 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATUP-Net: A Lightweight 3D Attention U-Net with Parallel Convolutions for Brain Tumor Segmentation
Apr 09, 2024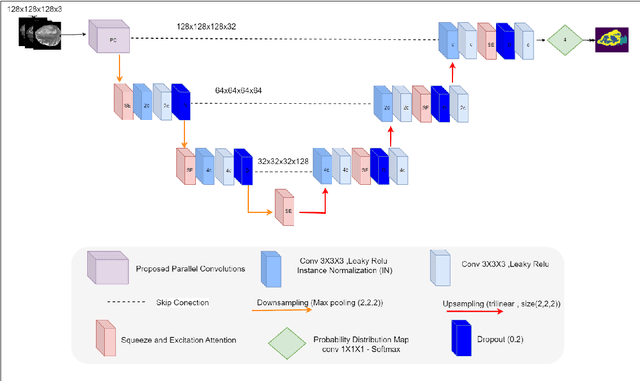

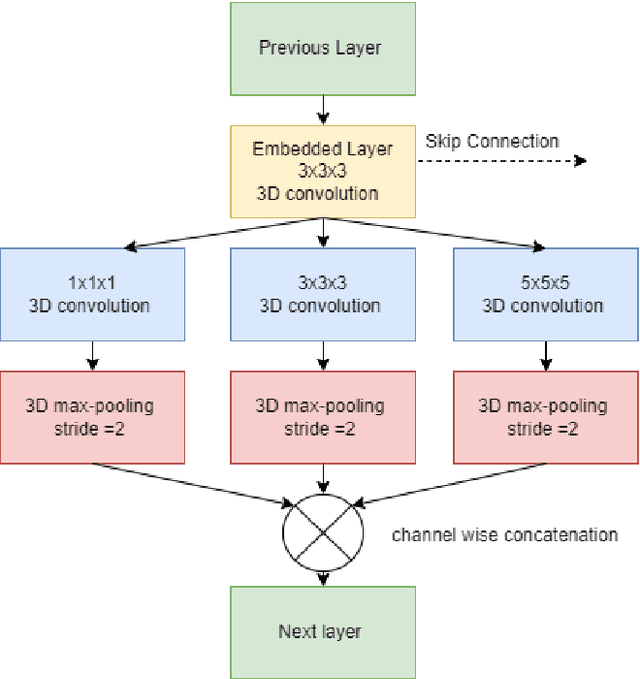

Early-stage 3D brain tumor segmentation from magnetic resonance imaging (MRI) scans is crucial for prompt and effective treatment. However, this process faces the challenge of precise delineation due to the tumors' complex heterogeneity. Moreover, energy sustainability targets and resource limitations, especially in developing countries, require efficient and accessible medical imaging solutions. The proposed architecture, a Lightweight 3D ATtention U-Net with Parallel convolutions, LATUP-Net, addresses these issues. It is specifically designed to reduce computational requirements significantly while maintaining high segmentation performance. By incorporating parallel convolutions, it enhances feature representation by capturing multi-scale information. It further integrates an attention mechanism to refine segmentation through selective feature recalibration. LATUP-Net achieves promising segmentation performance: the average Dice scores for the whole tumor, tumor core, and enhancing tumor on the BraTS2020 dataset are 88.41%, 83.82%, and 73.67%, and on the BraTS2021 dataset, they are 90.29%, 89.54%, and 83.92%, respectively. Hausdorff distance metrics further indicate its improved ability to delineate tumor boundaries. With its significantly reduced computational demand using only 3.07 M parameters, about 59 times fewer than other state-of-the-art models, and running on a single V100 GPU, LATUP-Net stands out as a promising solution for real-world clinical applications, particularly in settings with limited resources. Investigations into the model's interpretability, utilizing gradient-weighted class activation mapping and confusion matrices, reveal that while attention mechanisms enhance the segmentation of small regions, their impact is nuanced. Achieving the most accurate tumor delineation requires carefully balancing local and global features.
