 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT-LLM: A Benchmark for Evaluating LLM Integration with Causal Features in Clinical Prognostic Tasks
Nov 13, 2025Large Language Models (LLMs) and causal learning each hold strong potential for clinical decision making (CDM). However, their synergy remains poorly understood, largely due to the lack of systematic benchmarks evaluating their integration in clinical risk prediction. In real-world healthcare, identifying features with causal influence on outcomes is crucial for actionable and trustworthy predictions. While recent work highlights LLMs' emerging causal reasoning abilities, there lacks comprehensive benchmarks to assess their causal learning and performance informed by causal features in clinical risk prediction. To address this, we introduce REACT-LLM, a benchmark designed to evaluate whether combining LLMs with causal features can enhance clinical prognostic performance and potentially outperform traditional machine learning (ML) methods. Unlike existing LLM-clinical benchmarks that often focus on a limited set of outcomes, REACT-LLM evaluates 7 clinical outcomes across 2 real-world datasets, comparing 15 prominent LLMs, 6 traditional ML models, and 3 causal discovery (CD) algorithms. Our findings indicate that while LLMs perform reasonably in clinical prognostics, they have not yet outperformed traditional ML models. Integrating causal features derived from CD algorithms into LLMs offers limited performance gains, primarily due to the strict assumptions of many CD methods, which are often violated in complex clinical data. While the direct integration yields limited improvement, our benchmark reveals a more promising synergy.
GGS: Generalizable Gaussian Splatting for Lane Switching in Autonomous Driving
Sep 04, 2024
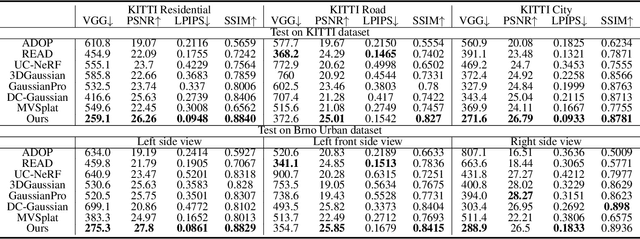
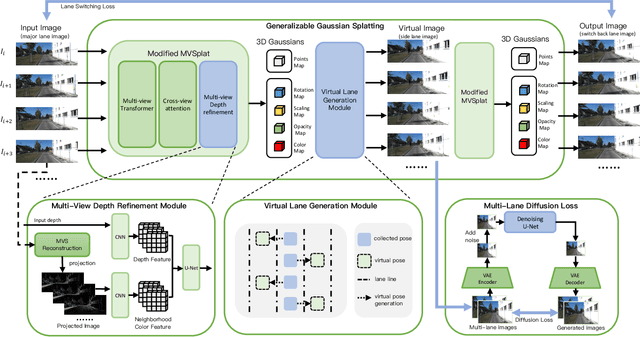

We propose GGS, a Generalizable Gaussian Splatting method for Autonomous Driving which can achieve realistic rendering under large viewpoint changes. Previous generalizable 3D gaussian splatting methods are limited to rendering novel views that are very close to the original pair of images, which cannot handle large differences in viewpoint. Especially in autonomous driving scenarios, images are typically collected from a single lane. The limited training perspective makes rendering images of a different lane very challenging. To further improve the rendering capability of GGS under large viewpoint changes, we introduces a novel virtual lane generation module into GSS method to enables high-quality lane switching even without a multi-lane dataset. Besides, we design a diffusion loss to supervise the generation of virtual lane image to further address the problem of lack of data in the virtual lanes. Finally, we also propose a depth refinement module to optimize depth estimation in the GSS model. Extensive validation of our method, compared to existing approaches, demonstrates state-of-the-art performance.
DLCA-Recon: Dynamic Loose Clothing Avatar Reconstruction from Monocular Videos
Dec 20, 2023



Reconstructing a dynamic human with loose clothing is an important but difficult task. To address this challenge, we propose a method named DLCA-Recon to create human avatars from monocular videos. The distance from loose clothing to the underlying body rapidly changes in every frame when the human freely moves and acts. Previous methods lack effective geometric initialization and constraints for guiding the optimization of deformation to explain this dramatic change, resulting in the discontinuous and incomplete reconstruction surface. To model the deformation more accurately, we propose to initialize an estimated 3D clothed human in the canonical space, as it is easier for deformation fields to learn from the clothed human than from SMPL. With both representations of explicit mesh and implicit SDF, we utilize the physical connection information between consecutive frames and propose a dynamic deformation field (DDF) to optimize deformation fields. DDF accounts for contributive forces on loose clothing to enhance the interpretability of deformations and effectively capture the free movement of loose clothing. Moreover, we propagate SMPL skinning weights to each individual and refine pose and skinning weights during the optimization to improve skinning transformation. Based on more reasonable initialization and DDF, we can simulate real-world physics more accurately. Extensive experiments on public and our own datasets validate that our method can produce superior results for humans with loose clothing compared to the SOTA methods.
