 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLWM: Dual Latent World Models enable Holistic Gaussian-centric Pre-training in Autonomous Driving
Apr 01, 2026Vision-based autonomous driving has gained much attention due to its low costs and excellent performance. Compared with dense BEV (Bird's Eye View) or sparse query models, Gaussian-centric method is a comprehensive yet sparse representation by describing scene with 3D semantic Gaussians. In this paper, we introduce DLWM, a novel paradigm with Dual Latent World Models specifically designed to enable holistic gaussian-centric pre-training in autonomous driving using two stages. In the first stage, DLWM predicts 3D Gaussians from queries by self-supervised reconstructing multi-view semantic and depth images. Equipped with fine-grained contextual features, in the second stage, two latent world models are trained separately for temporal feature learning, including Gaussian-flow-guided latent prediction for downstream occupancy perception and forecasting tasks, and ego-planning-guided latent prediction for motion planning. Extensive experiments in SurroundOcc and nuScenes benchmarks demonstrate that DLWM shows significant performance gains across Gaussian-centric 3D occupancy perception, 4D occupancy forecasting and motion planning tasks.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
Dec 10, 2025Autonomous driving (AD) systems struggle in long-tail scenarios due to limited world knowledge and weak visual dynamic modeling. Existing vision-language-action (VLA)-based methods cannot leverage unlabeled videos for visual causal learning, while world model-based methods lack reasoning capabilities from large language models. In this paper, we construct multiple specialized datasets providing reasoning and planning annotations for complex scenarios. Then, a unified Understanding-Generation-Planning framework, named UniUGP, is proposed to synergize scene reasoning, future video generation, and trajectory planning through a hybrid expert architecture. By integrating pre-trained VLMs and video generation models, UniUGP leverages visual dynamics and semantic reasoning to enhance planning performance. Taking multi-frame observations and language instructions as input, it produces interpretable chain-of-thought reasoning, physically consistent trajectories, and coherent future videos. We introduce a four-stage training strategy that progressively builds these capabilities across multiple existing AD datasets, along with the proposed specialized datasets. Experiments demonstrate state-of-the-art performance in perception, reasoning, and decision-making, with superior generalization to challenging long-tail situations.
Is Your VLM for Autonomous Driving Safety-Ready? A Comprehensive Benchmark for Evaluating External and In-Cabin Risks
Nov 19, 2025Vision-Language Models (VLMs) show great promise for autonomous driving, but their suitability for safety-critical scenarios is largely unexplored, raising safety concerns. This issue arises from the lack of comprehensive benchmarks that assess both external environmental risks and in-cabin driving behavior safety simultaneously. To bridge this critical gap, we introduce DSBench, the first comprehensive Driving Safety Benchmark designed to assess a VLM's awareness of various safety risks in a unified manner. DSBench encompasses two major categories: external environmental risks and in-cabin driving behavior safety, divided into 10 key categories and a total of 28 sub-categories. This comprehensive evaluation covers a wide range of scenarios, ensuring a thorough assessment of VLMs' performance in safety-critical contexts. Extensive evaluations across various mainstream open-source and closed-source VLMs reveal significant performance degradation under complex safety-critical situations, highlighting urgent safety concerns. To address this, we constructed a large dataset of 98K instances focused on in-cabin and external safety scenarios, showing that fine-tuning on this dataset significantly enhances the safety performance of existing VLMs and paves the way for advancing autonomous driving technology. The benchmark toolkit, code, and model checkpoints will be publicly accessible.
You Only Click Once: Single Point Weakly Supervised 3D Instance Segmentation for Autonomous Driving
Feb 28, 2025Outdoor LiDAR point cloud 3D instance segmentation is a crucial task in autonomous driving. However, it requires laborious human efforts to annotate the point cloud for training a segmentation model. To address this challenge, we propose a YoCo framework, which generates 3D pseudo labels using minimal coarse click annotations in the bird's eye view plane. It is a significant challenge to produce high-quality pseudo labels from sparse annotations. Our YoCo framework first leverages vision foundation models combined with geometric constraints from point clouds to enhance pseudo label generation. Second, a temporal and spatial-based label updating module is designed to generate reliable updated labels. It leverages predictions from adjacent frames and utilizes the inherent density variation of point clouds (dense near, sparse far). Finally, to further improve label quality, an IoU-guided enhancement module is proposed, replacing pseudo labels with high-confidence and high-IoU predictions. Experiments on the Waymo dataset demonstrate YoCo's effectiveness and generality, achieving state-of-the-art performance among weakly supervised methods and surpassing fully supervised Cylinder3D. Additionally, the YoCo is suitable for various networks, achieving performance comparable to fully supervised methods with minimal fine-tuning using only 0.8% of the fully labeled data, significantly reducing annotation costs.
EGSRAL: An Enhanced 3D Gaussian Splatting based Renderer with Automated Labeling for Large-Scale Driving Scene
Dec 20, 2024



