 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAIROS: Unified Training for Universal Non-Autoregressive Time Series Forecasting
Oct 02, 2025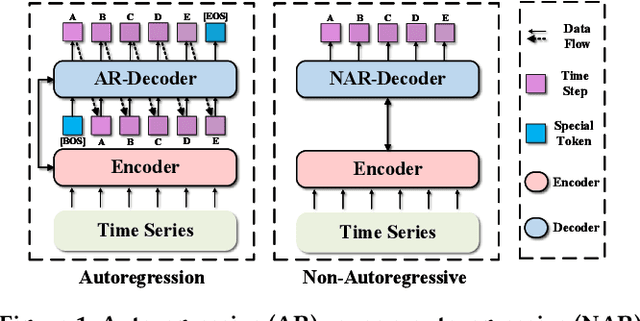

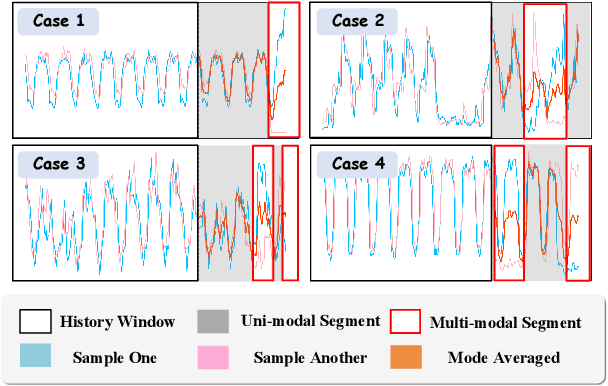
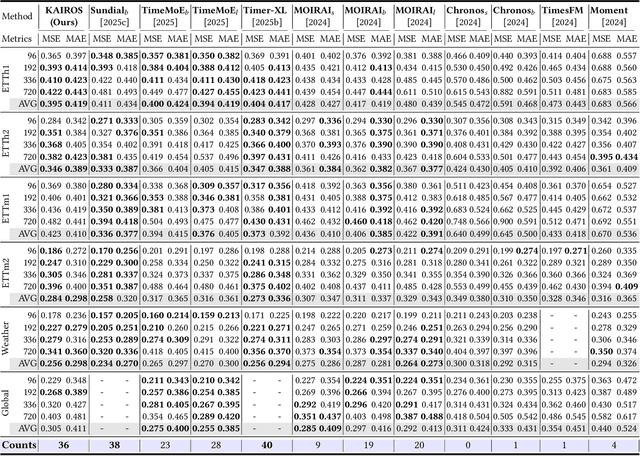
In the World Wide Web, reliable time series forecasts provide the forward-looking signals that drive resource planning, cache placement, and anomaly response, enabling platforms to operate efficiently as user behavior and content distributions evolve. Compared with other domains, time series forecasting for Web applications requires much faster responsiveness to support real-time decision making. We present KAIROS, a non-autoregressive time series forecasting framework that directly models segment-level multi-peak distributions. Unlike autoregressive approaches, KAIROS avoids error accumulation and achieves just-in-time inference, while improving over existing non-autoregressive models that collapse to over-smoothed predictions. Trained on the large-scale corpus, KAIROS demonstrates strong zero-shot generalization on six widely used benchmarks, delivering forecasting performance comparable to state-of-the-art foundation models with similar scale, at a fraction of their inference cost. Beyond empirical results, KAIROS highlights the importance of non-autoregressive design as a scalable paradigm for foundation models in time series.
