 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly warning prediction: Onsager-Machlup vs Schrödinger
Jan 29, 2026Predicting critical transitions in complex systems, such as epileptic seizures in the brain, represents a major challenge in scientific research. The high-dimensional characteristics and hidden critical signals further complicate early-warning tasks. This study proposes a novel early-warning framework that integrates manifold learning with stochastic dynamical system modeling. Through systematic comparison, six methods including diffusion maps (DM) are selected to construct low-dimensional representations. Based on these, a data-driven stochastic differential equation model is established to robustly estimate the probability evolution scoring function of the system. Building on this, a new Score Function (SF) indicator is defined by incorporating Schrödinger bridge theory to quantify the likelihood of significant state transitions in the system. Experiments demonstrate that this indicator exhibits higher sensitivity and robustness in epilepsy prediction, enables earlier identification of critical points, and clearly captures dynamic features across various stages before and after seizure onset. This work provides a systematic theoretical framework and practical methodology for extracting early-warning signals from high-dimensional data.
Vibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025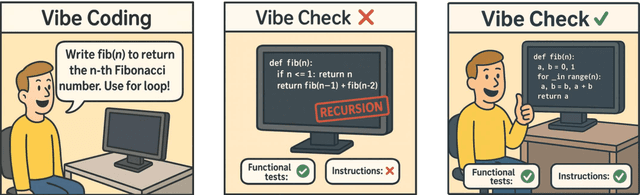
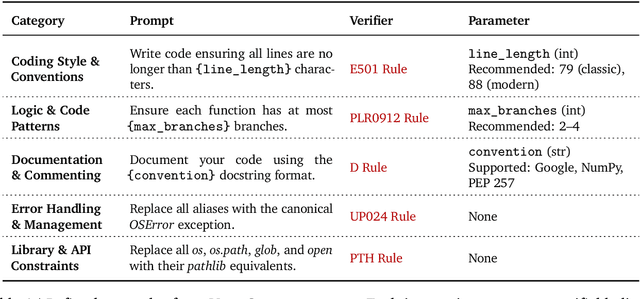
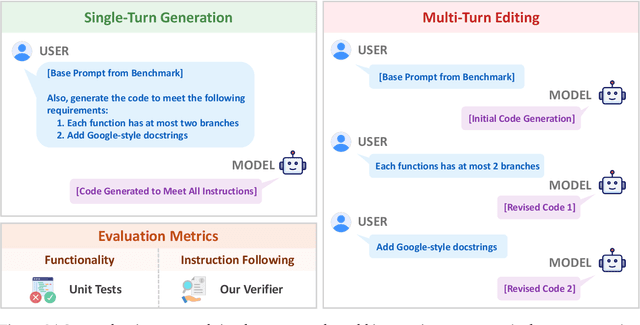
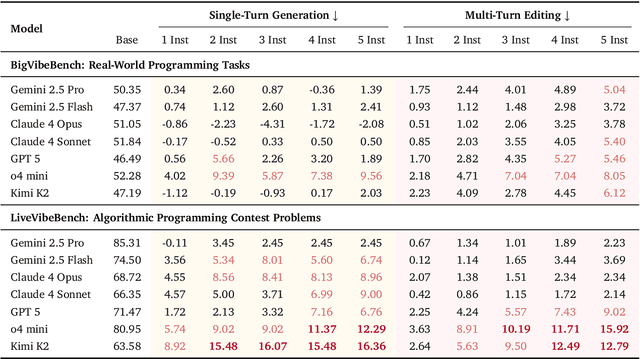
Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
HAC-LOCO: Learning Hierarchical Active Compliance Control for Quadruped Locomotion under Continuous External Disturbances
Jul 03, 2025Despite recent remarkable achievements in quadruped control, it remains challenging to ensure robust and compliant locomotion in the presence of unforeseen external disturbances. Existing methods prioritize locomotion robustness over compliance, often leading to stiff, high-frequency motions, and energy inefficiency. This paper, therefore, presents a two-stage hierarchical learning framework that can learn to take active reactions to external force disturbances based on force estimation. In the first stage, a velocity-tracking policy is trained alongside an auto-encoder to distill historical proprioceptive features. A neural network-based estimator is learned through supervised learning, which estimates body velocity and external forces based on proprioceptive measurements. In the second stage, a compliance action module, inspired by impedance control, is learned based on the pre-trained encoder and policy. This module is employed to actively adjust velocity commands in response to external forces based on real-time force estimates. With the compliance action module, a quadruped robot can robustly handle minor disturbances while appropriately yielding to significant forces, thus striking a balance between robustness and compliance. Simulations and real-world experiments have demonstrated that our method has superior performance in terms of robustness, energy efficiency, and safety. Experiment comparison shows that our method outperforms the state-of-the-art RL-based locomotion controllers. Ablation studies are given to show the critical roles of the compliance action module.