3D Gaussian Splatting (3D GS) has gained popularity due to its faster rendering speed and high-quality novel view synthesis. Some researchers have explored using 3D GS for reconstructing driving scenes. However, these methods often rely on various data types, such as depth maps, 3D boxes, and trajectories of moving objects. Additionally, the lack of annotations for synthesized images limits their direct application in downstream tasks. To address these issues, we propose EGSRAL, a 3D GS-based method that relies solely on training images without extra annotations. EGSRAL enhances 3D GS's capability to model both dynamic objects and static backgrounds and introduces a novel adaptor for auto labeling, generating corresponding annotations based on existing annotations. We also propose a grouping strategy for vanilla 3D GS to address perspective issues in rendering large-scale, complex scenes. Our method achieves state-of-the-art performance on multiple datasets without any extra annotation. For example, the PSNR metric reaches 29.04 on the nuScenes dataset. Moreover, our automated labeling can significantly improve the performance of 2D/3D detection tasks. Code is available at https://github.com/jiangxb98/EGSRAL.
Mask-RadarNet: Enhancing Transformer With Spatial-Temporal Semantic Context for Radar Object Detection in Autonomous Driving
Dec 20, 2024
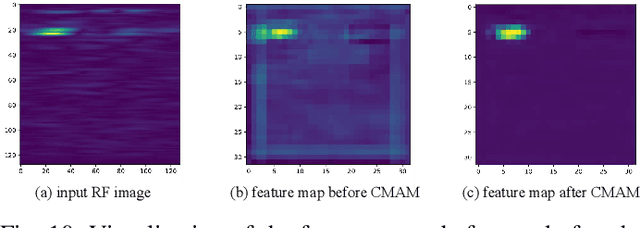
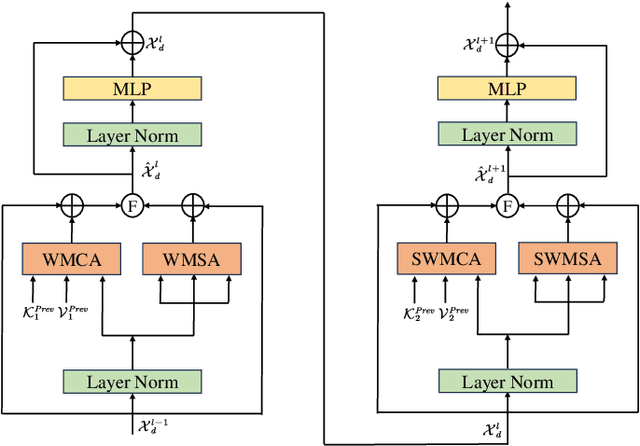
As a cost-effective and robust technology, automotive radar has seen steady improvement during the last years, making it an appealing complement to commonly used sensors like camera and LiDAR in autonomous driving. Radio frequency data with rich semantic information are attracting more and more attention. Most current radar-based models take radio frequency image sequences as the input. However, these models heavily rely on convolutional neural networks and leave out the spatial-temporal semantic context during the encoding stage. To solve these problems, we propose a model called Mask-RadarNet to fully utilize the hierarchical semantic features from the input radar data. Mask-RadarNet exploits the combination of interleaved convolution and attention operations to replace the traditional architecture in transformer-based models. In addition, patch shift is introduced to the Mask-RadarNet for efficient spatial-temporal feature learning. By shifting part of patches with a specific mosaic pattern in the temporal dimension, Mask-RadarNet achieves competitive performance while reducing the computational burden of the spatial-temporal modeling. In order to capture the spatial-temporal semantic contextual information, we design the class masking attention module (CMAM) in our encoder. Moreover, a lightweight auxiliary decoder is added to our model to aggregate prior maps generated from the CMAM. Experiments on the CRUW dataset demonstrate the superiority of the proposed method to some state-of-the-art radar-based object detection algorithms. With relatively lower computational complexity and fewer parameters, the proposed Mask-RadarNet achieves higher recognition accuracy for object detection in autonomous driving.
MSSF: A 4D Radar and Camera Fusion Framework With Multi-Stage Sampling for 3D Object Detection in Autonomous Driving
Nov 22, 2024

