 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Causality-Aware Vision-Based 3D Occupancy Prediction
Sep 10, 2025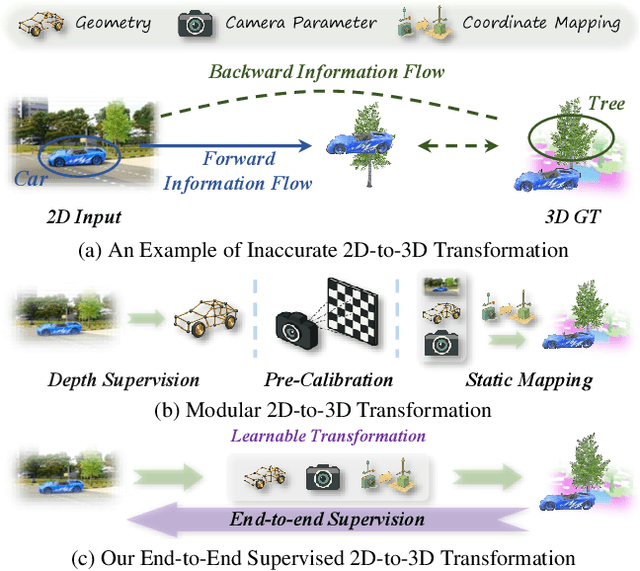

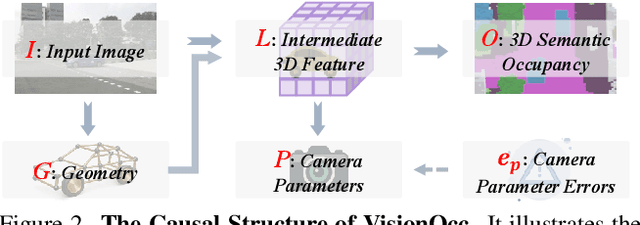
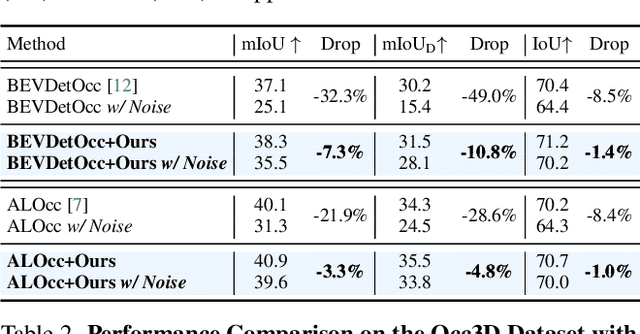
Vision-based 3D semantic occupancy prediction is a critical task in 3D vision that integrates volumetric 3D reconstruction with semantic understanding. Existing methods, however, often rely on modular pipelines. These modules are typically optimized independently or use pre-configured inputs, leading to cascading errors. In this paper, we address this limitation by designing a novel causal loss that enables holistic, end-to-end supervision of the modular 2D-to-3D transformation pipeline. Grounded in the principle of 2D-to-3D semantic causality, this loss regulates the gradient flow from 3D voxel representations back to the 2D features. Consequently, it renders the entire pipeline differentiable, unifying the learning process and making previously non-trainable components fully learnable. Building on this principle, we propose the Semantic Causality-Aware 2D-to-3D Transformation, which comprises three components guided by our causal loss: Channel-Grouped Lifting for adaptive semantic mapping, Learnable Camera Offsets for enhanced robustness against camera perturbations, and Normalized Convolution for effective feature propagation. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the Occ3D benchmark, demonstrating significant robustness to camera perturbations and improved 2D-to-3D semantic consistency.