AIGCBench: Comprehensive Evaluation of Image-to-Video Content Generated by AI
Jan 08, 2024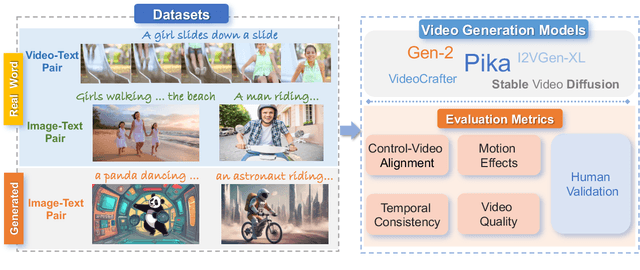
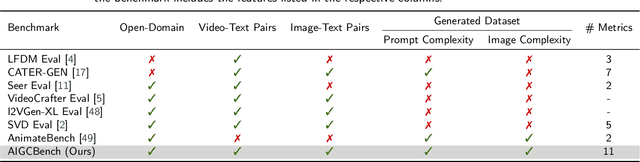
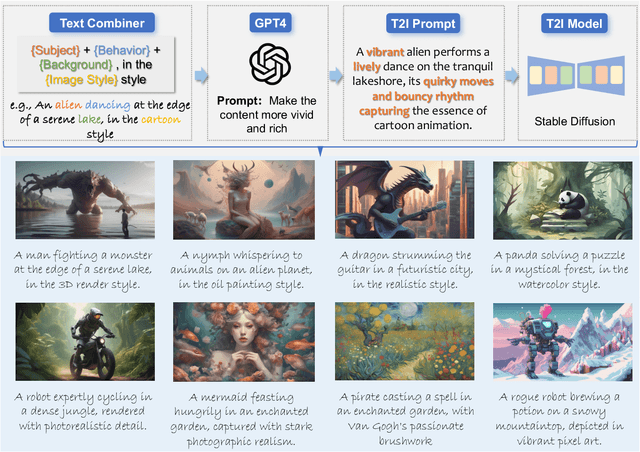
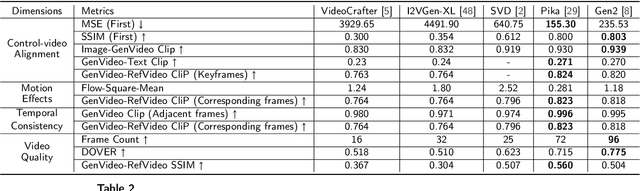
The burgeoning field of Artificial Intelligence Generated Content (AIGC) is witnessing rapid advancements, particularly in video generation. This paper introduces AIGCBench, a pioneering comprehensive and scalable benchmark designed to evaluate a variety of video generation tasks, with a primary focus on Image-to-Video (I2V) generation. AIGCBench tackles the limitations of existing benchmarks, which suffer from a lack of diverse datasets, by including a varied and open-domain image-text dataset that evaluates different state-of-the-art algorithms under equivalent conditions. We employ a novel text combiner and GPT-4 to create rich text prompts, which are then used to generate images via advanced Text-to-Image models. To establish a unified evaluation framework for video generation tasks, our benchmark includes 11 metrics spanning four dimensions to assess algorithm performance. These dimensions are control-video alignment, motion effects, temporal consistency, and video quality. These metrics are both reference video-dependent and video-free, ensuring a comprehensive evaluation strategy. The evaluation standard proposed correlates well with human judgment, providing insights into the strengths and weaknesses of current I2V algorithms. The findings from our extensive experiments aim to stimulate further research and development in the I2V field. AIGCBench represents a significant step toward creating standardized benchmarks for the broader AIGC landscape, proposing an adaptable and equitable framework for future assessments of video generation tasks. We have open-sourced the dataset and evaluation code on the project website: https://www.benchcouncil.org/AIGCBench.
DLCA-Recon: Dynamic Loose Clothing Avatar Reconstruction from Monocular Videos
Dec 20, 2023



Reconstructing a dynamic human with loose clothing is an important but difficult task. To address this challenge, we propose a method named DLCA-Recon to create human avatars from monocular videos. The distance from loose clothing to the underlying body rapidly changes in every frame when the human freely moves and acts. Previous methods lack effective geometric initialization and constraints for guiding the optimization of deformation to explain this dramatic change, resulting in the discontinuous and incomplete reconstruction surface. To model the deformation more accurately, we propose to initialize an estimated 3D clothed human in the canonical space, as it is easier for deformation fields to learn from the clothed human than from SMPL. With both representations of explicit mesh and implicit SDF, we utilize the physical connection information between consecutive frames and propose a dynamic deformation field (DDF) to optimize deformation fields. DDF accounts for contributive forces on loose clothing to enhance the interpretability of deformations and effectively capture the free movement of loose clothing. Moreover, we propagate SMPL skinning weights to each individual and refine pose and skinning weights during the optimization to improve skinning transformation. Based on more reasonable initialization and DDF, we can simulate real-world physics more accurately. Extensive experiments on public and our own datasets validate that our method can produce superior results for humans with loose clothing compared to the SOTA methods.