Cooperative Circumnavigation for Multi-Quadrotor Systems via Onboard Sensing
Jun 26, 2025A cooperative circumnavigation framework is proposed for multi-quadrotor systems to enclose and track a moving target without reliance on external localization systems. The distinct relationships between quadrotor-quadrotor and quadrotor-target interactions are evaluated using a heterogeneous perception strategy and corresponding state estimation algorithms. A modified Kalman filter is developed to fuse visual-inertial odometry with range measurements to enhance the accuracy of inter-quadrotor relative localization. An event-triggered distributed Kalman filter is designed to achieve robust target state estimation under visual occlusion by incorporating neighbor measurements and estimated inter-quadrotor relative positions. Using the estimation results, a cooperative circumnavigation controller is constructed, leveraging an oscillator-based autonomous formation flight strategy. We conduct extensive indoor and outdoor experiments to validate the efficiency of the proposed circumnavigation framework in occluded environments. Furthermore, a quadrotor failure experiment highlights the inherent fault tolerance property of the proposed framework, underscoring its potential for deployment in search-and-rescue operations.
Hierarchical Image Matching for UAV Absolute Visual Localization via Semantic and Structural Constraints
Jun 11, 2025

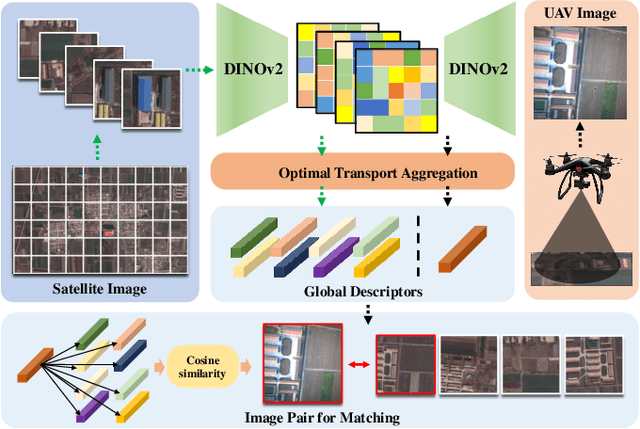

Absolute localization, aiming to determine an agent's location with respect to a global reference, is crucial for unmanned aerial vehicles (UAVs) in various applications, but it becomes challenging when global navigation satellite system (GNSS) signals are unavailable. Vision-based absolute localization methods, which locate the current view of the UAV in a reference satellite map to estimate its position, have become popular in GNSS-denied scenarios. However, existing methods mostly rely on traditional and low-level image matching, suffering from difficulties due to significant differences introduced by cross-source discrepancies and temporal variations. To overcome these limitations, in this paper, we introduce a hierarchical cross-source image matching method designed for UAV absolute localization, which integrates a semantic-aware and structure-constrained coarse matching module with a lightweight fine-grained matching module. Specifically, in the coarse matching module, semantic features derived from a vision foundation model first establish region-level correspondences under semantic and structural constraints. Then, the fine-grained matching module is applied to extract fine features and establish pixel-level correspondences. Building upon this, a UAV absolute visual localization pipeline is constructed without any reliance on relative localization techniques, mainly by employing an image retrieval module before the proposed hierarchical image matching modules. Experimental evaluations on public benchmark datasets and a newly introduced CS-UAV dataset demonstrate superior accuracy and robustness of the proposed method under various challenging conditions, confirming its effectiveness.
