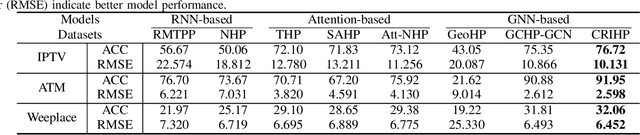
Neural temporal point processes(TPPs) have shown promise for modeling continuous-time event sequences. However, capturing the interactions between events is challenging yet critical for performing inference tasks like forecasting on event sequence data. Existing TPP models have focused on parameterizing the conditional distribution of future events but struggle to model event interactions. In this paper, we propose a novel approach that leverages Neural Relational Inference (NRI) to learn a relation graph that infers interactions while simultaneously learning the dynamics patterns from observational data. Our approach, the Contrastive Relational Inference-based Hawkes Process (CRIHP), reasons about event interactions under a variational inference framework. It utilizes intensity-based learning to search for prototype paths to contrast relationship constraints. Extensive experiments on three real-world datasets demonstrate the effectiveness of our model in capturing event interactions for event sequence modeling tasks.
WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
Aug 30, 2023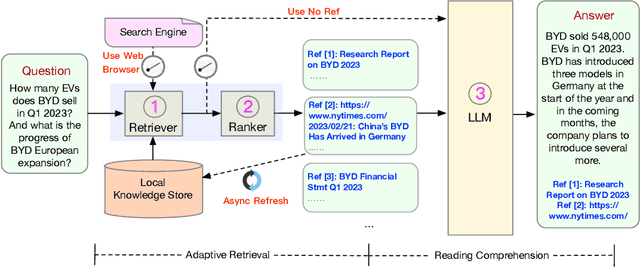
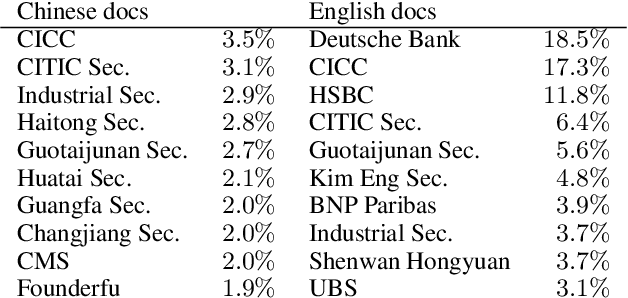
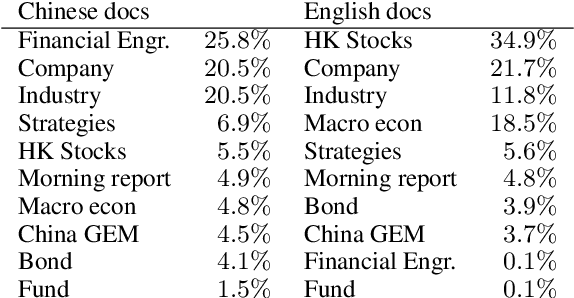
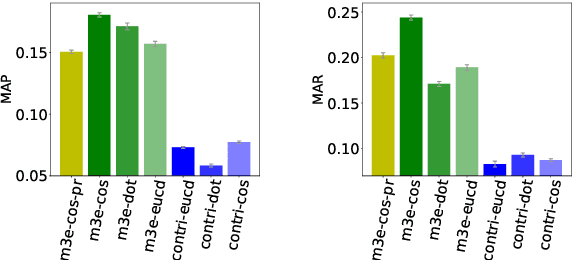
We present WeaverBird, an intelligent dialogue system designed specifically for the finance domain. Our system harnesses a large language model of GPT architecture that has been tuned using extensive corpora of finance-related text. As a result, our system possesses the capability to understand complex financial queries, such as "How should I manage my investments during inflation?", and provide informed responses. Furthermore, our system incorporates a local knowledge base and a search engine to retrieve relevant information. The final responses are conditioned on the search results and include proper citations to the sources, thus enjoying an enhanced credibility. Through a range of finance-related questions, we have demonstrated the superior performance of our system compared to other models. To experience our system firsthand, users can interact with our live demo at https://weaverbird.ttic.edu, as well as watch our 2-min video illustration at https://www.youtube.com/watch?v=fyV2qQkX6Tc.