Hierarchical Masked 3D Diffusion Model for Video Outpainting
Sep 05, 2023


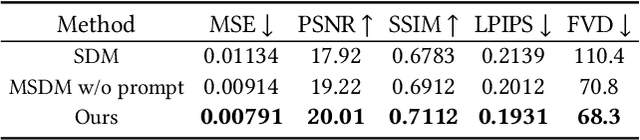
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks. More results are provided at our https://fanfanda.github.io/M3DDM/.
Quality at the Tail
Dec 25, 2022



Practical applications employing deep learning must guarantee inference quality. However, we found that the inference quality of state-of-the-art and state-of-the-practice in practical applications has a long tail distribution. In the real world, many tasks have strict requirements for the quality of deep learning inference, such as safety-critical and mission-critical tasks. The fluctuation of inference quality seriously affects its practical applications, and the quality at the tail may lead to severe consequences. State-of-the-art and state-of-the-practice with outstanding inference quality designed and trained under loose constraints still have poor inference quality under constraints with practical application significance. On the one hand, the neural network models must be deployed on complex systems with limited resources. On the other hand, safety-critical and mission-critical tasks need to meet more metric constraints while ensuring high inference quality. We coin a new term, ``tail quality,'' to characterize this essential requirement and challenge. We also propose a new metric, ``X-Critical-Quality,'' to measure the inference quality under certain constraints. This article reveals factors contributing to the failure of using state-of-the-art and state-of-the-practice algorithms and systems in real scenarios. Therefore, we call for establishing innovative methodologies and tools to tackle this enormous challenge.
Shift-and-Balance Attention
Mar 24, 2021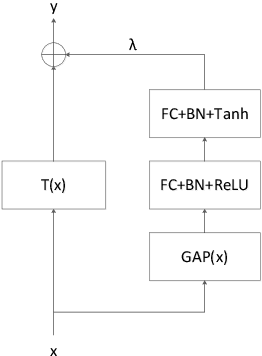
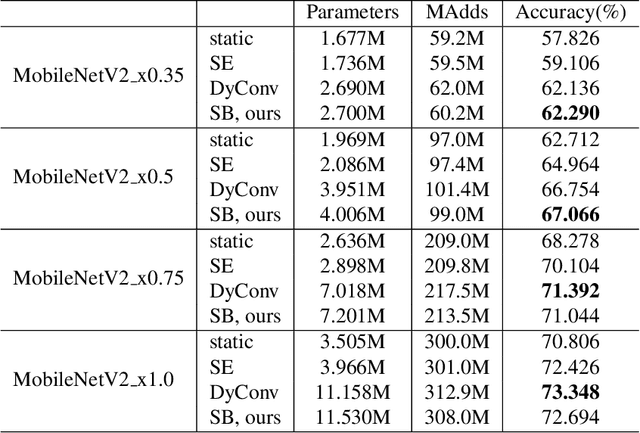
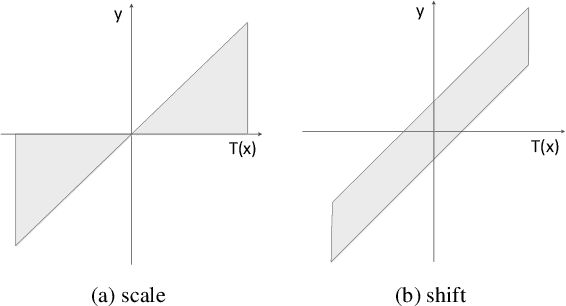
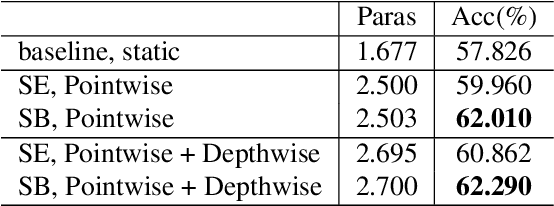
Attention is an effective mechanism to improve the deep model capability. Squeeze-and-Excite (SE) introduces a light-weight attention branch to enhance the network's representational power. The attention branch is gated using the Sigmoid function and multiplied by the feature map's trunk branch. It is too sensitive to coordinate and balance the trunk and attention branches' contributions. To control the attention branch's influence, we propose a new attention method, called Shift-and-Balance (SB). Different from Squeeze-and-Excite, the attention branch is regulated by the learned control factor to control the balance, then added into the feature map's trunk branch. Experiments show that Shift-and-Balance attention significantly improves the accuracy compared to Squeeze-and-Excite when applied in more layers, increasing more size and capacity of a network. Moreover, Shift-and-Balance attention achieves better or close accuracy compared to the state-of-art Dynamic Convolution.
