 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPPO: Multi Pair-wise Preference Optimization for LLMs with Arbitrary Negative Samples
Dec 13, 2024



Aligning Large Language Models (LLMs) with human feedback is crucial for their development. Existing preference optimization methods such as DPO and KTO, while improved based on Reinforcement Learning from Human Feedback (RLHF), are inherently derived from PPO, requiring a reference model that adds GPU memory resources and relies heavily on abundant preference data. Meanwhile, current preference optimization research mainly targets single-question scenarios with two replies, neglecting optimization with multiple replies, which leads to a waste of data in the application. This study introduces the MPPO algorithm, which leverages the average likelihood of model responses to fit the reward function and maximizes the utilization of preference data. Through a comparison of Point-wise, Pair-wise, and List-wise implementations, we found that the Pair-wise approach achieves the best performance, significantly enhancing the quality of model responses. Experimental results demonstrate MPPO's outstanding performance across various benchmarks. On MT-Bench, MPPO outperforms DPO, ORPO, and SimPO. Notably, on Arena-Hard, MPPO surpasses DPO and ORPO by substantial margins. These achievements underscore the remarkable advantages of MPPO in preference optimization tasks.
SuDA: Support-based Domain Adaptation for Sim2Real Motion Capture with Flexible Sensors
May 25, 2024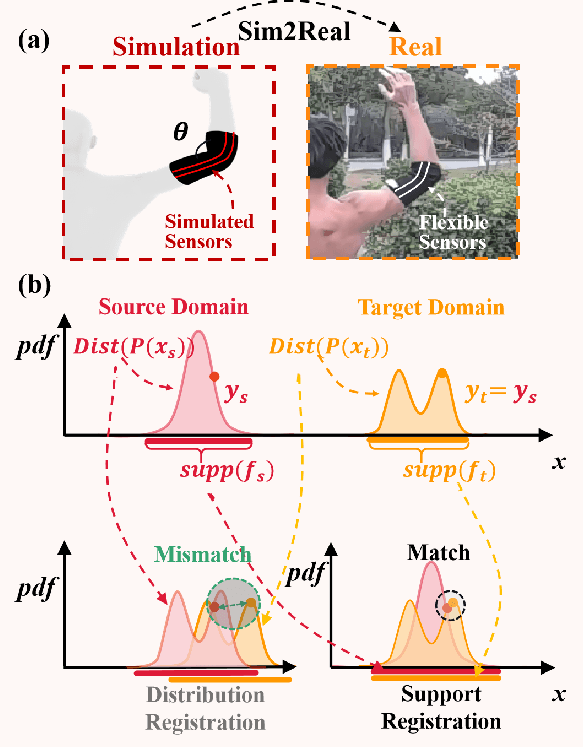

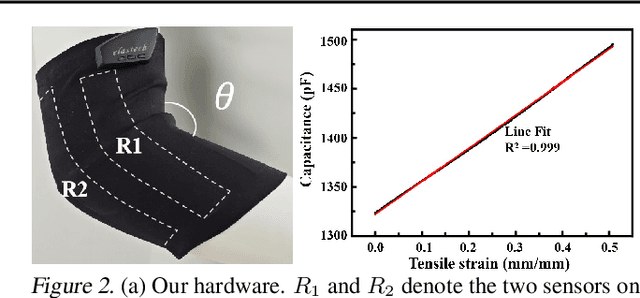
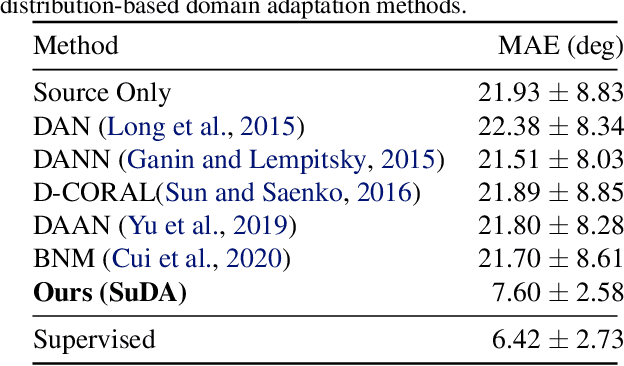
Flexible sensors hold promise for human motion capture (MoCap), offering advantages such as wearability, privacy preservation, and minimal constraints on natural movement. However, existing flexible sensor-based MoCap methods rely on deep learning and necessitate large and diverse labeled datasets for training. These data typically need to be collected in MoCap studios with specialized equipment and substantial manual labor, making them difficult and expensive to obtain at scale. Thanks to the high-linearity of flexible sensors, we address this challenge by proposing a novel Sim2Real Mocap solution based on domain adaptation, eliminating the need for labeled data yet achieving comparable accuracy to supervised learning. Our solution relies on a novel Support-based Domain Adaptation method, namely SuDA, which aligns the supports of the predictive functions rather than the instance-dependent distributions between the source and target domains. Extensive experimental results demonstrate the effectiveness of our method andits superiority over state-of-the-art distribution-based domain adaptation methods in our task.
Support-Query Prototype Fusion Network for Few-shot Medical Image Segmentation
May 13, 2024



