 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Preconditioners in Adaptive Optimization: A Unified Analysis
Mar 13, 2025
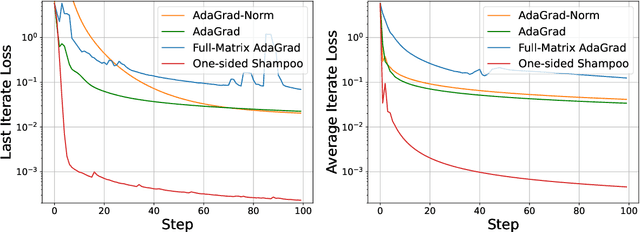

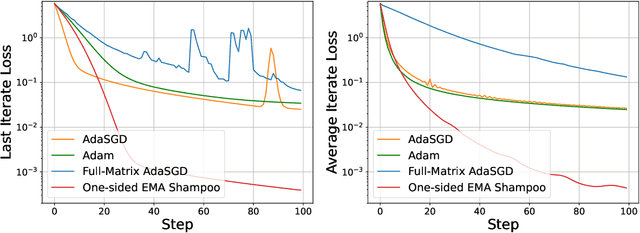
We present a novel unified analysis for a broad class of adaptive optimization algorithms with structured (e.g., layerwise, diagonal, and kronecker-factored) preconditioners for both online regret minimization and offline convex optimization. Our analysis not only provides matching rate to several important structured preconditioned algorithms including diagonal AdaGrad, full-matrix AdaGrad, and AdaGrad-Norm, but also gives an improved convergence rate for a one-sided variant of Shampoo over that of original Shampoo. Interestingly, more structured preconditioners (e.g., diagonal Adagrad, AdaGrad-Norm which use less space and compute) are often presented as computationally efficient approximations to full-matrix Adagrad, aiming for improved optimization performance through better approximations. Our unified analysis challenges this prevailing view and reveals, perhaps surprisingly, that more structured preconditioners, despite using less space and computation per step, can outperform their less structured counterparts. To demonstrate this, we show that one-sided Shampoo, which is relatively much cheaper than full-matrix AdaGrad could outperform it both theoretically and experimentally.
MPPO: Multi Pair-wise Preference Optimization for LLMs with Arbitrary Negative Samples
Dec 13, 2024



Aligning Large Language Models (LLMs) with human feedback is crucial for their development. Existing preference optimization methods such as DPO and KTO, while improved based on Reinforcement Learning from Human Feedback (RLHF), are inherently derived from PPO, requiring a reference model that adds GPU memory resources and relies heavily on abundant preference data. Meanwhile, current preference optimization research mainly targets single-question scenarios with two replies, neglecting optimization with multiple replies, which leads to a waste of data in the application. This study introduces the MPPO algorithm, which leverages the average likelihood of model responses to fit the reward function and maximizes the utilization of preference data. Through a comparison of Point-wise, Pair-wise, and List-wise implementations, we found that the Pair-wise approach achieves the best performance, significantly enhancing the quality of model responses. Experimental results demonstrate MPPO's outstanding performance across various benchmarks. On MT-Bench, MPPO outperforms DPO, ORPO, and SimPO. Notably, on Arena-Hard, MPPO surpasses DPO and ORPO by substantial margins. These achievements underscore the remarkable advantages of MPPO in preference optimization tasks.
Adam Exploits $\ell_\infty$-geometry of Loss Landscape via Coordinate-wise Adaptivity
Oct 10, 2024



Adam outperforms SGD when training language models. Yet this advantage is not well-understood theoretically -- previous convergence analysis for Adam and SGD mainly focuses on the number of steps $T$ and is already minimax-optimal in non-convex cases, which are both $\widetilde{O}(T^{-1/4})$. In this work, we argue that the exploitation of nice $\ell_\infty$-geometry is the key advantage of Adam over SGD. More specifically, we give a new convergence analysis for Adam under novel assumptions that loss is smooth under $\ell_\infty$-geometry rather than the more common $\ell_2$-geometry, which yields a much better empirical smoothness constant for GPT-2 and ResNet models. Our experiments confirm that Adam performs much worse when the favorable $\ell_\infty$-geometry is changed while SGD provably remains unaffected. We also extend the convergence analysis to blockwise Adam under novel blockwise smoothness assumptions.
