 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models as Group Actions
May 23, 2026Video world models have achieved strong visual realism, but this does not ensure that their dynamics are truly governed by actions. In this work, we argue that action faithfulness should be understood through the compositional structure of actions, which in many embodied settings follows a group structure (e.g., SE(2) for navigation). Based on this insight, we formalize action-conditioned world modeling as realizing a group action on the state space, providing a principled criterion for evaluating dynamics beyond visual quality. To operationalize this framework, we propose a unified approach that enforces identity, inverse, and composition consistency via latent-space regularization with synthesized supervision, avoiding additional data collection. We further introduce two metrics: Group-Action Consistency (GAC) and Group-Action Robustness (GAR), to evaluate structural correctness and rollout stability. Extensive experimental results show that our method consistently improves both GAC and GAR in state-of-the-art video world models without degrading perceptual quality.
3DGS-HPC: Distractor-free 3D Gaussian Splatting with Hybrid Patch-wise Classification
Mar 08, 20263D Gaussian Splatting (3DGS) has demonstrated remarkable performance in novel view synthesis and 3D scene reconstruction, yet its quality often degrades in real-world environments due to transient distractors, such as moving objects and varying shadows. Existing methods commonly rely on semantic cues extracted from pre-trained vision models to identify and suppress these distractors, but such semantics are misaligned with the binary distinction between static and transient regions and remain fragile under the appearance perturbations introduced during 3DGS optimization. We propose 3DGS-HPC, a framework that circumvents these limitations by combining two complementary principles: a patch-wise classification strategy that leverages local spatial consistency for robust region-level decisions, and a hybrid classification metric that adaptively integrates photometric and perceptual cues for more reliable separation. Extensive experiments demonstrate the superiority and robustness of our method in mitigating distractors to improve 3DGS-based novel view synthesis.
LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
Dec 09, 2025Personalizing visual generative models to meet specific user needs has gained increasing attention, yet current methods like Low-Rank Adaptation (LoRA) remain impractical due to their demand for task-specific data and lengthy optimization. While a few hypernetwork-based approaches attempt to predict adaptation weights directly, they struggle to map fine-grained user prompts to complex LoRA distributions, limiting their practical applicability. To bridge this gap, we propose LoFA, a general framework that efficiently predicts personalized priors for fast model adaptation. We first identify a key property of LoRA: structured distribution patterns emerge in the relative changes between LoRA and base model parameters. Building on this, we design a two-stage hypernetwork: first predicting relative distribution patterns that capture key adaptation regions, then using these to guide final LoRA weight prediction. Extensive experiments demonstrate that our method consistently predicts high-quality personalized priors within seconds, across multiple tasks and user prompts, even outperforming conventional LoRA that requires hours of processing. Project page: https://jaeger416.github.io/lofa/.
Transformer IMU Calibrator: Dynamic On-body IMU Calibration for Inertial Motion Capture
Jun 12, 2025In this paper, we propose a novel dynamic calibration method for sparse inertial motion capture systems, which is the first to break the restrictive absolute static assumption in IMU calibration, i.e., the coordinate drift RG'G and measurement offset RBS remain constant during the entire motion, thereby significantly expanding their application scenarios. Specifically, we achieve real-time estimation of RG'G and RBS under two relaxed assumptions: i) the matrices change negligibly in a short time window; ii) the human movements/IMU readings are diverse in such a time window. Intuitively, the first assumption reduces the number of candidate matrices, and the second assumption provides diverse constraints, which greatly reduces the solution space and allows for accurate estimation of RG'G and RBS from a short history of IMU readings in real time. To achieve this, we created synthetic datasets of paired RG'G, RBS matrices and IMU readings, and learned their mappings using a Transformer-based model. We also designed a calibration trigger based on the diversity of IMU readings to ensure that assumption ii) is met before applying our method. To our knowledge, we are the first to achieve implicit IMU calibration (i.e., seamlessly putting IMUs into use without the need for an explicit calibration process), as well as the first to enable long-term and accurate motion capture using sparse IMUs. The code and dataset are available at https://github.com/ZuoCX1996/TIC.
VTON 360: High-Fidelity Virtual Try-On from Any Viewing Direction
Mar 15, 2025Virtual Try-On (VTON) is a transformative technology in e-commerce and fashion design, enabling realistic digital visualization of clothing on individuals. In this work, we propose VTON 360, a novel 3D VTON method that addresses the open challenge of achieving high-fidelity VTON that supports any-view rendering. Specifically, we leverage the equivalence between a 3D model and its rendered multi-view 2D images, and reformulate 3D VTON as an extension of 2D VTON that ensures 3D consistent results across multiple views. To achieve this, we extend 2D VTON models to include multi-view garments and clothing-agnostic human body images as input, and propose several novel techniques to enhance them, including: i) a pseudo-3D pose representation using normal maps derived from the SMPL-X 3D human model, ii) a multi-view spatial attention mechanism that models the correlations between features from different viewing angles, and iii) a multi-view CLIP embedding that enhances the garment CLIP features used in 2D VTON with camera information. Extensive experiments on large-scale real datasets and clothing images from e-commerce platforms demonstrate the effectiveness of our approach. Project page: https://scnuhealthy.github.io/VTON360.
1-2-1: Renaissance of Single-Network Paradigm for Virtual Try-On
Jan 09, 2025



