 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks
Mar 27, 2025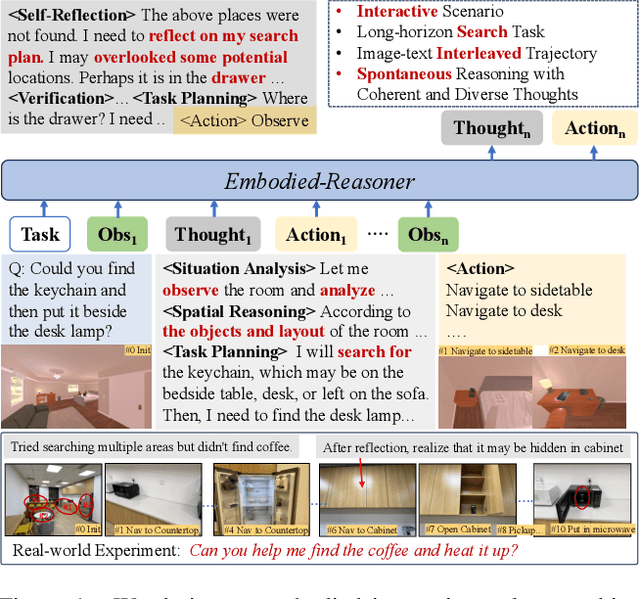

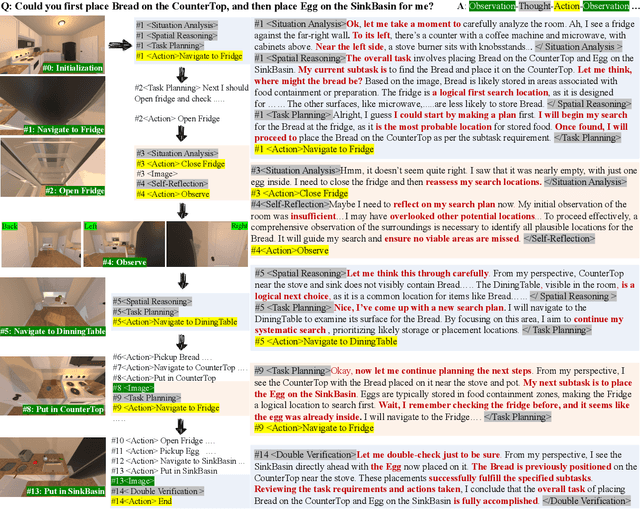
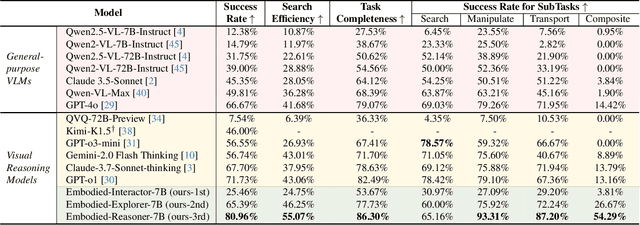
Recent advances in deep thinking models have demonstrated remarkable reasoning capabilities on mathematical and coding tasks. However, their effectiveness in embodied domains which require continuous interaction with environments through image action interleaved trajectories remains largely -unexplored. We present Embodied Reasoner, a model that extends o1 style reasoning to interactive embodied search tasks. Unlike mathematical reasoning that relies primarily on logical deduction, embodied scenarios demand spatial understanding, temporal reasoning, and ongoing self-reflection based on interaction history. To address these challenges, we synthesize 9.3k coherent Observation-Thought-Action trajectories containing 64k interactive images and 90k diverse thinking processes (analysis, spatial reasoning, reflection, planning, and verification). We develop a three-stage training pipeline that progressively enhances the model's capabilities through imitation learning, self-exploration via rejection sampling, and self-correction through reflection tuning. The evaluation shows that our model significantly outperforms those advanced visual reasoning models, e.g., it exceeds OpenAI o1, o3-mini, and Claude-3.7 by +9\%, 24\%, and +13\%. Analysis reveals our model exhibits fewer repeated searches and logical inconsistencies, with particular advantages in complex long-horizon tasks. Real-world environments also show our superiority while exhibiting fewer repeated searches and logical inconsistency cases.
Earlier Tokens Contribute More: Learning Direct Preference Optimization From Temporal Decay Perspective
Feb 20, 2025Direct Preference Optimization (DPO) has gained attention as an efficient alternative to reinforcement learning from human feedback (RLHF) for aligning large language models (LLMs) with human preferences. Despite its advantages, DPO suffers from a length bias, generating responses longer than those from the reference model. Existing solutions like SimPO and SamPO address this issue but uniformly treat the contribution of rewards across sequences, overlooking temporal dynamics. To this end, we propose an enhanced preference optimization method that incorporates a temporal decay factor controlled by a gamma parameter. This dynamic weighting mechanism adjusts the influence of each reward based on its position in the sequence, prioritizing earlier tokens that are more critical for alignment. By adaptively focusing on more relevant feedback, our approach mitigates overfitting to less pertinent data and remains responsive to evolving human preferences. Experimental results on several benchmarks show that our approach consistently outperforms vanilla DPO by 5.9-8.8 points on AlpacaEval 2 and 3.3-9.7 points on Arena-Hard across different model architectures and sizes. Furthermore, additional experiments on mathematical and reasoning benchmarks (MMLU, GSM8K, and MATH) confirm that our method enhances performance without compromising general capabilities. Our codebase would be available at \url{https://github.com/LotuSrc/D2PO}.