Rethinking Temporal Fusion with a Unified Gradient Descent View for 3D Semantic Occupancy Prediction
Apr 18, 2025We present GDFusion, a temporal fusion method for vision-based 3D semantic occupancy prediction (VisionOcc). GDFusion opens up the underexplored aspects of temporal fusion within the VisionOcc framework, focusing on both temporal cues and fusion strategies. It systematically examines the entire VisionOcc pipeline, identifying three fundamental yet previously overlooked temporal cues: scene-level consistency, motion calibration, and geometric complementation. These cues capture diverse facets of temporal evolution and make distinct contributions across various modules in the VisionOcc framework. To effectively fuse temporal signals across heterogeneous representations, we propose a novel fusion strategy by reinterpreting the formulation of vanilla RNNs. This reinterpretation leverages gradient descent on features to unify the integration of diverse temporal information, seamlessly embedding the proposed temporal cues into the network. Extensive experiments on nuScenes demonstrate that GDFusion significantly outperforms established baselines. Notably, on Occ3D benchmark, it achieves 1.4\%-4.8\% mIoU improvements and reduces memory consumption by 27\%-72\%.
You Only Click Once: Single Point Weakly Supervised 3D Instance Segmentation for Autonomous Driving
Feb 28, 2025Outdoor LiDAR point cloud 3D instance segmentation is a crucial task in autonomous driving. However, it requires laborious human efforts to annotate the point cloud for training a segmentation model. To address this challenge, we propose a YoCo framework, which generates 3D pseudo labels using minimal coarse click annotations in the bird's eye view plane. It is a significant challenge to produce high-quality pseudo labels from sparse annotations. Our YoCo framework first leverages vision foundation models combined with geometric constraints from point clouds to enhance pseudo label generation. Second, a temporal and spatial-based label updating module is designed to generate reliable updated labels. It leverages predictions from adjacent frames and utilizes the inherent density variation of point clouds (dense near, sparse far). Finally, to further improve label quality, an IoU-guided enhancement module is proposed, replacing pseudo labels with high-confidence and high-IoU predictions. Experiments on the Waymo dataset demonstrate YoCo's effectiveness and generality, achieving state-of-the-art performance among weakly supervised methods and surpassing fully supervised Cylinder3D. Additionally, the YoCo is suitable for various networks, achieving performance comparable to fully supervised methods with minimal fine-tuning using only 0.8% of the fully labeled data, significantly reducing annotation costs.
Generative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
Jan 15, 2025



Autonomous driving is a challenging task that requires perceiving and understanding the surrounding environment for safe trajectory planning. While existing vision-based end-to-end models have achieved promising results, these methods are still facing the challenges of vision understanding, decision reasoning and scene generalization. To solve these issues, a generative planning with 3D-vision language pre-training model named GPVL is proposed for end-to-end autonomous driving. The proposed paradigm has two significant aspects. On one hand, a 3D-vision language pre-training module is designed to bridge the gap between visual perception and linguistic understanding in the bird's eye view. On the other hand, a cross-modal language model is introduced to generate holistic driving decisions and fine-grained trajectories with perception and navigation information in an auto-regressive manner. Experiments on the challenging nuScenes dataset demonstrate that the proposed scheme achieves excellent performances compared with state-of-the-art methods. Besides, the proposed GPVL presents strong generalization ability and real-time potential when handling high-level commands in various scenarios. It is believed that the effective, robust and efficient performance of GPVL is crucial for the practical application of future autonomous driving systems. Code is available at https://github.com/ltp1995/GPVL
Zero-Shot Load Forecasting with Large Language Models
Nov 18, 2024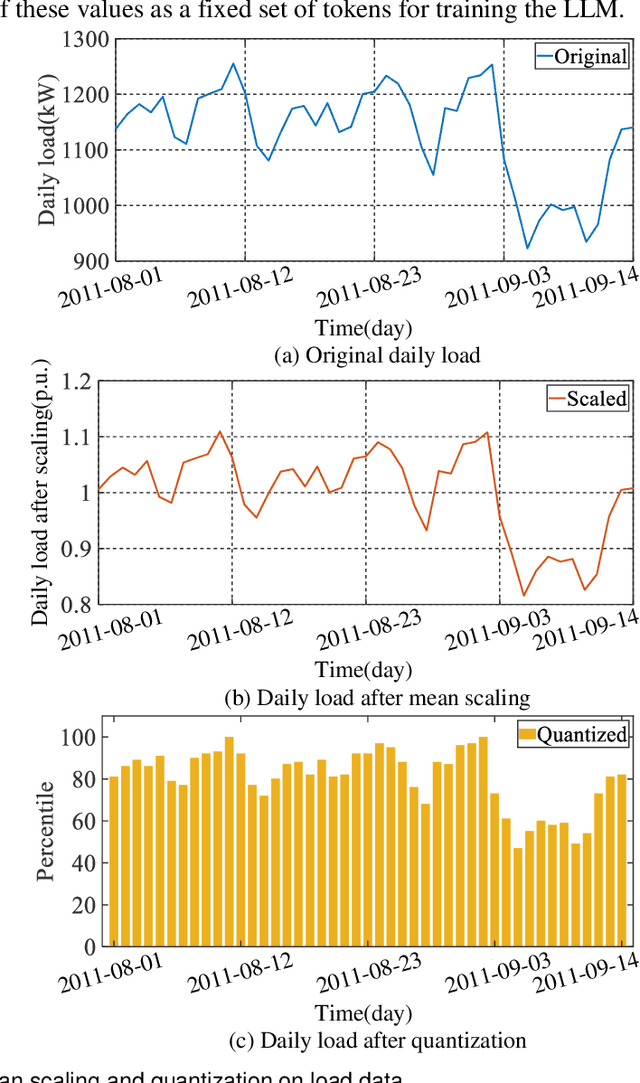



