 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Click Once: Single Point Weakly Supervised 3D Instance Segmentation for Autonomous Driving
Feb 28, 2025Outdoor LiDAR point cloud 3D instance segmentation is a crucial task in autonomous driving. However, it requires laborious human efforts to annotate the point cloud for training a segmentation model. To address this challenge, we propose a YoCo framework, which generates 3D pseudo labels using minimal coarse click annotations in the bird's eye view plane. It is a significant challenge to produce high-quality pseudo labels from sparse annotations. Our YoCo framework first leverages vision foundation models combined with geometric constraints from point clouds to enhance pseudo label generation. Second, a temporal and spatial-based label updating module is designed to generate reliable updated labels. It leverages predictions from adjacent frames and utilizes the inherent density variation of point clouds (dense near, sparse far). Finally, to further improve label quality, an IoU-guided enhancement module is proposed, replacing pseudo labels with high-confidence and high-IoU predictions. Experiments on the Waymo dataset demonstrate YoCo's effectiveness and generality, achieving state-of-the-art performance among weakly supervised methods and surpassing fully supervised Cylinder3D. Additionally, the YoCo is suitable for various networks, achieving performance comparable to fully supervised methods with minimal fine-tuning using only 0.8% of the fully labeled data, significantly reducing annotation costs.
Mask-RadarNet: Enhancing Transformer With Spatial-Temporal Semantic Context for Radar Object Detection in Autonomous Driving
Dec 20, 2024
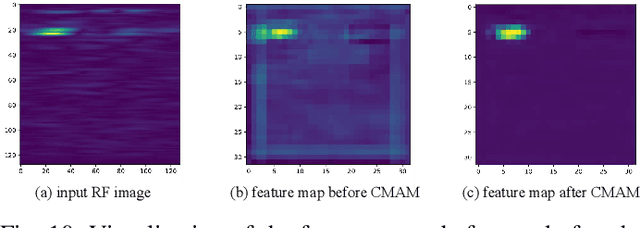
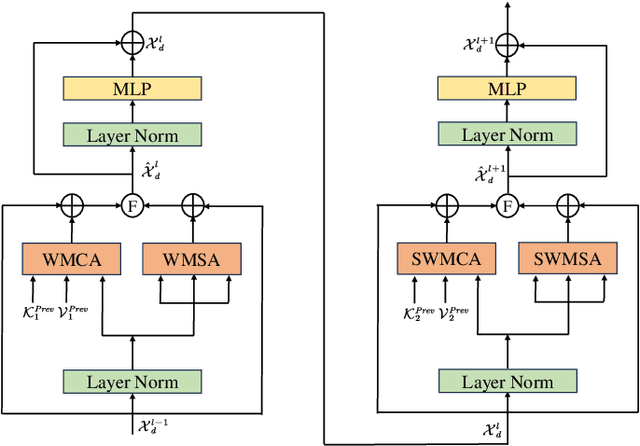
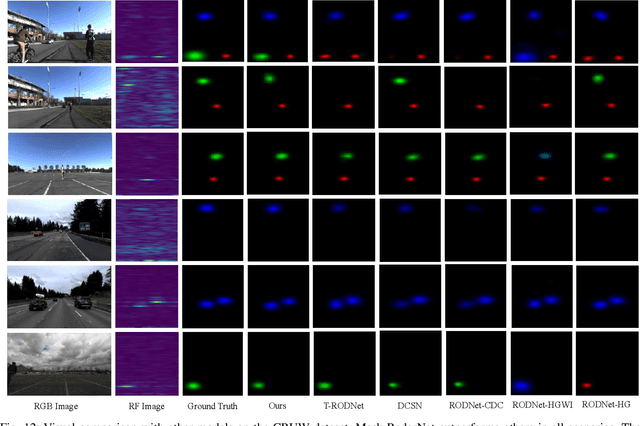
As a cost-effective and robust technology, automotive radar has seen steady improvement during the last years, making it an appealing complement to commonly used sensors like camera and LiDAR in autonomous driving. Radio frequency data with rich semantic information are attracting more and more attention. Most current radar-based models take radio frequency image sequences as the input. However, these models heavily rely on convolutional neural networks and leave out the spatial-temporal semantic context during the encoding stage. To solve these problems, we propose a model called Mask-RadarNet to fully utilize the hierarchical semantic features from the input radar data. Mask-RadarNet exploits the combination of interleaved convolution and attention operations to replace the traditional architecture in transformer-based models. In addition, patch shift is introduced to the Mask-RadarNet for efficient spatial-temporal feature learning. By shifting part of patches with a specific mosaic pattern in the temporal dimension, Mask-RadarNet achieves competitive performance while reducing the computational burden of the spatial-temporal modeling. In order to capture the spatial-temporal semantic contextual information, we design the class masking attention module (CMAM) in our encoder. Moreover, a lightweight auxiliary decoder is added to our model to aggregate prior maps generated from the CMAM. Experiments on the CRUW dataset demonstrate the superiority of the proposed method to some state-of-the-art radar-based object detection algorithms. With relatively lower computational complexity and fewer parameters, the proposed Mask-RadarNet achieves higher recognition accuracy for object detection in autonomous driving.
MWSIS: Multimodal Weakly Supervised Instance Segmentation with 2D Box Annotations for Autonomous Driving
Dec 17, 2023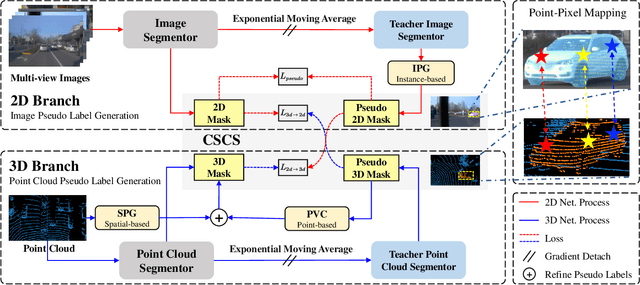

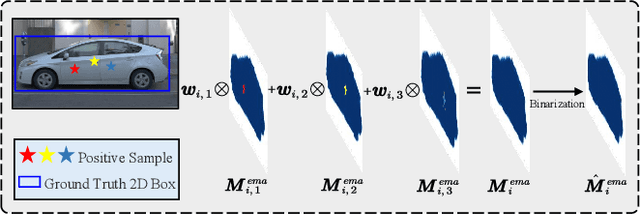

Instance segmentation is a fundamental research in computer vision, especially in autonomous driving. However, manual mask annotation for instance segmentation is quite time-consuming and costly. To address this problem, some prior works attempt to apply weakly supervised manner by exploring 2D or 3D boxes. However, no one has ever successfully segmented 2D and 3D instances simultaneously by only using 2D box annotations, which could further reduce the annotation cost by an order of magnitude. Thus, we propose a novel framework called Multimodal Weakly Supervised Instance Segmentation (MWSIS), which incorporates various fine-grained label generation and correction modules for both 2D and 3D modalities to improve the quality of pseudo labels, along with a new multimodal cross-supervision approach, named Consistency Sparse Cross-modal Supervision (CSCS), to reduce the inconsistency of multimodal predictions by response distillation. Particularly, transferring the 3D backbone to downstream tasks not only improves the performance of the 3D detectors, but also outperforms fully supervised instance segmentation with only 5% fully supervised annotations. On the Waymo dataset, the proposed framework demonstrates significant improvements over the baseline, especially achieving 2.59% mAP and 12.75% mAP increases for 2D and 3D instance segmentation tasks, respectively. The code is available at https://github.com/jiangxb98/mwsis-plugin.