An Isolated Data Island Benchmark Suite for Federated Learning
Aug 17, 2020
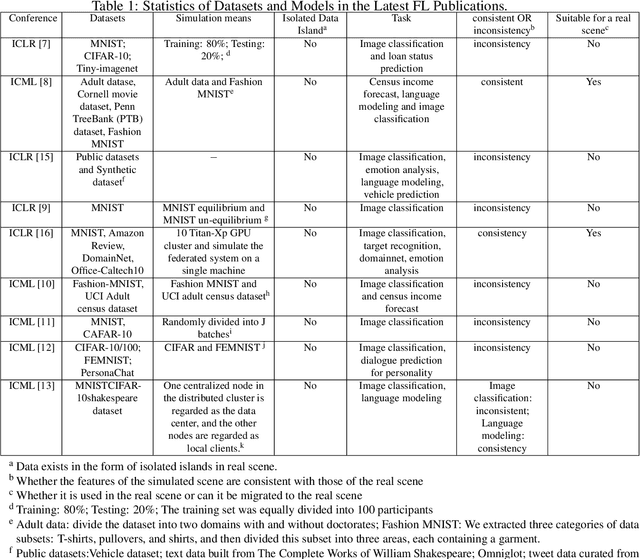
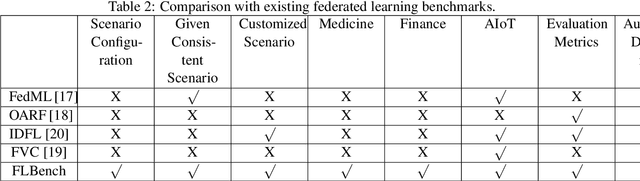
Federated learning (FL) is a new machine learning paradigm, the goal of which is to build a machine learning model based on data sets distributed on multiple devices--so called Isolated Data Island--while keeping their data secure and private. Most existing work manually splits commonly-used public datasets into partitions to simulate real-world Isolated Data Island while failing to capture the intrinsic characteristics of real-world domain data, like medicine, finance or AIoT. To bridge this huge gap, this paper presents and characterizes an Isolated Data Island benchmark suite, named FLBench, for benchmarking federated learning algorithms. FLBench contains three domains: medical, financial and AIoT. By configuring various domains, FLBench is qualified for evaluating the important research aspects of federated learning, and hence become a promising platform for developing novel federated learning algorithms. Finally, FLBench is fully open-sourced and in fast-evolution. We package it as an automated deployment tool. The benchmark suite will be publicly available from http://www.benchcouncil.org/FLBench.
Finet: Using Fine-grained Batch Normalization to Train Light-weight Neural Networks
May 14, 2020
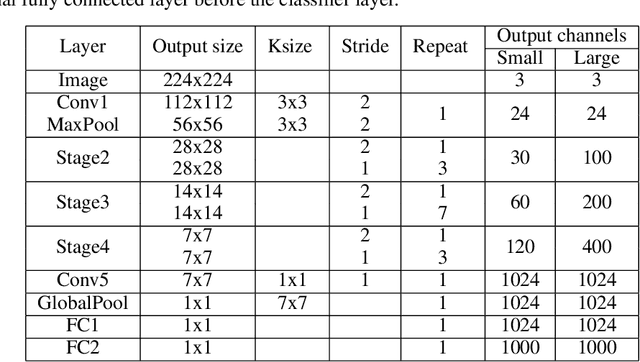

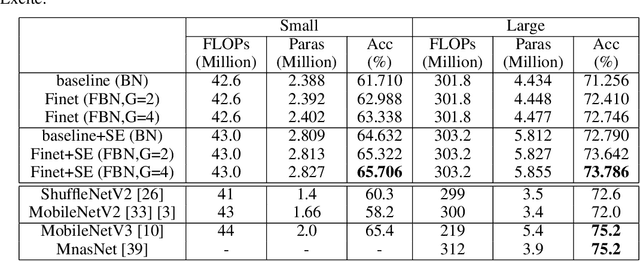
To build light-weight network, we propose a new normalization, Fine-grained Batch Normalization (FBN). Different from Batch Normalization (BN), which normalizes the final summation of the weighted inputs, FBN normalizes the intermediate state of the summation. We propose a novel light-weight network based on FBN, called Finet. At training time, the convolutional layer with FBN can be seen as an inverted bottleneck mechanism. FBN can be fused into convolution at inference time. After fusion, Finet uses the standard convolution with equal channel width, thus makes the inference more efficient. On ImageNet classification dataset, Finet achieves the state-of-art performance (65.706% accuracy with 43M FLOPs, and 73.786% accuracy with 303M FLOPs), Moreover, experiments show that Finet is more efficient than other state-of-art light-weight networks.