Deep learning models have shown strong performance in load forecasting, but they generally require large amounts of data for model training before being applied to new scenarios, which limits their effectiveness in data-scarce scenarios. Inspired by the great success of pre-trained language models (LLMs) in natural language processing, this paper proposes a zero-shot load forecasting approach using an advanced LLM framework denoted as the Chronos model. By utilizing its extensive pre-trained knowledge, the Chronos model enables accurate load forecasting in data-scarce scenarios without the need for extensive data-specific training. Simulation results across five real-world datasets demonstrate that the Chronos model significantly outperforms nine popular baseline models for both deterministic and probabilistic load forecasting with various forecast horizons (e.g., 1 to 48 hours), even though the Chronos model is neither tailored nor fine-tuned to these specific load datasets. Notably, Chronos reduces root mean squared error (RMSE), continuous ranked probability score (CRPS), and quantile score (QS) by approximately 7.34%-84.30%, 19.63%-60.06%, and 22.83%-54.49%, respectively, compared to baseline models. These results highlight the superiority and flexibility of the Chronos model, positioning it as an effective solution in data-scarce scenarios.
Open-Vocabulary Object Detection via Neighboring Region Attention Alignment
May 14, 2024



The nature of diversity in real-world environments necessitates neural network models to expand from closed category settings to accommodate novel emerging categories. In this paper, we study the open-vocabulary object detection (OVD), which facilitates the detection of novel object classes under the supervision of only base annotations and open-vocabulary knowledge. However, we find that the inadequacy of neighboring relationships between regions during the alignment process inevitably constrains the performance on recent distillation-based OVD strategies. To this end, we propose Neighboring Region Attention Alignment (NRAA), which performs alignment within the attention mechanism of a set of neighboring regions to boost the open-vocabulary inference. Specifically, for a given proposal region, we randomly explore the neighboring boxes and conduct our proposed neighboring region attention (NRA) mechanism to extract relationship information. Then, this interaction information is seamlessly provided into the distillation procedure to assist the alignment between the detector and the pre-trained vision-language models (VLMs). Extensive experiments validate that our proposed model exhibits superior performance on open-vocabulary benchmarks.
TimeGPT in Load Forecasting: A Large Time Series Model Perspective
Apr 07, 2024



Machine learning models have made significant progress in load forecasting, but their forecast accuracy is limited in cases where historical load data is scarce. Inspired by the outstanding performance of large language models (LLMs) in computer vision and natural language processing, this paper aims to discuss the potential of large time series models in load forecasting with scarce historical data. Specifically, the large time series model is constructed as a time series generative pre-trained transformer (TimeGPT), which is trained on massive and diverse time series datasets consisting of 100 billion data points (e.g., finance, transportation, banking, web traffic, weather, energy, healthcare, etc.). Then, the scarce historical load data is used to fine-tune the TimeGPT, which helps it to adapt to the data distribution and characteristics associated with load forecasting. Simulation results show that TimeGPT outperforms the benchmarks (e.g., popular machine learning models and statistical models) for load forecasting on several real datasets with scarce training samples, particularly for short look-ahead times. However, it cannot be guaranteed that TimeGPT is always superior to benchmarks for load forecasting with scarce data, since the performance of TimeGPT may be affected by the distribution differences between the load data and the training data. In practical applications, we can divide the historical data into a training set and a validation set, and then use the validation set loss to decide whether TimeGPT is the best choice for a specific dataset.