Virtual Try-On (VTON) has become a crucial tool in ecommerce, enabling the realistic simulation of garments on individuals while preserving their original appearance and pose. Early VTON methods relied on single generative networks, but challenges remain in preserving fine-grained garment details due to limitations in feature extraction and fusion. To address these issues, recent approaches have adopted a dual-network paradigm, incorporating a complementary "ReferenceNet" to enhance garment feature extraction and fusion. While effective, this dual-network approach introduces significant computational overhead, limiting its scalability for high-resolution and long-duration image/video VTON applications. In this paper, we challenge the dual-network paradigm by proposing a novel single-network VTON method that overcomes the limitations of existing techniques. Our method, namely MNVTON, introduces a Modality-specific Normalization strategy that separately processes text, image and video inputs, enabling them to share the same attention layers in a VTON network. Extensive experimental results demonstrate the effectiveness of our approach, showing that it consistently achieves higher-quality, more detailed results for both image and video VTON tasks. Our results suggest that the single-network paradigm can rival the performance of dualnetwork approaches, offering a more efficient alternative for high-quality, scalable VTON applications.
Training-free Editioning of Text-to-Image Models
May 27, 2024



Inspired by the software industry's practice of offering different editions or versions of a product tailored to specific user groups or use cases, we propose a novel task, namely, training-free editioning, for text-to-image models. Specifically, we aim to create variations of a base text-to-image model without retraining, enabling the model to cater to the diverse needs of different user groups or to offer distinct features and functionalities. To achieve this, we propose that different editions of a given text-to-image model can be formulated as concept subspaces in the latent space of its text encoder (e.g., CLIP). In such a concept subspace, all points satisfy a specific user need (e.g., generating images of a cat lying on the grass/ground/falling leaves). Technically, we apply Principal Component Analysis (PCA) to obtain the desired concept subspaces from representative text embedding that correspond to a specific user need or requirement. Projecting the text embedding of a given prompt into these low-dimensional subspaces enables efficient model editioning without retraining. Intuitively, our proposed editioning paradigm enables a service provider to customize the base model into its "cat edition" (or other editions) that restricts image generation to cats, regardless of the user's prompt (e.g., dogs, people, etc.). This introduces a new dimension for product differentiation, targeted functionality, and pricing strategies, unlocking novel business models for text-to-image generators. Extensive experimental results demonstrate the validity of our approach and its potential to enable a wide range of customized text-to-image model editions across various domains and applications.
SuDA: Support-based Domain Adaptation for Sim2Real Motion Capture with Flexible Sensors
May 25, 2024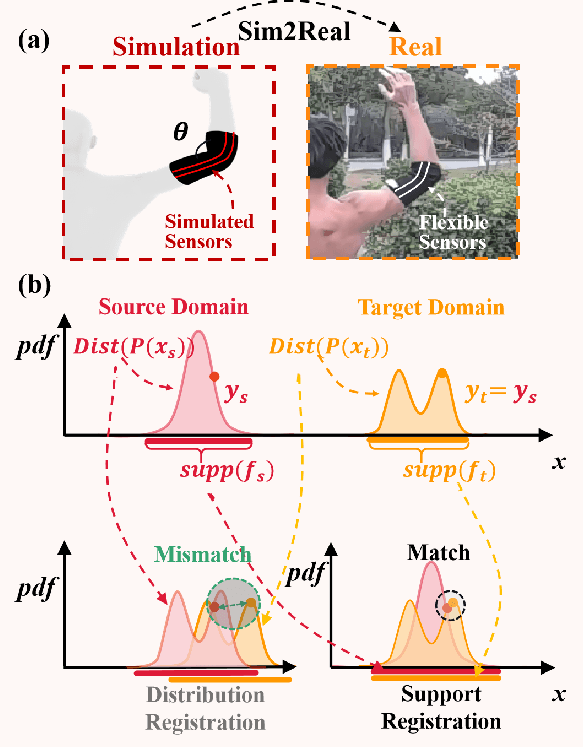