Resource-efficient domain adaptive pre-training for medical images
Apr 28, 2022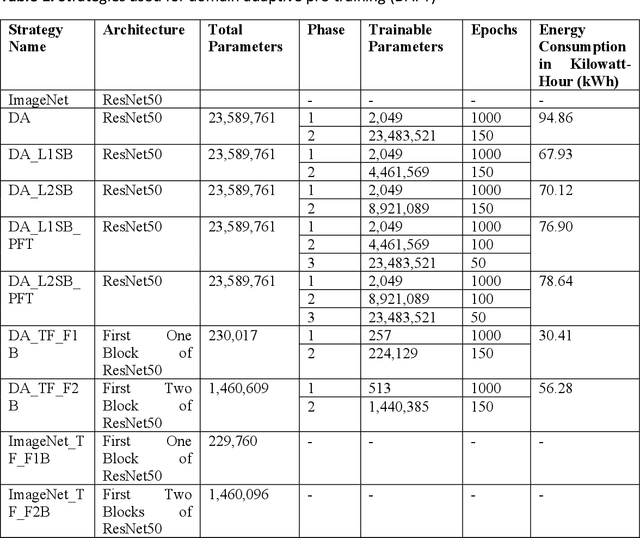

The deep learning-based analysis of medical images suffers from data scarcity because of high annotation costs and privacy concerns. Researchers in this domain have used transfer learning to avoid overfitting when using complex architectures. However, the domain differences between pre-training and downstream data hamper the performance of the downstream task. Some recent studies have successfully used domain-adaptive pre-training (DAPT) to address this issue. In DAPT, models are initialized with the generic dataset pre-trained weights, and further pre-training is performed using a moderately sized in-domain dataset (medical images). Although this technique achieved good results for the downstream tasks in terms of accuracy and robustness, it is computationally expensive even when the datasets for DAPT are moderately sized. These compute-intensive techniques and models impact the environment negatively and create an uneven playing field for researchers with limited resources. This study proposed computationally efficient DAPT without compromising the downstream accuracy and robustness. This study proposes three techniques for this purpose, where the first (partial DAPT) performs DAPT on a subset of layers. The second one adopts a hybrid strategy (hybrid DAPT) by performing partial DAPT for a few epochs