 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions
Jun 12, 2026Phone agents are increasingly expected to complete real mobile workflows rather than merely predict the next screen action. However, much of the current mobile-agent literature still evaluates agents primarily as GUI controllers that observe a screen, emit taps and swipes, and are scored by target app state. Real phone-use tasks are broader: they require deciding when to use app GUIs, device-side commands, or structured tools, while leaving evidence that the intended side effect actually occurred. We introduce PhoneHarness, a mixed-action benchmark and execution harness for studying phone-use agents on verifiable mobile workflows. PhoneHarness runs a device-side agent loop over GUI, CLI, and host-side tool actions, combining deterministic action routing with bounded GUI delegation and auditable execution traces. Its benchmark, PhoneHarness Bench, evaluates whether agents complete tasks with observable side effects, not only whether they produce plausible final answers. On the annotated evaluation split, PhoneHarness reaches a 75.0% pass rate, outperforming the strongest non-PhoneHarness settings by 12.9 percentage points. PhoneHarness and PhoneHarness Bench therefore play distinct but mutually dependent roles: the harness makes mixed phone workflows executable, while the benchmark measures whether agents can use that harness reliably and safely. Our findings suggest that reliable phone automation depends on action-surface routing and verifiable execution, not only visual GUI control.
CoralBay: A Self-Supervised CT Foundation Model
Jun 02, 2026Self-supervised learning has enabled large-scale pre-training on 2D natural images, producing general-purpose visual representations that transfer effectively across tasks. However, many medical imaging modalities, such as CT scans, are inherently three-dimensional and differ fundamentally from natural images in both structure and semantics. Volumetric modalities capture spatial continuity, organ anatomy, and intensity-based tissue properties (e.g., Hounsfield Units), which are not adequately modeled by 2D pre-training. To bridge this gap, we introduce CoralBay, a self-distillation framework that extends DINO by using a hierarchical 3D Swin backbone and applying self-distillation to concatenated multi-scale features, enabling data-efficient self-supervised learning of rich spatial representations that encode both global semantics and fine-grained local structure. As a result, CoralBay transfers effectively to a wide range of downstream radiological tasks, demonstrating strong and consistent performance across diverse anatomical targets. In addition, we contribute to the open-source \eva framework by introducing a public, reproducible 3D radiology leaderboard that unifies multiple datasets and establishes a standardized benchmark for evaluating volumetric representation learning methods.
PhoneWorld: Scaling Phone-Use Agent Environments
May 28, 2026A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
UI-Zoomer: Uncertainty-Driven Adaptive Zoom-In for GUI Grounding
Apr 15, 2026GUI grounding, which localizes interface elements from screenshots given natural language queries, remains challenging for small icons and dense layouts. Test-time zoom-in methods improve localization by cropping and re-running inference at higher resolution, but apply cropping uniformly across all instances with fixed crop sizes, ignoring whether the model is actually uncertain on each case. We propose \textbf{UI-Zoomer}, a training-free adaptive zoom-in framework that treats both the trigger and scale of zoom-in as a prediction uncertainty quantification problem. A confidence-aware gate fuses spatial consensus among stochastic candidates with token-level generation confidence to selectively trigger zoom-in only when localization is uncertain. When triggered, an uncertainty-driven crop sizing module decomposes prediction variance into inter-sample positional spread and intra-sample box extent, deriving a per-instance crop radius via the law of total variance. Extensive experiments on ScreenSpot-Pro, UI-Vision, and ScreenSpot-v2 demonstrate consistent improvements over strong baselines across multiple model architectures, achieving gains of up to +13.4\%, +10.3\%, and +4.2\% respectively, with no additional training required.
UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
Apr 15, 2026MLLM-based GUI agents have demonstrated strong capabilities in complex user interface interaction tasks. However, long-horizon scenarios remain challenging, as these agents are burdened with tasks beyond their intrinsic capabilities, suffering from memory degradation, progress confusion, and math hallucination. To address these challenges, we present UI-Copilot, a collaborative framework where the GUI agent focuses on task execution while a lightweight copilot provides on-demand assistance for memory retrieval and numerical computation. We introduce memory decoupling to separate persistent observations from transient execution context, and train the policy agent to selectively invoke the copilot as Retriever or Calculator based on task demands. To enable effective tool invocation learning, we propose Tool-Integrated Policy Optimization (TIPO), which separately optimizes tool selection through single-turn prediction and task execution through on-policy multi-turn rollouts. Experimental results show that UI-Copilot-7B achieves state-of-the-art performance on challenging MemGUI-Bench, outperforming strong 7B-scale GUI agents such as GUI-Owl-7B and UI-TARS-1.5-7B. Moreover, UI-Copilot-7B delivers a 17.1% absolute improvement on AndroidWorld over the base Qwen model, highlighting UI-Copilot's strong generalization to real-world GUI tasks.
ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
Apr 13, 2026GUI agents drive applications through their visual interfaces instead of programmatic APIs, interacting with arbitrary software via taps, swipes, and keystrokes, reaching a long tail of applications that CLI-based agents cannot. Yet progress in this area is bottlenecked less by modeling capacity than by the absence of a coherent full-stack infrastructure: online RL training suffers from environment instability and closed pipelines, evaluation protocols drift silently across works, and trained agents rarely reach real users on real devices. We present \textbf{ClawGUI}, an open-source framework addressing these three gaps within a single harness. \textbf{ClawGUI-RL} provides the first open-source GUI agent RL infrastructure with validated support for both parallel virtual environments and real physical devices, integrating GiGPO with a Process Reward Model for dense step-level supervision. \textbf{ClawGUI-Eval} enforces a fully standardized evaluation pipeline across 6 benchmarks and 11+ models, achieving 95.8\% reproduction against official baselines. \textbf{ClawGUI-Agent} brings trained agents to Android, HarmonyOS, and iOS through 12+ chat platforms with hybrid CLI-GUI control and persistent personalized memory. Trained end to end within this pipeline, \textbf{ClawGUI-2B} achieves 17.1\% Success Rate on MobileWorld GUI-Only, outperforming the same-scale MAI-UI-2B baseline by 6.0\%.
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Apr 09, 2026Personalized mobile agents that infer user preferences and calibrate proactive assistance hold great promise as everyday digital assistants, yet existing benchmarks fail to capture what this requires. Prior work evaluates preference recovery from static histories or intent prediction from fixed contexts. Neither tests whether an agent can elicit missing preferences through interaction, nor whether it can decide when to intervene, seek consent, or remain silent in a live GUI environment. We introduce KnowU-Bench, an online benchmark for personalized mobile agents built on a reproducible Android emulation environment, covering 42 general GUI tasks, 86 personalized tasks, and 64 proactive tasks. Unlike prior work that treats user preferences as static context, KnowU-Bench hides the user profile from the agent and exposes only behavioral logs, forcing genuine preference inference rather than context lookup. To support multi-turn preference elicitation, it instantiates an LLM-driven user simulator grounded in structured profiles, enabling realistic clarification dialogues and proactive consent handling. Beyond personalization, KnowU-Bench provides comprehensive evaluation of the complete proactive decision chain, including grounded GUI execution, consent negotiation, and post-rejection restraint, evaluated through a hybrid protocol combining rule-based verification with LLM-as-a-Judge scoring. Our experiments reveal a striking degradation: agents that excel at explicit task execution fall below 50% under vague instructions requiring user preference inference or intervention calibration, even for frontier models like Claude Sonnet 4.6. The core bottlenecks are not GUI navigation but preference acquisition and intervention calibration, exposing a fundamental gap between competent interface operation and trustworthy personal assistance.
Unpaired Cross-Domain Calibration of DMSP to VIIRS Nighttime Light Data Based on CUT Network
Mar 17, 2026Defense Meteorological Satellite Program (DMSP-OLS) and Suomi National Polar-orbiting Partnership (SNPP-VIIRS) nighttime light (NTL) data are vital for monitoring urbanization, yet sensor incompatibilities hinder long-term analysis. This study proposes a cross-sensor calibration method using Contrastive Unpaired Translation (CUT) network to transform DMSP data into VIIRS-like format, correcting DMSP defects. The method employs multilayer patch-wise contrastive learning to maximize mutual information between corresponding patches, preserving content consistency while learning cross-domain similarity. Utilizing 2012-2013 overlapping data for training, the network processes 1992-2013 DMSP imagery to generate enhanced VIIRS-style raster data. Validation results demonstrate that generated VIIRS-like data exhibits high consistency with actual VIIRS observations (R-squared greater than 0.87) and socioeconomic indicators. This approach effectively resolves cross-sensor data fusion issues and calibrates DMSP defects, providing reliable attempt for extended NTL time-series.