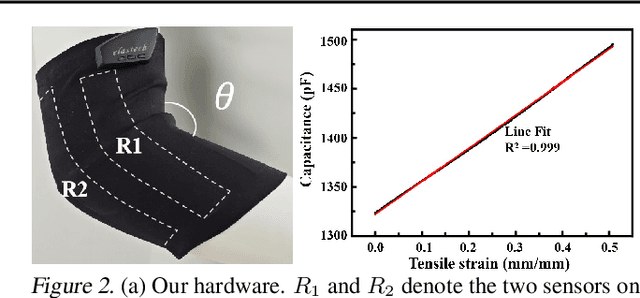
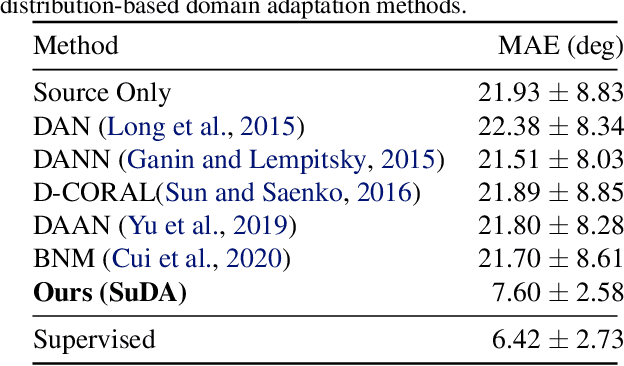
Flexible sensors hold promise for human motion capture (MoCap), offering advantages such as wearability, privacy preservation, and minimal constraints on natural movement. However, existing flexible sensor-based MoCap methods rely on deep learning and necessitate large and diverse labeled datasets for training. These data typically need to be collected in MoCap studios with specialized equipment and substantial manual labor, making them difficult and expensive to obtain at scale. Thanks to the high-linearity of flexible sensors, we address this challenge by proposing a novel Sim2Real Mocap solution based on domain adaptation, eliminating the need for labeled data yet achieving comparable accuracy to supervised learning. Our solution relies on a novel Support-based Domain Adaptation method, namely SuDA, which aligns the supports of the predictive functions rather than the instance-dependent distributions between the source and target domains. Extensive experimental results demonstrate the effectiveness of our method andits superiority over state-of-the-art distribution-based domain adaptation methods in our task.
LATUP-Net: A Lightweight 3D Attention U-Net with Parallel Convolutions for Brain Tumor Segmentation
Apr 09, 2024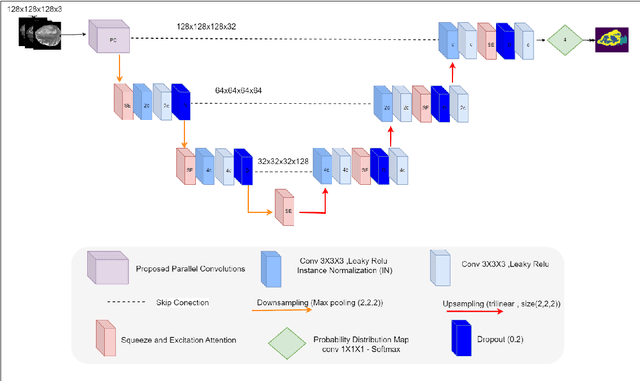