In recent years, deep learning based on Convolutional Neural Networks (CNNs) has achieved remarkable success in many applications. However, their heavy reliance on extensive labeled data and limited generalization ability to unseen classes pose challenges to their suitability for medical image processing tasks. Few-shot learning, which utilizes a small amount of labeled data to generalize to unseen classes, has emerged as a critical research area, attracting substantial attention. Currently, most studies employ a prototype-based approach, in which prototypical networks are used to construct prototypes from the support set, guiding the processing of the query set to obtain the final results. While effective, this approach heavily relies on the support set while neglecting the query set, resulting in notable disparities within the model classes. To mitigate this drawback, we propose a novel Support-Query Prototype Fusion Network (SQPFNet). SQPFNet initially generates several support prototypes for the foreground areas of the support images, thus producing a coarse segmentation mask. Subsequently, a query prototype is constructed based on the coarse segmentation mask, additionally exploiting pattern information in the query set. Thus, SQPFNet constructs high-quality support-query fused prototypes, upon which the query image is segmented to obtain the final refined query mask. Evaluation results on two public datasets, SABS and CMR, show that SQPFNet achieves state-of-the-art performance.
Multi-Task Learning for Fatigue Detection and Face Recognition of Drivers via Tree-Style Space-Channel Attention Fusion Network
May 13, 2024



In driving scenarios, automobile active safety systems are increasingly incorporating deep learning technology. These systems typically need to handle multiple tasks simultaneously, such as detecting fatigue driving and recognizing the driver's identity. However, the traditional parallel-style approach of combining multiple single-task models tends to waste resources when dealing with similar tasks. Therefore, we propose a novel tree-style multi-task modeling approach for multi-task learning, which rooted at a shared backbone, more dedicated separate module branches are appended as the model pipeline goes deeper. Following the tree-style approach, we propose a multi-task learning model for simultaneously performing driver fatigue detection and face recognition for identifying a driver. This model shares a common feature extraction backbone module, with further separated feature extraction and classification module branches. The dedicated branches exploit and combine spatial and channel attention mechanisms to generate space-channel fused-attention enhanced features, leading to improved detection performance. As only single-task datasets are available, we introduce techniques including alternating updation and gradient accumulation for training our multi-task model using only the single-task datasets. The effectiveness of our tree-style multi-task learning model is verified through extensive validations.
HB-net: Holistic bursting cell cluster integrated network for occluded multi-objects recognition
Oct 18, 2023