NeTO:Neural Reconstruction of Transparent Objects with Self-Occlusion Aware Refraction-Tracing
Mar 20, 2023
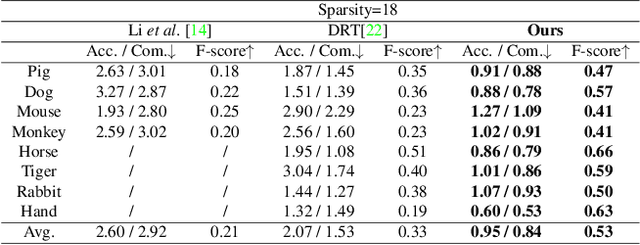
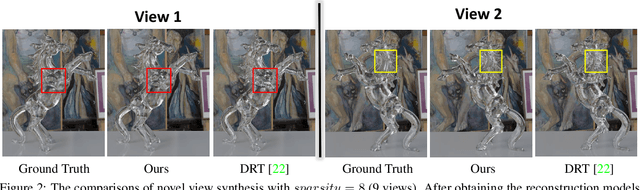
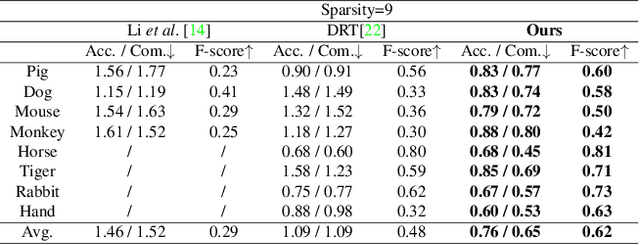
We present a novel method, called NeTO, for capturing 3D geometry of solid transparent objects from 2D images via volume rendering. Reconstructing transparent objects is a very challenging task, which is ill-suited for general-purpose reconstruction techniques due to the specular light transport phenomena. Although existing refraction-tracing based methods, designed specially for this task, achieve impressive results, they still suffer from unstable optimization and loss of fine details, since the explicit surface representation they adopted is difficult to be optimized, and the self-occlusion problem is ignored for refraction-tracing. In this paper, we propose to leverage implicit Signed Distance Function (SDF) as surface representation, and optimize the SDF field via volume rendering with a self-occlusion aware refractive ray tracing. The implicit representation enables our method to be capable of reconstructing high-quality reconstruction even with a limited set of images, and the self-occlusion aware strategy makes it possible for our method to accurately reconstruct the self-occluded regions. Experiments show that our method achieves faithful reconstruction results and outperforms prior works by a large margin. Visit our project page at \url{https://www.xxlong.site/NeTO/}
NeuralRoom: Geometry-Constrained Neural Implicit Surfaces for Indoor Scene Reconstruction
Oct 13, 2022


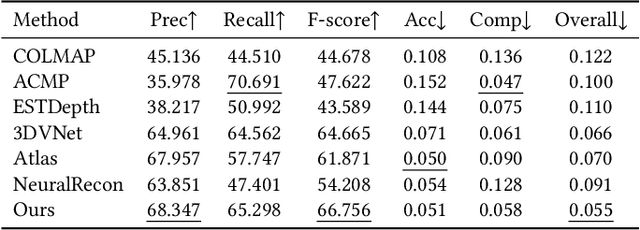
We present a novel neural surface reconstruction method called NeuralRoom for reconstructing room-sized indoor scenes directly from a set of 2D images. Recently, implicit neural representations have become a promising way to reconstruct surfaces from multiview images due to their high-quality results and simplicity. However, implicit neural representations usually cannot reconstruct indoor scenes well because they suffer severe shape-radiance ambiguity. We assume that the indoor scene consists of texture-rich and flat texture-less regions. In texture-rich regions, the multiview stereo can obtain accurate results. In the flat area, normal estimation networks usually obtain a good normal estimation. Based on the above observations, we reduce the possible spatial variation range of implicit neural surfaces by reliable geometric priors to alleviate shape-radiance ambiguity. Specifically, we use multiview stereo results to limit the NeuralRoom optimization space and then use reliable geometric priors to guide NeuralRoom training. Then the NeuralRoom would produce a neural scene representation that can render an image consistent with the input training images. In addition, we propose a smoothing method called perturbation-residual restrictions to improve the accuracy and completeness of the flat region, which assumes that the sampling points in a local surface should have the same normal and similar distance to the observation center. Experiments on the ScanNet dataset show that our method can reconstruct the texture-less area of indoor scenes while maintaining the accuracy of detail. We also apply NeuralRoom to more advanced multiview reconstruction algorithms and significantly improve their reconstruction quality.