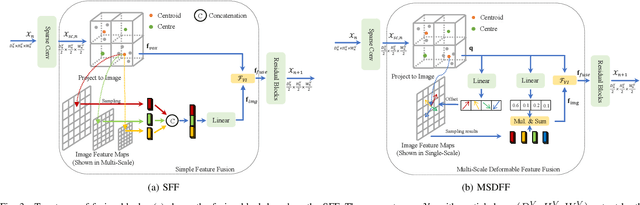

As one of the automotive sensors that have emerged in recent years, 4D millimeter-wave radar has a higher resolution than conventional 3D radar and provides precise elevation measurements. But its point clouds are still sparse and noisy, making it challenging to meet the requirements of autonomous driving. Camera, as another commonly used sensor, can capture rich semantic information. As a result, the fusion of 4D radar and camera can provide an affordable and robust perception solution for autonomous driving systems. However, previous radar-camera fusion methods have not yet been thoroughly investigated, resulting in a large performance gap compared to LiDAR-based methods. Specifically, they ignore the feature-blurring problem and do not deeply interact with image semantic information. To this end, we present a simple but effective multi-stage sampling fusion (MSSF) network based on 4D radar and camera. On the one hand, we design a fusion block that can deeply interact point cloud features with image features, and can be applied to commonly used single-modal backbones in a plug-and-play manner. The fusion block encompasses two types, namely, simple feature fusion (SFF) and multiscale deformable feature fusion (MSDFF). The SFF is easy to implement, while the MSDFF has stronger fusion abilities. On the other hand, we propose a semantic-guided head to perform foreground-background segmentation on voxels with voxel feature re-weighting, further alleviating the problem of feature blurring. Extensive experiments on the View-of-Delft (VoD) and TJ4DRadset datasets demonstrate the effectiveness of our MSSF. Notably, compared to state-of-the-art methods, MSSF achieves a 7.0% and 4.0% improvement in 3D mean average precision on the VoD and TJ4DRadSet datasets, respectively. It even surpasses classical LiDAR-based methods on the VoD dataset.
MWSIS: Multimodal Weakly Supervised Instance Segmentation with 2D Box Annotations for Autonomous Driving
Dec 17, 2023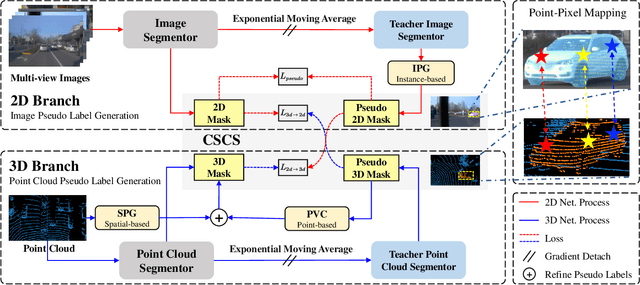

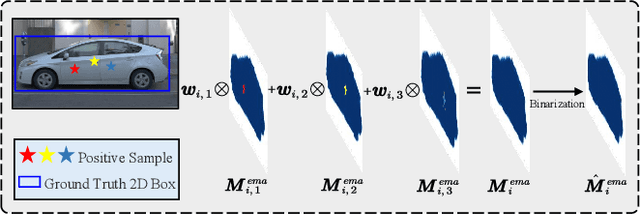

Instance segmentation is a fundamental research in computer vision, especially in autonomous driving. However, manual mask annotation for instance segmentation is quite time-consuming and costly. To address this problem, some prior works attempt to apply weakly supervised manner by exploring 2D or 3D boxes. However, no one has ever successfully segmented 2D and 3D instances simultaneously by only using 2D box annotations, which could further reduce the annotation cost by an order of magnitude. Thus, we propose a novel framework called Multimodal Weakly Supervised Instance Segmentation (MWSIS), which incorporates various fine-grained label generation and correction modules for both 2D and 3D modalities to improve the quality of pseudo labels, along with a new multimodal cross-supervision approach, named Consistency Sparse Cross-modal Supervision (CSCS), to reduce the inconsistency of multimodal predictions by response distillation. Particularly, transferring the 3D backbone to downstream tasks not only improves the performance of the 3D detectors, but also outperforms fully supervised instance segmentation with only 5% fully supervised annotations. On the Waymo dataset, the proposed framework demonstrates significant improvements over the baseline, especially achieving 2.59% mAP and 12.75% mAP increases for 2D and 3D instance segmentation tasks, respectively. The code is available at https://github.com/jiangxb98/mwsis-plugin.