Within the realm of image recognition, a specific category of multi-label classification (MLC) challenges arises when objects within the visual field may occlude one another, demanding simultaneous identification of both occluded and occluding objects. Traditional convolutional neural networks (CNNs) can tackle these challenges; however, those models tend to be bulky and can only attain modest levels of accuracy. Leveraging insights from cutting-edge neural science research, specifically the Holistic Bursting (HB) cell, this paper introduces a pioneering integrated network framework named HB-net. Built upon the foundation of HB cell clusters, HB-net is designed to address the intricate task of simultaneously recognizing multiple occluded objects within images. Various Bursting cell cluster structures are introduced, complemented by an evidence accumulation mechanism. Testing is conducted on multiple datasets comprising digits and letters. The results demonstrate that models incorporating the HB framework exhibit a significant $2.98\%$ enhancement in recognition accuracy compared to models without the HB framework ($1.0298$ times, $p=0.0499$). Although in high-noise settings, standard CNNs exhibit slightly greater robustness when compared to HB-net models, the models that combine the HB framework and EA mechanism achieve a comparable level of accuracy and resilience to ResNet50, despite having only three convolutional layers and approximately $1/30$ of the parameters. The findings of this study offer valuable insights for improving computer vision algorithms. The essential code is provided at https://github.com/d-lab438/hb-net.git.
Distance and Hop-wise Structures Encoding Enhanced Graph Attention Networks
Dec 06, 2021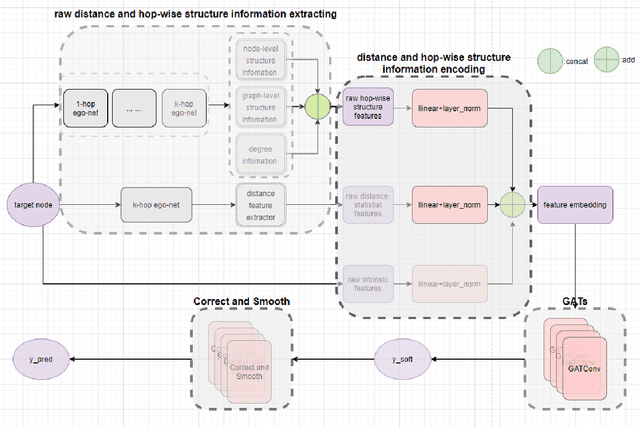
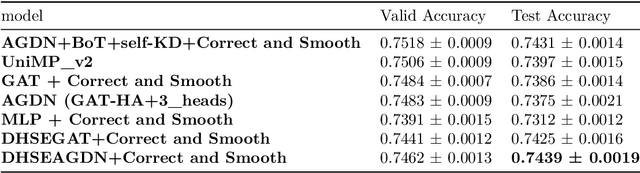


Numerous works have proven that existing neighbor-averaging Graph Neural Networks cannot efficiently catch structure features, and many works show that injecting structure, distance, position or spatial features can significantly improve performance of GNNs, however, injecting overall structure and distance into GNNs is an intuitive but remaining untouched idea. In this work, we shed light on the direction. We first extracting hop-wise structure information and compute distance distributional information, gathering with node's intrinsic features, embedding them into same vector space and then adding them up. The derived embedding vectors are then fed into GATs(like GAT, AGDN) and then Correct and Smooth, experiments show that the DHSEGATs achieve competitive result. The code is available at https://github.com/hzg0601/DHSEGATs.
Multi-layered Network Exploration via Random Walks: From Offline Optimization to Online Learning
Jun 09, 2021
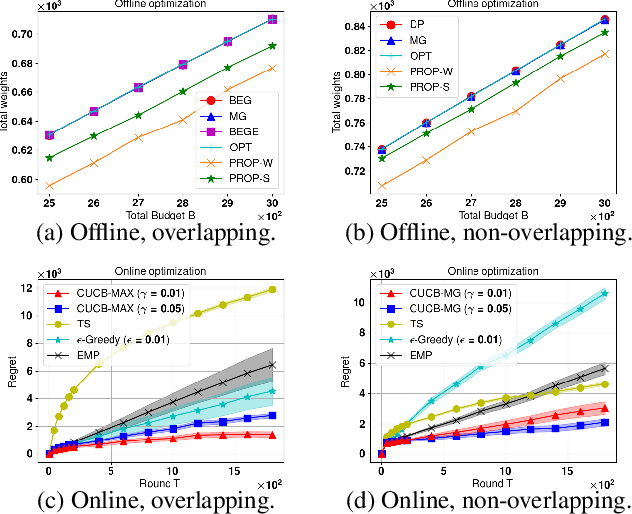
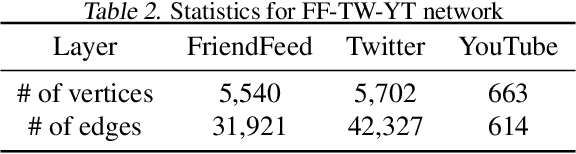
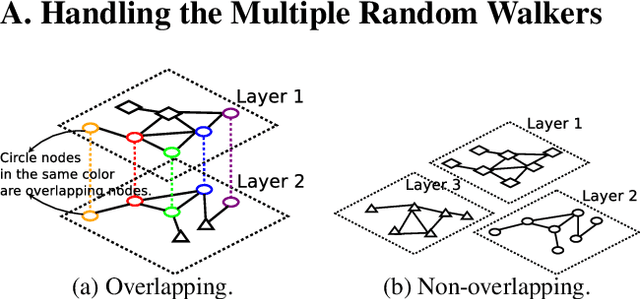
Multi-layered network exploration (MuLaNE) problem is an important problem abstracted from many applications. In MuLaNE, there are multiple network layers where each node has an importance weight and each layer is explored by a random walk. The MuLaNE task is to allocate total random walk budget $B$ into each network layer so that the total weights of the unique nodes visited by random walks are maximized. We systematically study this problem from offline optimization to online learning. For the offline optimization setting where the network structure and node weights are known, we provide greedy based constant-ratio approximation algorithms for overlapping networks, and greedy or dynamic-programming based optimal solutions for non-overlapping networks. For the online learning setting, neither the network structure nor the node weights are known initially. We adapt the combinatorial multi-armed bandit framework and design algorithms to learn random walk related parameters and node weights while optimizing the budget allocation in multiple rounds, and prove that they achieve logarithmic regret bounds. Finally, we conduct experiments on a real-world social network dataset to validate our theoretical results.
Community Exploration: From Offline Optimization to Online Learning
Nov 18, 2018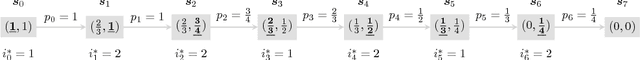