A Review of Graph Neural Networks and Their Applications in Power Systems
Jan 25, 2021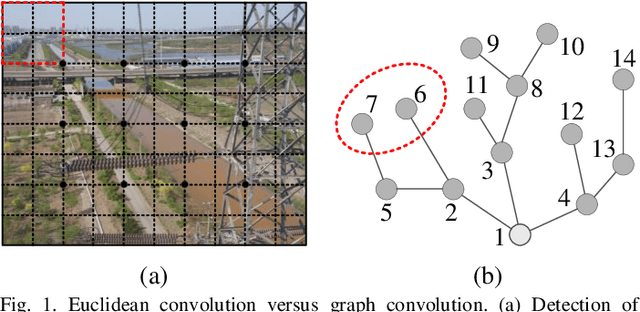
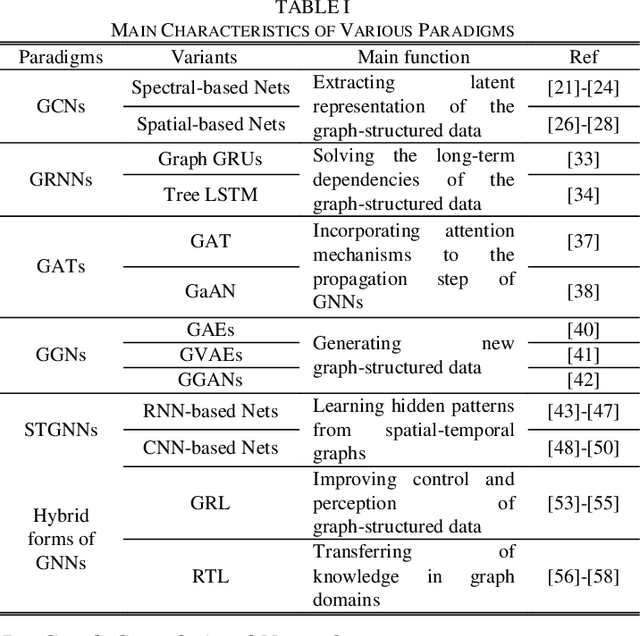
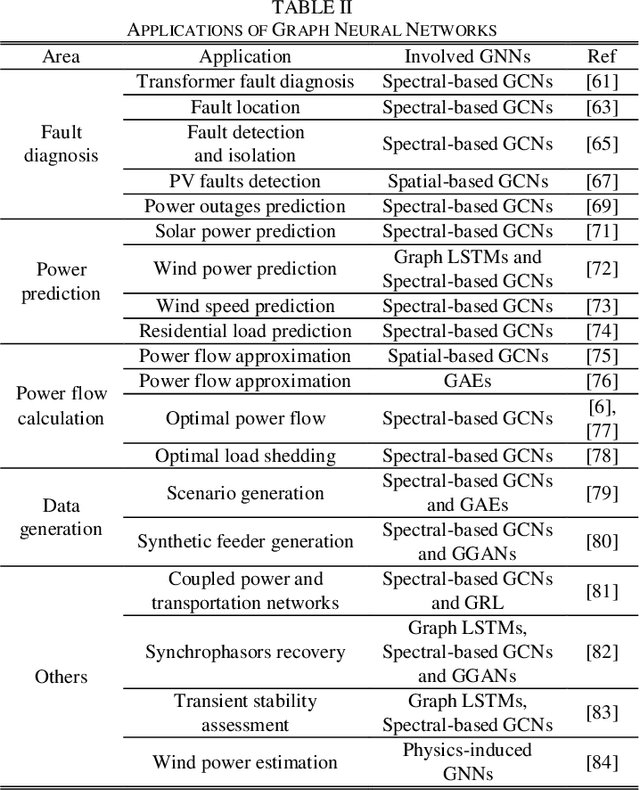
Deep neural networks have revolutionized many machine learning tasks in power systems, ranging from pattern recognition to signal processing. The data in these tasks is typically represented in Euclidean domains. Nevertheless, there is an increasing number of applications in power systems, where data are collected from non-Euclidean domains and represented as the graph-structured data with high dimensional features and interdependency among nodes. The complexity of graph-structured data has brought significant challenges to the existing deep neural networks defined in Euclidean domains. Recently, many studies on extending deep neural networks for graph-structured data in power systems have emerged. In this paper, a comprehensive overview of graph neural networks (GNNs) in power systems is proposed. Specifically, several classical paradigms of GNNs structures (e.g., graph convolutional networks, graph recurrent neural networks, graph attention networks, graph generative networks, spatial-temporal graph convolutional networks, and hybrid forms of GNNs) are summarized, and key applications in power systems such as fault diagnosis, power prediction, power flow calculation, and data generation are reviewed in detail. Furthermore, main issues and some research trends about the applications of GNNs in power systems are discussed.