Implicit Bias of AdamW: $\ell_\infty$ Norm Constrained Optimization
Apr 05, 2024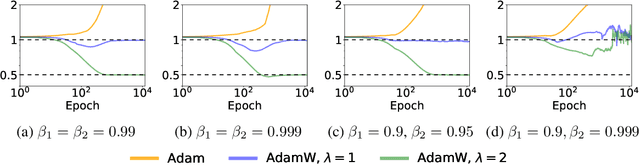
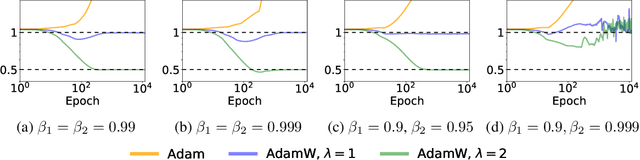
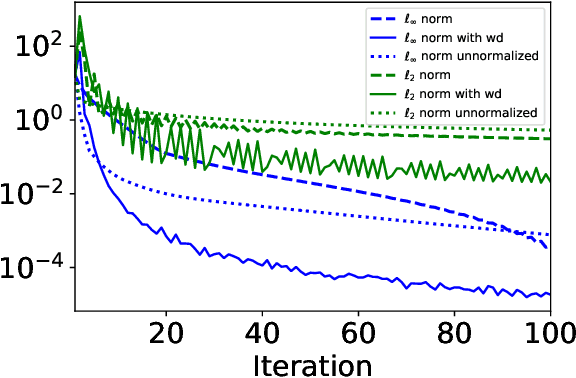
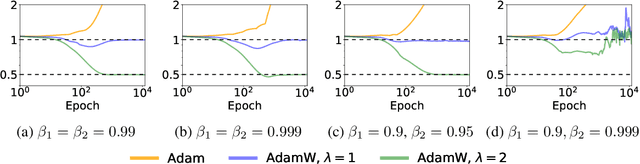
Adam with decoupled weight decay, also known as AdamW, is widely acclaimed for its superior performance in language modeling tasks, surpassing Adam with $\ell_2$ regularization in terms of generalization and optimization. However, this advantage is not theoretically well-understood. One challenge here is that though intuitively Adam with $\ell_2$ regularization optimizes the $\ell_2$ regularized loss, it is not clear if AdamW optimizes a specific objective. In this work, we make progress toward understanding the benefit of AdamW by showing that it implicitly performs constrained optimization. More concretely, we show in the full-batch setting, if AdamW converges with any non-increasing learning rate schedule whose partial sum diverges, it must converge to a KKT point of the original loss under the constraint that the $\ell_\infty$ norm of the parameter is bounded by the inverse of the weight decay factor. This result is built on the observation that Adam can be viewed as a smoothed version of SignGD, which is the normalized steepest descent with respect to $\ell_\infty$ norm, and a surprising connection between normalized steepest descent with weight decay and Frank-Wolfe.
WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
Aug 30, 2023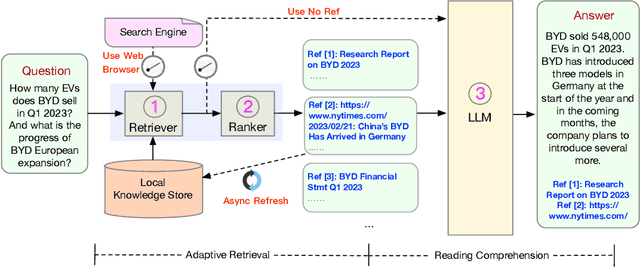
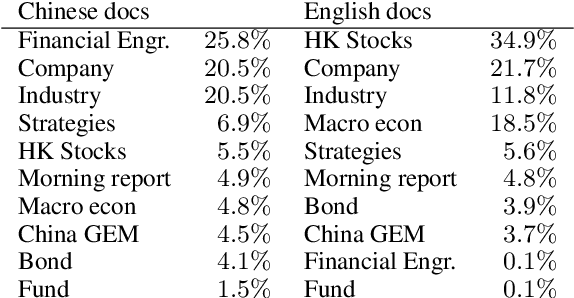
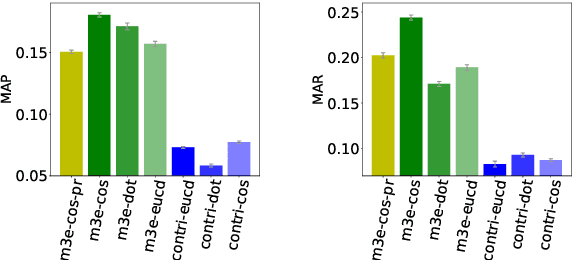
We present WeaverBird, an intelligent dialogue system designed specifically for the finance domain. Our system harnesses a large language model of GPT architecture that has been tuned using extensive corpora of finance-related text. As a result, our system possesses the capability to understand complex financial queries, such as "How should I manage my investments during inflation?", and provide informed responses. Furthermore, our system incorporates a local knowledge base and a search engine to retrieve relevant information. The final responses are conditioned on the search results and include proper citations to the sources, thus enjoying an enhanced credibility. Through a range of finance-related questions, we have demonstrated the superior performance of our system compared to other models. To experience our system firsthand, users can interact with our live demo at https://weaverbird.ttic.edu, as well as watch our 2-min video illustration at https://www.youtube.com/watch?v=fyV2qQkX6Tc.
Hidden State Variability of Pretrained Language Models Can Guide Computation Reduction for Transfer Learning
Oct 19, 2022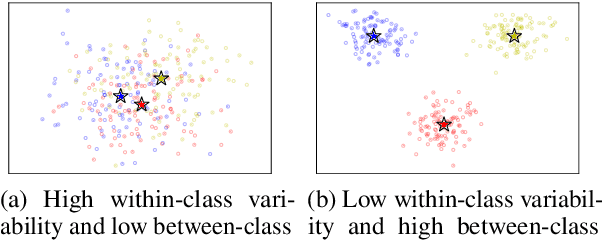
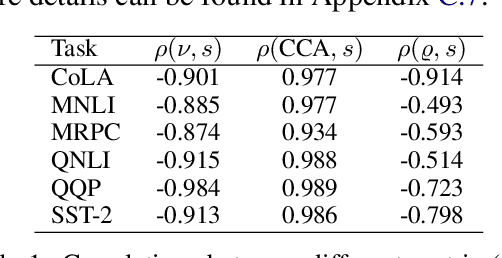
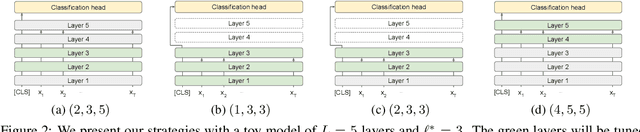
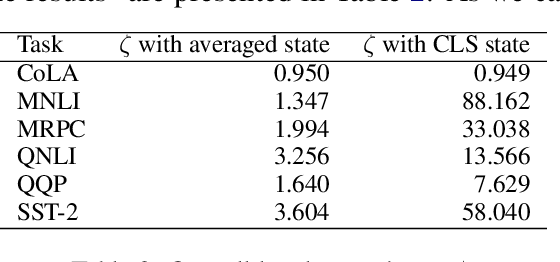
While transferring a pretrained language model, common approaches conventionally attach their task-specific classifiers to the top layer and adapt all the pretrained layers. We investigate whether one could make a task-specific selection on which subset of the layers to adapt and where to place the classifier. The goal is to reduce the computation cost of transfer learning methods (e.g. fine-tuning or adapter-tuning) without sacrificing its performance. We propose to select layers based on the variability of their hidden states given a task-specific corpus. We say a layer is already "well-specialized" in a task if the within-class variability of its hidden states is low relative to the between-class variability. Our variability metric is cheap to compute and doesn't need any training or hyperparameter tuning. It is robust to data imbalance and data scarcity. Extensive experiments on the GLUE benchmark demonstrate that selecting layers based on our metric can yield significantly stronger performance than using the same number of top layers and often match the performance of fine-tuning or adapter-tuning the entire language model.