Comparison and Benchmarking of AI Models and Frameworks on Mobile Devices
May 07, 2020
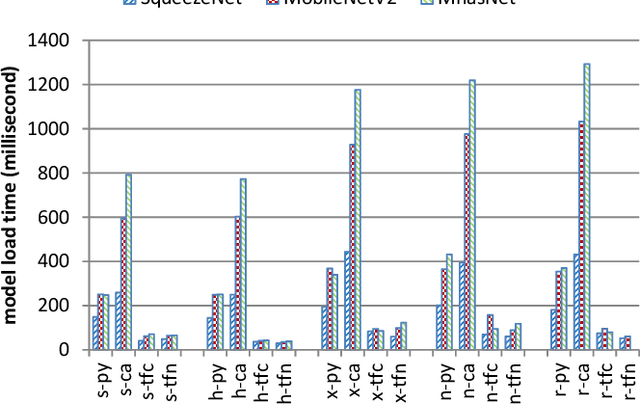

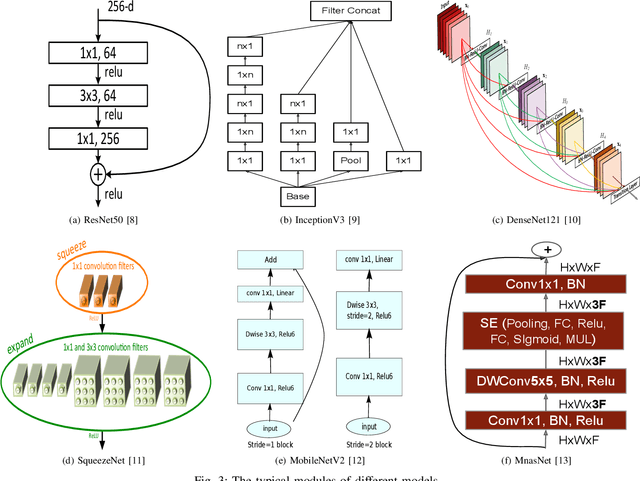
Due to increasing amounts of data and compute resources, deep learning achieves many successes in various domains. The application of deep learning on the mobile and embedded devices is taken more and more attentions, benchmarking and ranking the AI abilities of mobile and embedded devices becomes an urgent problem to be solved. Considering the model diversity and framework diversity, we propose a benchmark suite, AIoTBench, which focuses on the evaluation of the inference abilities of mobile and embedded devices. AIoTBench covers three typical heavy-weight networks: ResNet50, InceptionV3, DenseNet121, as well as three light-weight networks: SqueezeNet, MobileNetV2, MnasNet. Each network is implemented by three frameworks which are designed for mobile and embedded devices: Tensorflow Lite, Caffe2, Pytorch Mobile. To compare and rank the AI capabilities of the devices, we propose two unified metrics as the AI scores: Valid Images Per Second (VIPS) and Valid FLOPs Per Second (VOPS). Currently, we have compared and ranked 5 mobile devices using our benchmark. This list will be extended and updated soon after.