Grounding and Enhancing Grid-based Models for Neural Fields
Apr 06, 2024Many contemporary studies utilize grid-based models for neural field representation, but a systematic analysis of grid-based models is still missing, hindering the improvement of those models. Therefore, this paper introduces a theoretical framework for grid-based models. This framework points out that these models' approximation and generalization behaviors are determined by grid tangent kernels (GTK), which are intrinsic properties of grid-based models. The proposed framework facilitates a consistent and systematic analysis of diverse grid-based models. Furthermore, the introduced framework motivates the development of a novel grid-based model named the Multiplicative Fourier Adaptive Grid (MulFAGrid). The numerical analysis demonstrates that MulFAGrid exhibits a lower generalization bound than its predecessors, indicating its robust generalization performance. Empirical studies reveal that MulFAGrid achieves state-of-the-art performance in various tasks, including 2D image fitting, 3D signed distance field (SDF) reconstruction, and novel view synthesis, demonstrating superior representation ability. The project website is available at https://sites.google.com/view/cvpr24-2034-submission/home.
AMP: Autoregressive Motion Prediction Revisited with Next Token Prediction for Autonomous Driving
Mar 21, 2024



As an essential task in autonomous driving (AD), motion prediction aims to predict the future states of surround objects for navigation. One natural solution is to estimate the position of other agents in a step-by-step manner where each predicted time-step is conditioned on both observed time-steps and previously predicted time-steps, i.e., autoregressive prediction. Pioneering works like SocialLSTM and MFP design their decoders based on this intuition. However, almost all state-of-the-art works assume that all predicted time-steps are independent conditioned on observed time-steps, where they use a single linear layer to generate positions of all time-steps simultaneously. They dominate most motion prediction leaderboards due to the simplicity of training MLPs compared to autoregressive networks. In this paper, we introduce the GPT style next token prediction into motion forecasting. In this way, the input and output could be represented in a unified space and thus the autoregressive prediction becomes more feasible. However, different from language data which is composed of homogeneous units -words, the elements in the driving scene could have complex spatial-temporal and semantic relations. To this end, we propose to adopt three factorized attention modules with different neighbors for information aggregation and different position encoding styles to capture their relations, e.g., encoding the transformation between coordinate systems for spatial relativity while adopting RoPE for temporal relativity. Empirically, by equipping with the aforementioned tailored designs, the proposed method achieves state-of-the-art performance in the Waymo Open Motion and Waymo Interaction datasets. Notably, AMP outperforms other recent autoregressive motion prediction methods: MotionLM and StateTransformer, which demonstrates the effectiveness of the proposed designs.
ActiveAD: Planning-Oriented Active Learning for End-to-End Autonomous Driving
Mar 05, 2024End-to-end differentiable learning for autonomous driving (AD) has recently become a prominent paradigm. One main bottleneck lies in its voracious appetite for high-quality labeled data e.g. 3D bounding boxes and semantic segmentation, which are notoriously expensive to manually annotate. The difficulty is further pronounced due to the prominent fact that the behaviors within samples in AD often suffer from long tailed distribution. In other words, a large part of collected data can be trivial (e.g. simply driving forward in a straight road) and only a few cases are safety-critical. In this paper, we explore a practically important yet under-explored problem about how to achieve sample and label efficiency for end-to-end AD. Specifically, we design a planning-oriented active learning method which progressively annotates part of collected raw data according to the proposed diversity and usefulness criteria for planning routes. Empirically, we show that our planning-oriented approach could outperform general active learning methods by a large margin. Notably, our method achieves comparable performance with state-of-the-art end-to-end AD methods - by using only 30% nuScenes data. We hope our work could inspire future works to explore end-to-end AD from a data-centric perspective in addition to methodology efforts.