 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Confusion Expression in Large Language Models: Leveraging World Models toward Better Social Reasoning
Oct 09, 2025While large language models (LLMs) excel in mathematical and code reasoning, we observe they struggle with social reasoning tasks, exhibiting cognitive confusion, logical inconsistencies, and conflation between objective world states and subjective belief states. Through deteiled analysis of DeepSeek-R1's reasoning trajectories, we find that LLMs frequently encounter reasoning impasses and tend to output contradictory terms like "tricky" and "confused" when processing scenarios with multiple participants and timelines, leading to erroneous reasoning or infinite loops. The core issue is their inability to disentangle objective reality from agents' subjective beliefs. To address this, we propose an adaptive world model-enhanced reasoning mechanism that constructs a dynamic textual world model to track entity states and temporal sequences. It dynamically monitors reasoning trajectories for confusion indicators and promptly intervenes by providing clear world state descriptions, helping models navigate through cognitive dilemmas. The mechanism mimics how humans use implicit world models to distinguish between external events and internal beliefs. Evaluations on three social benchmarks demonstrate significant improvements in accuracy (e.g., +10% in Hi-ToM) while reducing computational costs (up to 33.8% token reduction), offering a simple yet effective solution for deploying LLMs in social contexts.
Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models
Aug 12, 2025Diffusion large language models (dLLMs) generate text through iterative denoising, yet current decoding strategies discard rich intermediate predictions in favor of the final output. Our work here reveals a critical phenomenon, temporal oscillation, where correct answers often emerge in the middle process, but are overwritten in later denoising steps. To address this issue, we introduce two complementary methods that exploit temporal consistency: 1) Temporal Self-Consistency Voting, a training-free, test-time decoding strategy that aggregates predictions across denoising steps to select the most consistent output; and 2) a post-training method termed Temporal Consistency Reinforcement, which uses Temporal Semantic Entropy (TSE), a measure of semantic stability across intermediate predictions, as a reward signal to encourage stable generations. Empirical results across multiple benchmarks demonstrate the effectiveness of our approach. Using the negative TSE reward alone, we observe a remarkable average improvement of 24.7% on the Countdown dataset over an existing dLLM. Combined with the accuracy reward, we achieve absolute gains of 2.0% on GSM8K, 4.3% on MATH500, 6.6% on SVAMP, and 25.3% on Countdown, respectively. Our findings underscore the untapped potential of temporal dynamics in dLLMs and offer two simple yet effective tools to harness them.
Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
Aug 07, 2025Graphical User Interface (GUI) grounding, the task of mapping natural language instructions to precise screen coordinates, is fundamental to autonomous GUI agents. While existing methods achieve strong performance through extensive supervised training or reinforcement learning with labeled rewards, they remain constrained by the cost and availability of pixel-level annotations. We observe that when models generate multiple predictions for the same GUI element, the spatial overlap patterns reveal implicit confidence signals that can guide more accurate localization. Leveraging this insight, we propose GUI-RC (Region Consistency), a test-time scaling method that constructs spatial voting grids from multiple sampled predictions to identify consensus regions where models show highest agreement. Without any training, GUI-RC improves accuracy by 2-3% across various architectures on ScreenSpot benchmarks. We further introduce GUI-RCPO (Region Consistency Policy Optimization), which transforms these consistency patterns into rewards for test-time reinforcement learning. By computing how well each prediction aligns with the collective consensus, GUI-RCPO enables models to iteratively refine their outputs on unlabeled data during inference. Extensive experiments demonstrate the generality of our approach: GUI-RC boosts Qwen2.5-VL-3B-Instruct from 80.11% to 83.57% on ScreenSpot-v2, while GUI-RCPO further improves it to 85.14% through self-supervised optimization. Our approach reveals the untapped potential of test-time scaling and test-time reinforcement learning for GUI grounding, offering a promising path toward more robust and data-efficient GUI agents.