AIBench: Scenario-distilling AI Benchmarking
May 06, 2020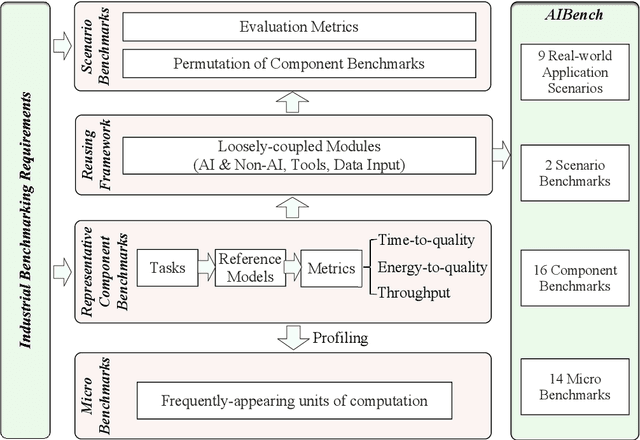

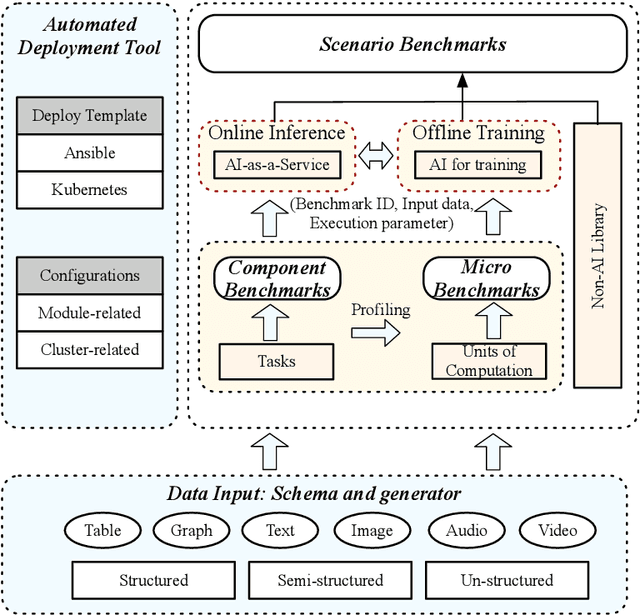
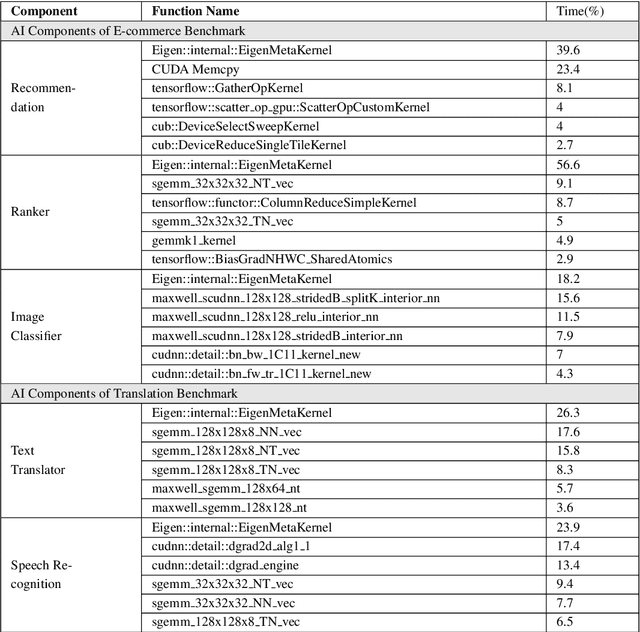
Real-world application scenarios like modern Internet services consist of diversity of AI and non-AI modules with very long and complex execution paths. Using component or micro AI benchmarks alone can lead to error-prone conclusions. This paper proposes a scenario-distilling AI benchmarking methodology. Instead of using real-world applications, we propose the permutations of essential AI and non-AI tasks as a scenario-distilling benchmark. We consider scenario-distilling benchmarks, component and micro benchmarks as three indispensable parts of a benchmark suite. Together with seventeen industry partners, we identify nine important real-world application scenarios. We design and implement a highly extensible, configurable, and flexible benchmark framework. On the basis of the framework, we propose the guideline for building scenario-distilling benchmarks, and present two Internet service AI ones. The preliminary evaluation shows the advantage of scenario-distilling AI benchmarking against using component or micro AI benchmarks alone. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.