and then full DAPT for the remaining epochs. The third technique performs DAPT on simplified variants of the base architecture. The results showed that compared to the standard DAPT (full DAPT), the hybrid DAPT technique achieved better performance on the development and external datasets. In contrast, simplified architectures (after DAPT) achieved the best robustness while achieving modest performance on the development dataset .
Shape retrieval of non-rigid 3d human models
Mar 01, 2020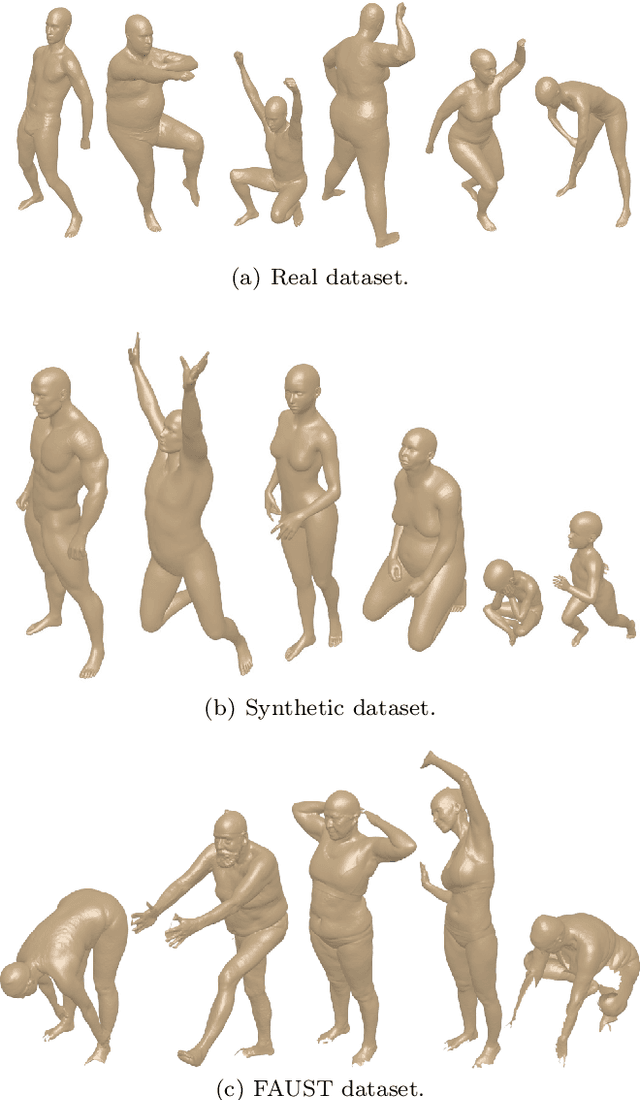
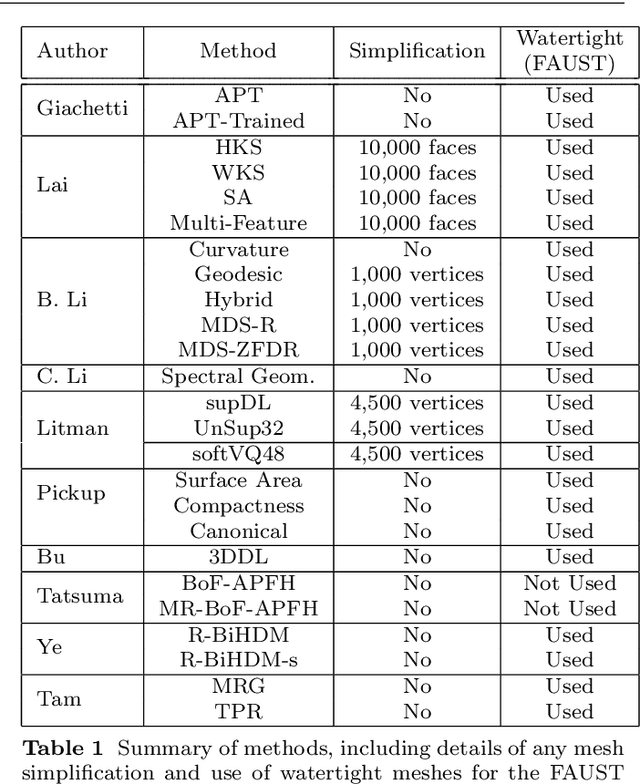
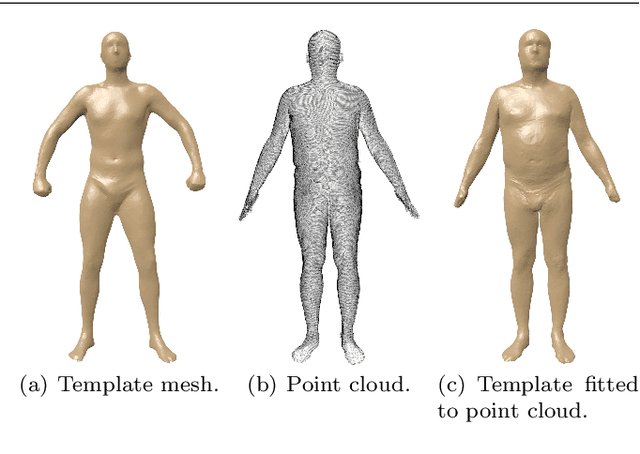
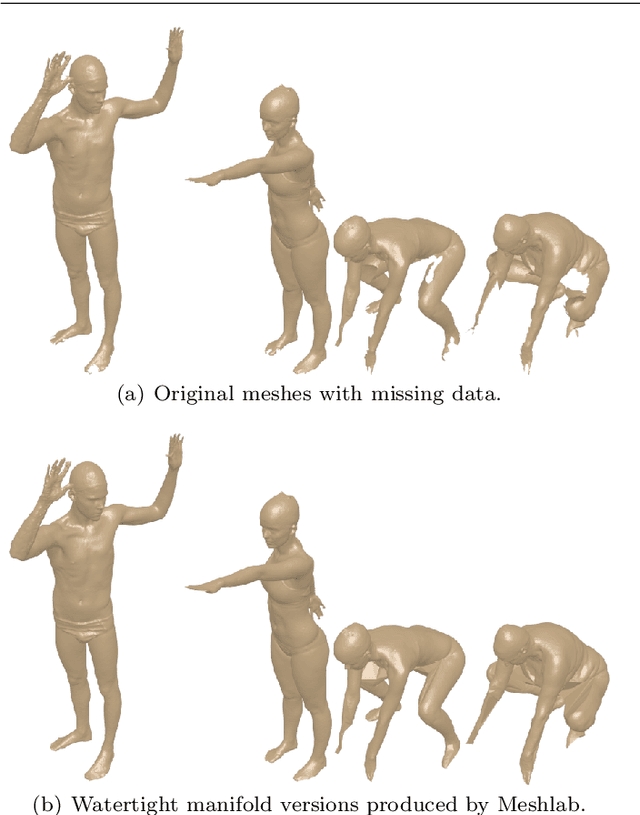
3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. We extend our recent paper which provided a benchmark for testing non-rigid 3D shape retrieval algorithms on 3D human models. This benchmark provided a far stricter challenge than previous shape benchmarks. We have added 145 new models for use as a separate training set, in order to standardise the training data used and provide a fairer comparison. We have also included experiments with the FAUST dataset of human scans. All participants of the previous benchmark study have taken part in the new tests reported here, many providing updated results using the new data. In addition, further participants have also taken part, and we provide extra analysis of the retrieval results. A total of 25 different shape retrieval methods.