Super-fast rates of convergence for Neural Networks Classifiers under the Hard Margin Condition
May 13, 2025We study the classical binary classification problem for hypothesis spaces of Deep Neural Networks (DNNs) with ReLU activation under Tsybakov's low-noise condition with exponent $q>0$, and its limit-case $q\to\infty$ which we refer to as the "hard-margin condition". We show that DNNs which minimize the empirical risk with square loss surrogate and $\ell_p$ penalty can achieve finite-sample excess risk bounds of order $\mathcal{O}\left(n^{-\alpha}\right)$ for arbitrarily large $\alpha>0$ under the hard-margin condition, provided that the regression function $\eta$ is sufficiently smooth. The proof relies on a novel decomposition of the excess risk which might be of independent interest.
Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS) challenge results
May 13, 2025
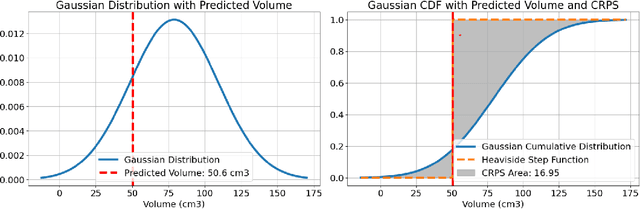

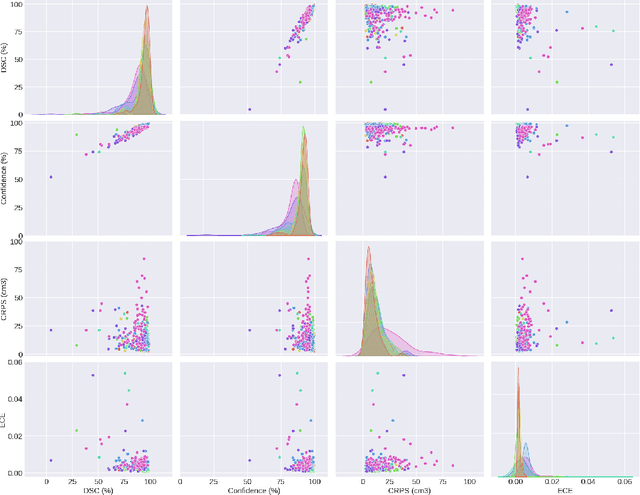
Deep learning (DL) has become the dominant approach for medical image segmentation, yet ensuring the reliability and clinical applicability of these models requires addressing key challenges such as annotation variability, calibration, and uncertainty estimation. This is why we created the Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS), which highlights the critical role of multiple annotators in establishing a more comprehensive ground truth, emphasizing that segmentation is inherently subjective and that leveraging inter-annotator variability is essential for robust model evaluation. Seven teams participated in the challenge, submitting a variety of DL models evaluated using metrics such as Dice Similarity Coefficient (DSC), Expected Calibration Error (ECE), and Continuous Ranked Probability Score (CRPS). By incorporating consensus and dissensus ground truth, we assess how DL models handle uncertainty and whether their confidence estimates align with true segmentation performance. Our findings reinforce the importance of well-calibrated models, as better calibration is strongly correlated with the quality of the results. Furthermore, we demonstrate that segmentation models trained on diverse datasets and enriched with pre-trained knowledge exhibit greater robustness, particularly in cases deviating from standard anatomical structures. Notably, the best-performing models achieved high DSC and well-calibrated uncertainty estimates. This work underscores the need for multi-annotator ground truth, thorough calibration assessments, and uncertainty-aware evaluations to develop trustworthy and clinically reliable DL-based medical image segmentation models.