Continual Learning in Predictive Autoscaling
Aug 14, 2023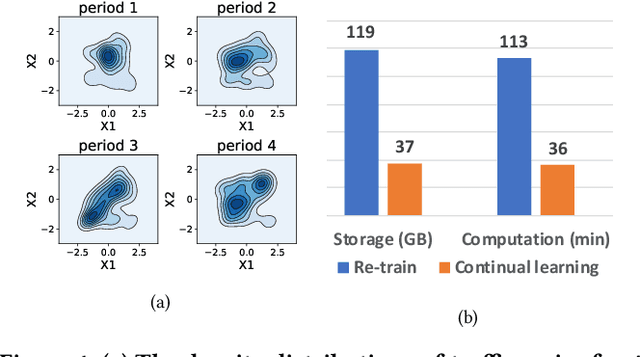
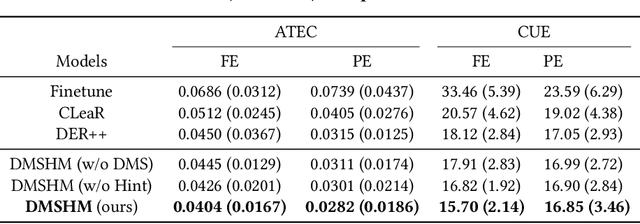
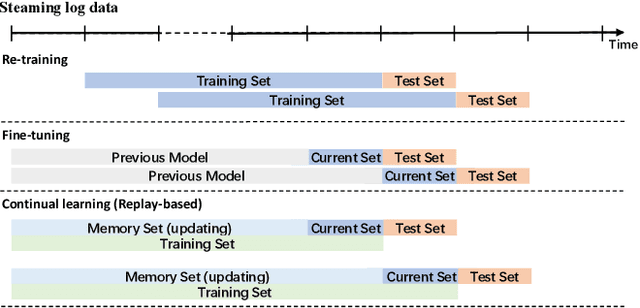
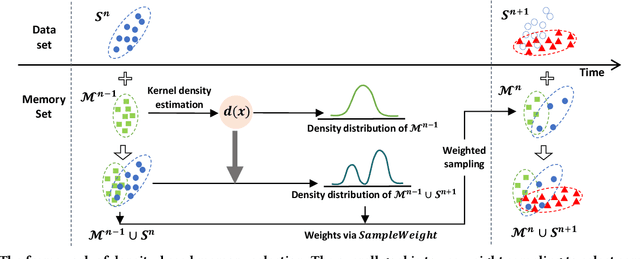
Predictive Autoscaling is used to forecast the workloads of servers and prepare the resources in advance to ensure service level objectives (SLOs) in dynamic cloud environments. However, in practice, its prediction task often suffers from performance degradation under abnormal traffics caused by external events (such as sales promotional activities and applications re-configurations), for which a common solution is to re-train the model with data of a long historical period, but at the expense of high computational and storage costs. To better address this problem, we propose a replay-based continual learning method, i.e., Density-based Memory Selection and Hint-based Network Learning Model (DMSHM), using only a small part of the historical log to achieve accurate predictions. First, we discover the phenomenon of sample overlap when applying replay-based continual learning in prediction tasks. In order to surmount this challenge and effectively integrate new sample distribution, we propose a density-based sample selection strategy that utilizes kernel density estimation to calculate sample density as a reference to compute sample weight, and employs weight sampling to construct a new memory set. Then we implement hint-based network learning based on hint representation to optimize the parameters. Finally, we conduct experiments on public and industrial datasets to demonstrate that our proposed method outperforms state-of-the-art continual learning methods in terms of memory capacity and prediction accuracy. Furthermore, we demonstrate remarkable practicability of DMSHM in real industrial applications.
EasyTPP: Towards Open Benchmarking the Temporal Point Processes
Jul 16, 2023Continuous-time event sequences play a vital role in real-world domains such as healthcare, finance, online shopping, social networks, and so on. To model such data, temporal point processes (TPPs) have emerged as the most advanced generative models, making a significant impact in both academic and application communities. Despite the emergence of many powerful models in recent years, there is still no comprehensive benchmark to evaluate them. This lack of standardization impedes researchers and practitioners from comparing methods and reproducing results, potentially slowing down progress in this field. In this paper, we present EasyTPP, which aims to establish a central benchmark for evaluating TPPs. Compared to previous work that also contributed datasets, our EasyTPP has three unique contributions to the community: (i) a comprehensive implementation of eight highly cited neural TPPs with the integration of commonly used evaluation metrics and datasets; (ii) a standardized benchmarking pipeline for a transparent and thorough comparison of different methods on different datasets; (iii) a universal framework supporting multiple ML libraries (e.g., PyTorch and TensorFlow) as well as custom implementations. Our benchmark is open-sourced: all the data and implementation can be found at this \href{https://github.com/ant-research/EasyTemporalPointProcess}{\textcolor{blue}{Github repository}}\footnote{\url{https://github.com/ant-research/EasyTemporalPointProcess}.}. We will actively maintain this benchmark and welcome contributions from other researchers and practitioners. Our benchmark will help promote reproducible research in this field, thus accelerating research progress as well as making more significant real-world impacts.