Fine-grained Attention and Feature-sharing Generative Adversarial Networks for Single Image Super-Resolution
Nov 25, 2019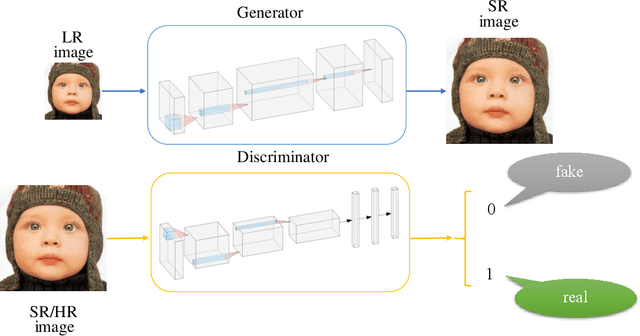
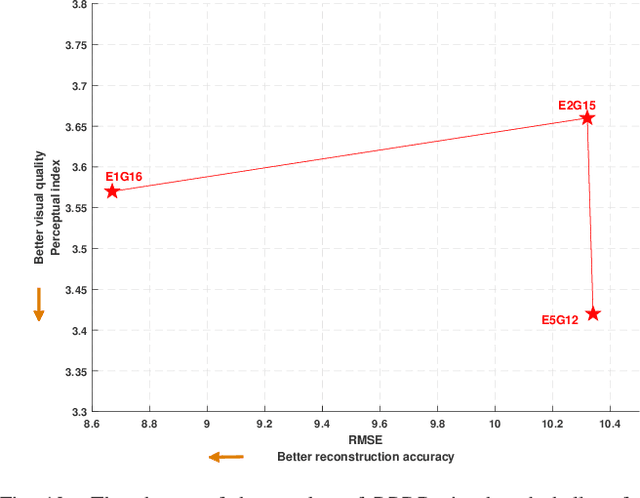
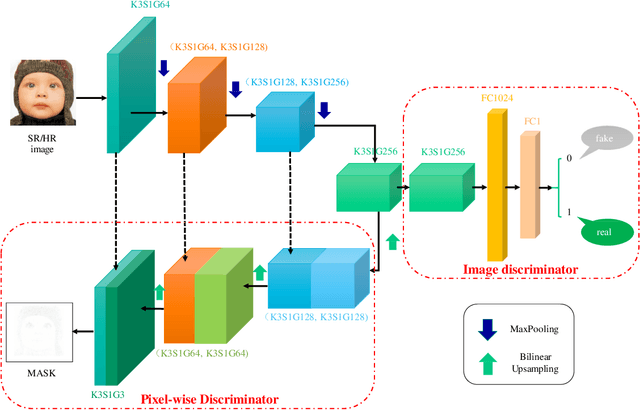
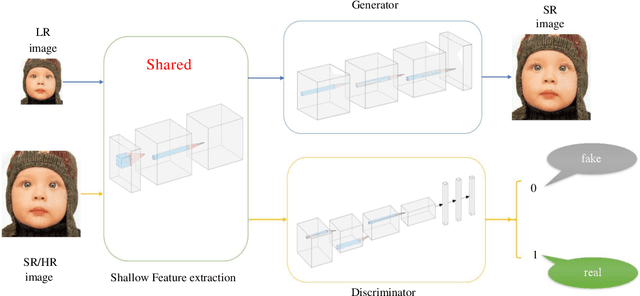
The traditional super-resolution methods that aim to minimize the mean square error usually produce the images with over-smoothed and blurry edges, due to the lose of high-frequency details. In this paper, we propose two novel techniques in the generative adversarial networks to produce photo-realistic images for image super-resolution. Firstly, instead of producing a single score to discriminate images between real and fake, we propose a variant, called Fine-grained Attention Generative Adversarial Network for image super-resolution (FASRGAN), to discriminate each pixel between real and fake. FASRGAN adopts a Unet-like network as the discriminator with two outputs: an image score and an image score map. The score map has the same spatial size as the HR/SR images, serving as the fine-grained attention to represent the degree of reconstruction difficulty for each pixel. Secondly, instead of using different networks for the generator and the discriminator in the SR problem, we use a feature-sharing network (Fs-SRGAN) for both the generator and the discriminator. By network sharing, certain information is shared between the generator and the discriminator, which in turn can improve the ability of producing high-quality images. Quantitative and visual comparisons with the state-of-the-art methods on the benchmark datasets demonstrate the superiority of our methods. The application of super-resolution images to object recognition further proves that the proposed methods endow the power to reconstruction capabilities and the excellent super-resolution effects.