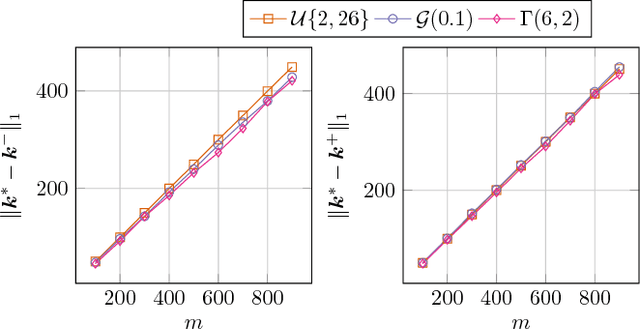
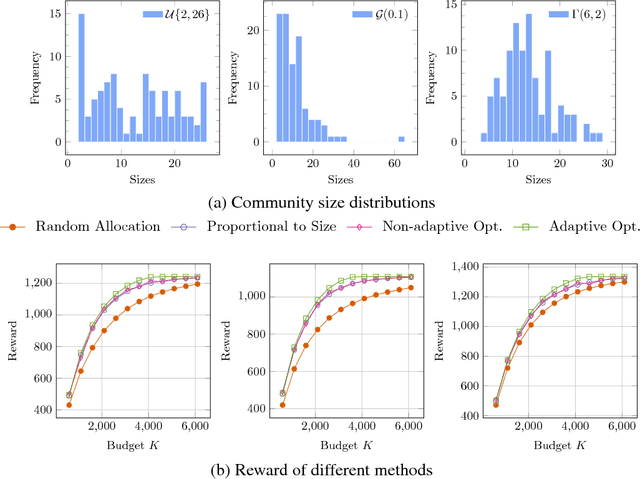
We introduce the community exploration problem that has many real-world applications such as online advertising. In the problem, an explorer allocates limited budget to explore communities so as to maximize the number of members he could meet. We provide a systematic study of the community exploration problem, from offline optimization to online learning. For the offline setting where the sizes of communities are known, we prove that the greedy methods for both of non-adaptive exploration and adaptive exploration are optimal. For the online setting where the sizes of communities are not known and need to be learned from the multi-round explorations, we propose an `upper confidence' like algorithm that achieves the logarithmic regret bounds. By combining the feedback from different rounds, we can achieve a constant regret bound.