OmniEAR: Benchmarking Agent Reasoning in Embodied Tasks
Aug 07, 2025Large language models excel at abstract reasoning but their capacity for embodied agent reasoning remains largely unexplored. We present OmniEAR, a comprehensive framework for evaluating how language models reason about physical interactions, tool usage, and multi-agent coordination in embodied tasks. Unlike existing benchmarks that provide predefined tool sets or explicit collaboration directives, OmniEAR requires agents to dynamically acquire capabilities and autonomously determine coordination strategies based on task demands. Through text-based environment representation, we model continuous physical properties and complex spatial relationships across 1,500 scenarios spanning household and industrial domains. Our systematic evaluation reveals severe performance degradation when models must reason from constraints: while achieving 85-96% success with explicit instructions, performance drops to 56-85% for tool reasoning and 63-85% for implicit collaboration, with compound tasks showing over 50% failure rates. Surprisingly, complete environmental information degrades coordination performance, indicating models cannot filter task-relevant constraints. Fine-tuning improves single-agent tasks dramatically (0.6% to 76.3%) but yields minimal multi-agent gains (1.5% to 5.5%), exposing fundamental architectural limitations. These findings demonstrate that embodied reasoning poses fundamentally different challenges than current models can address, establishing OmniEAR as a rigorous benchmark for evaluating and advancing embodied AI systems. Our code and data are included in the supplementary materials and will be open-sourced upon acceptance.
Cooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
Aug 07, 2025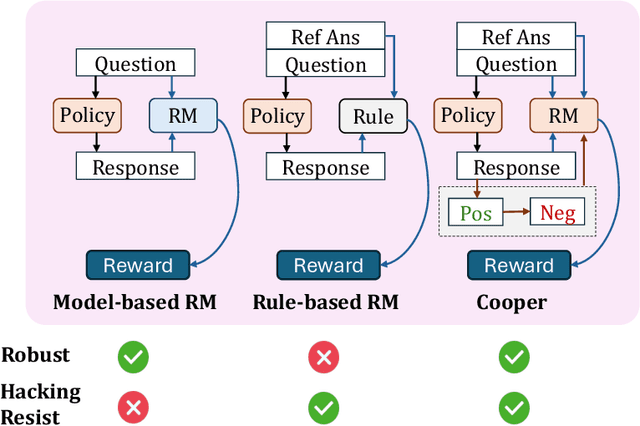



Large language models (LLMs) have demonstrated remarkable performance in reasoning tasks, where reinforcement learning (RL) serves as a key algorithm for enhancing their reasoning capabilities. Currently, there are two mainstream reward paradigms: model-based rewards and rule-based rewards. However, both approaches suffer from limitations: rule-based rewards lack robustness, while model-based rewards are vulnerable to reward hacking. To address these issues, we propose Cooper(Co-optimizing Policy Model and Reward Model), a RL framework that jointly optimizes both the policy model and the reward model. Cooper leverages the high precision of rule-based rewards when identifying correct responses, and dynamically constructs and selects positive-negative sample pairs for continued training the reward model. This design enhances robustness and mitigates the risk of reward hacking. To further support Cooper, we introduce a hybrid annotation strategy that efficiently and accurately generates training data for the reward model. We also propose a reference-based reward modeling paradigm, where the reward model takes a reference answer as input. Based on this design, we train a reward model named VerifyRM, which achieves higher accuracy on VerifyBench compared to other models of the same size. We conduct reinforcement learning using both VerifyRM and Cooper. Our experiments show that Cooper not only alleviates reward hacking but also improves end-to-end RL performance, for instance, achieving a 0.54% gain in average accuracy on Qwen2.5-1.5B-Instruct. Our findings demonstrate that dynamically updating reward model is an effective way to combat reward hacking, providing a reference for better integrating reward models into RL.
Dynamical Multimodal Fusion with Mixture-of-Experts for Localizations
Jul 02, 2025Multimodal fingerprinting is a crucial technique to sub-meter 6G integrated sensing and communications (ISAC) localization, but two hurdles block deployment: (i) the contribution each modality makes to the target position varies with the operating conditions such as carrier frequency, and (ii) spatial and fingerprint ambiguities markedly undermine localization accuracy, especially in non-line-of-sight (NLOS) scenarios. To solve these problems, we introduce SCADF-MoE, a spatial-context aware dynamic fusion network built on a soft mixture-of-experts backbone. SCADF-MoE first clusters neighboring points into short trajectories to inject explicit spatial context. Then, it adaptively fuses channel state information, angle of arrival profile, distance, and gain through its learnable MoE router, so that the most reliable cues dominate at each carrier band. The fused representation is fed to a modality-task MoE that simultaneously regresses the coordinates of every vertex in the trajectory and its centroid, thereby exploiting inter-point correlations. Finally, an auxiliary maximum-mean-discrepancy loss enforces expert diversity and mitigates gradient interference, stabilizing multi-task training. On three real urban layouts and three carrier bands (2.6, 6, 28 GHz), the model delivers consistent sub-meter MSE and halves unseen-NLOS error versus the best prior work. To our knowledge, this is the first work that leverages large-scale multimodal MoE for frequency-robust ISAC localization.
TimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs' Social Intelligence
May 30, 2025Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs' cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs' social intelligence. In our experiments, we systematically explore improving LLMs' social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs' social intelligence has uncovered several valuable insights.
ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models
May 27, 2025



Vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and reasoning about visual content, but significant challenges persist in tasks requiring cross-viewpoint understanding and spatial reasoning. We identify a critical limitation: current VLMs excel primarily at egocentric spatial reasoning (from the camera's perspective) but fail to generalize to allocentric viewpoints when required to adopt another entity's spatial frame of reference. We introduce ViewSpatial-Bench, the first comprehensive benchmark designed specifically for multi-viewpoint spatial localization recognition evaluation across five distinct task types, supported by an automated 3D annotation pipeline that generates precise directional labels. Comprehensive evaluation of diverse VLMs on ViewSpatial-Bench reveals a significant performance disparity: models demonstrate reasonable performance on camera-perspective tasks but exhibit reduced accuracy when reasoning from a human viewpoint. By fine-tuning VLMs on our multi-perspective spatial dataset, we achieve an overall performance improvement of 46.24% across tasks, highlighting the efficacy of our approach. Our work establishes a crucial benchmark for spatial intelligence in embodied AI systems and provides empirical evidence that modeling 3D spatial relationships enhances VLMs' corresponding spatial comprehension capabilities.
Let LLMs Break Free from Overthinking via Self-Braking Tuning
May 21, 2025Large reasoning models (LRMs), such as OpenAI o1 and DeepSeek-R1, have significantly enhanced their reasoning capabilities by generating longer chains of thought, demonstrating outstanding performance across a variety of tasks. However, this performance gain comes at the cost of a substantial increase in redundant reasoning during the generation process, leading to high computational overhead and exacerbating the issue of overthinking. Although numerous existing approaches aim to address the problem of overthinking, they often rely on external interventions. In this paper, we propose a novel framework, Self-Braking Tuning (SBT), which tackles overthinking from the perspective of allowing the model to regulate its own reasoning process, thus eliminating the reliance on external control mechanisms. We construct a set of overthinking identification metrics based on standard answers and design a systematic method to detect redundant reasoning. This method accurately identifies unnecessary steps within the reasoning trajectory and generates training signals for learning self-regulation behaviors. Building on this foundation, we develop a complete strategy for constructing data with adaptive reasoning lengths and introduce an innovative braking prompt mechanism that enables the model to naturally learn when to terminate reasoning at an appropriate point. Experiments across mathematical benchmarks (AIME, AMC, MATH500, GSM8K) demonstrate that our method reduces token consumption by up to 60% while maintaining comparable accuracy to unconstrained models.
Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning
May 21, 2025Large language models (LLMs) have achieved remarkable progress on mathematical tasks through Chain-of-Thought (CoT) reasoning. However, existing mathematical CoT datasets often suffer from Thought Leaps due to experts omitting intermediate steps, which negatively impacts model learning and generalization. We propose the CoT Thought Leap Bridge Task, which aims to automatically detect leaps and generate missing intermediate reasoning steps to restore the completeness and coherence of CoT. To facilitate this, we constructed a specialized training dataset called ScaleQM+, based on the structured ScaleQuestMath dataset, and trained CoT-Bridge to bridge thought leaps. Through comprehensive experiments on mathematical reasoning benchmarks, we demonstrate that models fine-tuned on bridged datasets consistently outperform those trained on original datasets, with improvements of up to +5.87% on NuminaMath. Our approach effectively enhances distilled data (+3.02%) and provides better starting points for reinforcement learning (+3.1%), functioning as a plug-and-play module compatible with existing optimization techniques. Furthermore, CoT-Bridge demonstrate improved generalization to out-of-domain logical reasoning tasks, confirming that enhancing reasoning completeness yields broadly applicable benefits.