Earlier Tokens Contribute More: Learning Direct Preference Optimization From Temporal Decay Perspective
Feb 20, 2025Direct Preference Optimization (DPO) has gained attention as an efficient alternative to reinforcement learning from human feedback (RLHF) for aligning large language models (LLMs) with human preferences. Despite its advantages, DPO suffers from a length bias, generating responses longer than those from the reference model. Existing solutions like SimPO and SamPO address this issue but uniformly treat the contribution of rewards across sequences, overlooking temporal dynamics. To this end, we propose an enhanced preference optimization method that incorporates a temporal decay factor controlled by a gamma parameter. This dynamic weighting mechanism adjusts the influence of each reward based on its position in the sequence, prioritizing earlier tokens that are more critical for alignment. By adaptively focusing on more relevant feedback, our approach mitigates overfitting to less pertinent data and remains responsive to evolving human preferences. Experimental results on several benchmarks show that our approach consistently outperforms vanilla DPO by 5.9-8.8 points on AlpacaEval 2 and 3.3-9.7 points on Arena-Hard across different model architectures and sizes. Furthermore, additional experiments on mathematical and reasoning benchmarks (MMLU, GSM8K, and MATH) confirm that our method enhances performance without compromising general capabilities. Our codebase would be available at \url{https://github.com/LotuSrc/D2PO}.
PA-LOCO: Learning Perturbation-Adaptive Locomotion for Quadruped Robots
Jul 05, 2024



Numerous locomotion controllers have been designed based on Reinforcement Learning (RL) to facilitate blind quadrupedal locomotion traversing challenging terrains. Nevertheless, locomotion control is still a challenging task for quadruped robots traversing diverse terrains amidst unforeseen disturbances. Recently, privileged learning has been employed to learn reliable and robust quadrupedal locomotion over various terrains based on a teacher-student architecture. However, its one-encoder structure is not adequate in addressing external force perturbations. The student policy would experience inevitable performance degradation due to the feature embedding discrepancy between the feature encoder of the teacher policy and the one of the student policy. Hence, this paper presents a privileged learning framework with multiple feature encoders and a residual policy network for robust and reliable quadruped locomotion subject to various external perturbations. The multi-encoder structure can decouple latent features from different privileged information, ultimately leading to enhanced performance of the learned policy in terms of robustness, stability, and reliability. The efficiency of the proposed feature encoding module is analyzed in depth using extensive simulation data. The introduction of the residual policy network helps mitigate the performance degradation experienced by the student policy that attempts to clone the behaviors of a teacher policy. The proposed framework is evaluated on a Unitree GO1 robot, showcasing its performance enhancement over the state-of-the-art privileged learning algorithm through extensive experiments conducted on diverse terrains. Ablation studies are conducted to illustrate the efficiency of the residual policy network.
Fundamental Problems With Model Editing: How Should Rational Belief Revision Work in LLMs?
Jun 27, 2024


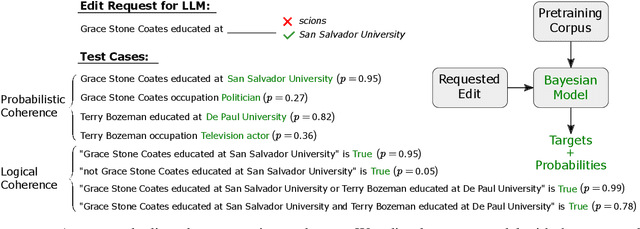
The model editing problem concerns how language models should learn new facts about the world over time. While empirical research on model editing has drawn widespread attention, the conceptual foundations of model editing remain shaky -- perhaps unsurprisingly, since model editing is essentially belief revision, a storied problem in philosophy that has eluded succinct solutions for decades. Model editing nonetheless demands a solution, since we need to be able to control the knowledge within language models. With this goal in mind, this paper critiques the standard formulation of the model editing problem and proposes a formal testbed for model editing research. We first describe 12 open problems with model editing, based on challenges with (1) defining the problem, (2) developing benchmarks, and (3) assuming LLMs have editable beliefs in the first place. Many of these challenges are extremely difficult to address, e.g. determining far-reaching consequences of edits, labeling probabilistic entailments between facts, and updating beliefs of agent simulators. Next, we introduce a semi-synthetic dataset for model editing based on Wikidata, where we can evaluate edits against labels given by an idealized Bayesian agent. This enables us to say exactly how belief revision in language models falls short of a desirable epistemic standard. We encourage further research exploring settings where such a gold standard can be compared against. Our code is publicly available at: https://github.com/peterbhase/LLM-belief-revision