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
Dec 18, 2025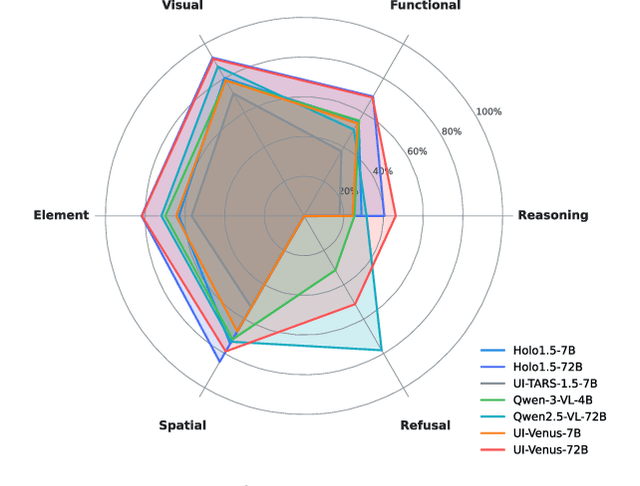
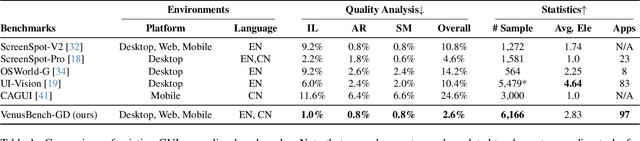
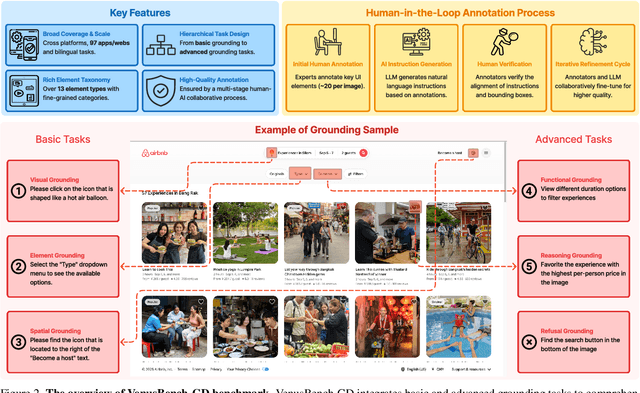
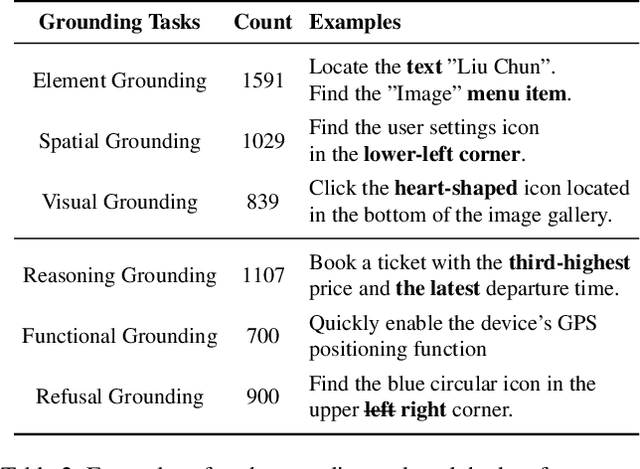
GUI grounding is a critical component in building capable GUI agents. However, existing grounding benchmarks suffer from significant limitations: they either provide insufficient data volume and narrow domain coverage, or focus excessively on a single platform and require highly specialized domain knowledge. In this work, we present VenusBench-GD, a comprehensive, bilingual benchmark for GUI grounding that spans multiple platforms, enabling hierarchical evaluation for real-word applications. VenusBench-GD contributes as follows: (i) we introduce a large-scale, cross-platform benchmark with extensive coverage of applications, diverse UI elements, and rich annotated data, (ii) we establish a high-quality data construction pipeline for grounding tasks, achieving higher annotation accuracy than existing benchmarks, and (iii) we extend the scope of element grounding by proposing a hierarchical task taxonomy that divides grounding into basic and advanced categories, encompassing six distinct subtasks designed to evaluate models from complementary perspectives. Our experimental findings reveal critical insights: general-purpose multimodal models now match or even surpass specialized GUI models on basic grounding tasks. In contrast, advanced tasks, still favor GUI-specialized models, though they exhibit significant overfitting and poor robustness. These results underscore the necessity of comprehensive, multi-tiered evaluation frameworks.
Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
Aug 07, 2025Graphical User Interface (GUI) grounding, the task of mapping natural language instructions to precise screen coordinates, is fundamental to autonomous GUI agents. While existing methods achieve strong performance through extensive supervised training or reinforcement learning with labeled rewards, they remain constrained by the cost and availability of pixel-level annotations. We observe that when models generate multiple predictions for the same GUI element, the spatial overlap patterns reveal implicit confidence signals that can guide more accurate localization. Leveraging this insight, we propose GUI-RC (Region Consistency), a test-time scaling method that constructs spatial voting grids from multiple sampled predictions to identify consensus regions where models show highest agreement. Without any training, GUI-RC improves accuracy by 2-3% across various architectures on ScreenSpot benchmarks. We further introduce GUI-RCPO (Region Consistency Policy Optimization), which transforms these consistency patterns into rewards for test-time reinforcement learning. By computing how well each prediction aligns with the collective consensus, GUI-RCPO enables models to iteratively refine their outputs on unlabeled data during inference. Extensive experiments demonstrate the generality of our approach: GUI-RC boosts Qwen2.5-VL-3B-Instruct from 80.11% to 83.57% on ScreenSpot-v2, while GUI-RCPO further improves it to 85.14% through self-supervised optimization. Our approach reveals the untapped potential of test-time scaling and test-time reinforcement learning for GUI grounding, offering a promising path toward more robust and data-efficient GUI agents.