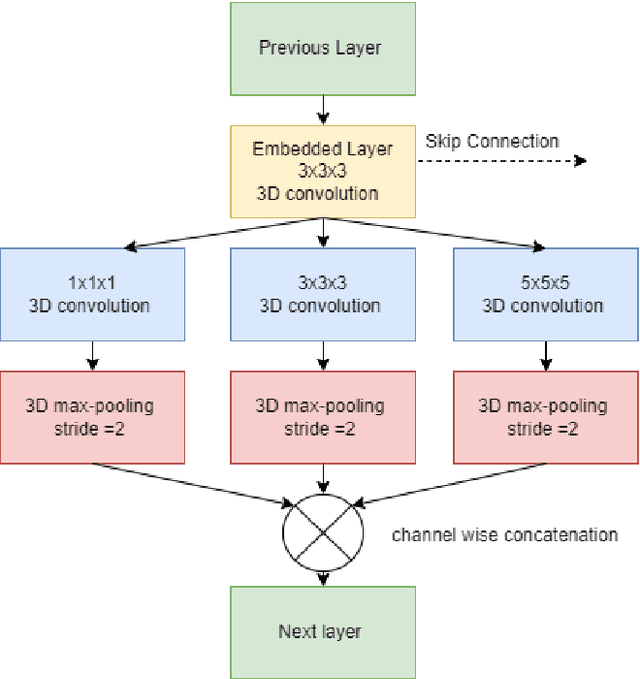

Early-stage 3D brain tumor segmentation from magnetic resonance imaging (MRI) scans is crucial for prompt and effective treatment. However, this process faces the challenge of precise delineation due to the tumors' complex heterogeneity. Moreover, energy sustainability targets and resource limitations, especially in developing countries, require efficient and accessible medical imaging solutions. The proposed architecture, a Lightweight 3D ATtention U-Net with Parallel convolutions, LATUP-Net, addresses these issues. It is specifically designed to reduce computational requirements significantly while maintaining high segmentation performance. By incorporating parallel convolutions, it enhances feature representation by capturing multi-scale information. It further integrates an attention mechanism to refine segmentation through selective feature recalibration. LATUP-Net achieves promising segmentation performance: the average Dice scores for the whole tumor, tumor core, and enhancing tumor on the BraTS2020 dataset are 88.41%, 83.82%, and 73.67%, and on the BraTS2021 dataset, they are 90.29%, 89.54%, and 83.92%, respectively. Hausdorff distance metrics further indicate its improved ability to delineate tumor boundaries. With its significantly reduced computational demand using only 3.07 M parameters, about 59 times fewer than other state-of-the-art models, and running on a single V100 GPU, LATUP-Net stands out as a promising solution for real-world clinical applications, particularly in settings with limited resources. Investigations into the model's interpretability, utilizing gradient-weighted class activation mapping and confusion matrices, reveal that while attention mechanisms enhance the segmentation of small regions, their impact is nuanced. Achieving the most accurate tumor delineation requires carefully balancing local and global features.
NeRF-HuGS: Improved Neural Radiance Fields in Non-static Scenes Using Heuristics-Guided Segmentation
Mar 26, 2024

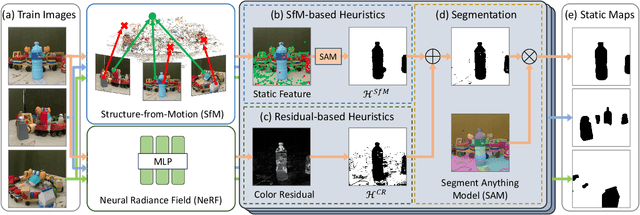

Neural Radiance Field (NeRF) has been widely recognized for its excellence in novel view synthesis and 3D scene reconstruction. However, their effectiveness is inherently tied to the assumption of static scenes, rendering them susceptible to undesirable artifacts when confronted with transient distractors such as moving objects or shadows. In this work, we propose a novel paradigm, namely "Heuristics-Guided Segmentation" (HuGS), which significantly enhances the separation of static scenes from transient distractors by harmoniously combining the strengths of hand-crafted heuristics and state-of-the-art segmentation models, thus significantly transcending the limitations of previous solutions. Furthermore, we delve into the meticulous design of heuristics, introducing a seamless fusion of Structure-from-Motion (SfM)-based heuristics and color residual heuristics, catering to a diverse range of texture profiles. Extensive experiments demonstrate the superiority and robustness of our method in mitigating transient distractors for NeRFs trained in non-static scenes. Project page: https://cnhaox.github.io/NeRF-HuGS/.