 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
A Prediction-as-Perception Framework for 3D Object Detection
Mar 13, 2026Humans combine prediction and perception to observe the world. When faced with rapidly moving birds or insects, we can only perceive them clearly by predicting their next position and focusing our gaze there. Inspired by this, this paper proposes the Prediction-As-Perception (PAP) framework, integrating a prediction-perception architecture into 3D object perception tasks to enhance the model's perceptual accuracy. The PAP framework consists of two main modules: prediction and perception, primarily utilizing continuous frame information as input. Firstly, the prediction module forecasts the potential future positions of ego vehicles and surrounding traffic participants based on the perception results of the current frame. These predicted positions are then passed as queries to the perception module of the subsequent frame. The perceived results are iteratively fed back into the prediction module. We evaluated the PAP structure using the end-to-end model UniAD on the nuScenes dataset. The results demonstrate that the PAP structure improves UniAD's target tracking accuracy by 10% and increases the inference speed by 15%. This indicates that such a biomimetic design significantly enhances the efficiency and accuracy of perception models while reducing computational resource consumption.
Risk-Controllable Multi-View Diffusion for Driving Scenario Generation
Mar 12, 2026Generating safety-critical driving scenarios is crucial for evaluating and improving autonomous driving systems, but long-tail risky situations are rarely observed in real-world data and difficult to specify through manual scenario design. Existing generative approaches typically treat risk as an after-the-fact label and struggle to maintain geometric consistency in multi-view driving scenes. We present RiskMV-DPO, a general and systematic pipeline for physically-informed, risk-controllable multi-view scenario generation. By integrating target risk levels with physically-grounded risk modeling, we autonomously synthesize diverse and high-stakes dynamic trajectories that serve as explicit geometric anchors for a diffusion-based video generator. To ensure spatial-temporal coherence and geometric fidelity, we introduce a geometry-appearance alignment module and a region-aware direct preference optimization (RA-DPO) strategy with motion-aware masking to focus learning on localized dynamic regions.Experiments on the nuScenes dataset show that RiskMV-DPO can freely generate a wide spectrum of diverse long-tail scenarios while maintaining state-of-the-art visual quality, improving 3D detection mAP from 18.17 to 30.50 and reducing FID to 15.70. Our work shifts the role of world models from passive environment prediction to proactive, risk-controllable synthesis, providing a scalable toolchain for the safety-oriented development of embodied intelligence.
TS-SatMVSNet: Slope Aware Height Estimation for Large-Scale Earth Terrain Multi-view Stereo
Jan 02, 2025



3D terrain reconstruction with remote sensing imagery achieves cost-effective and large-scale earth observation and is crucial for safeguarding natural disasters, monitoring ecological changes, and preserving the environment.Recently, learning-based multi-view stereo~(MVS) methods have shown promise in this task. However, these methods simply modify the general learning-based MVS framework for height estimation, which overlooks the terrain characteristics and results in insufficient accuracy. Considering that the Earth's surface generally undulates with no drastic changes and can be measured by slope, integrating slope considerations into MVS frameworks could enhance the accuracy of terrain reconstructions. To this end, we propose an end-to-end slope-aware height estimation network named TS-SatMVSNet for large-scale remote sensing terrain reconstruction.To effectively obtain the slope representation, drawing from mathematical gradient concepts, we innovatively proposed a height-based slope calculation strategy to first calculate a slope map from a height map to measure the terrain undulation. To fully integrate slope information into the MVS pipeline, we separately design two slope-guided modules to enhance reconstruction outcomes at both micro and macro levels. Specifically, at the micro level, we designed a slope-guided interval partition module for refined height estimation using slope values. At the macro level, a height correction module is proposed, using a learnable Gaussian smoothing operator to amend the inaccurate height values. Additionally, to enhance the efficacy of height estimation, we proposed a slope direction loss for implicitly optimizing height estimation results. Extensive experiments on the WHU-TLC dataset and MVS3D dataset show that our proposed method achieves state-of-the-art performance and demonstrates competitive generalization ability.
EGSRAL: An Enhanced 3D Gaussian Splatting based Renderer with Automated Labeling for Large-Scale Driving Scene
Dec 20, 2024



3D Gaussian Splatting (3D GS) has gained popularity due to its faster rendering speed and high-quality novel view synthesis. Some researchers have explored using 3D GS for reconstructing driving scenes. However, these methods often rely on various data types, such as depth maps, 3D boxes, and trajectories of moving objects. Additionally, the lack of annotations for synthesized images limits their direct application in downstream tasks. To address these issues, we propose EGSRAL, a 3D GS-based method that relies solely on training images without extra annotations. EGSRAL enhances 3D GS's capability to model both dynamic objects and static backgrounds and introduces a novel adaptor for auto labeling, generating corresponding annotations based on existing annotations. We also propose a grouping strategy for vanilla 3D GS to address perspective issues in rendering large-scale, complex scenes. Our method achieves state-of-the-art performance on multiple datasets without any extra annotation. For example, the PSNR metric reaches 29.04 on the nuScenes dataset. Moreover, our automated labeling can significantly improve the performance of 2D/3D detection tasks. Code is available at https://github.com/jiangxb98/EGSRAL.
PDCFNet: Enhancing Underwater Images through Pixel Difference Convolution
Sep 28, 2024Majority of deep learning methods utilize vanilla convolution for enhancing underwater images. While vanilla convolution excels in capturing local features and learning the spatial hierarchical structure of images, it tends to smooth input images, which can somewhat limit feature expression and modeling. A prominent characteristic of underwater degraded images is blur, and the goal of enhancement is to make the textures and details (high-frequency features) in the images more visible. Therefore, we believe that leveraging high-frequency features can improve enhancement performance. To address this, we introduce Pixel Difference Convolution (PDC), which focuses on gradient information with significant changes in the image, thereby improving the modeling of enhanced images. We propose an underwater image enhancement network, PDCFNet, based on PDC and cross-level feature fusion. Specifically, we design a detail enhancement module based on PDC that employs parallel PDCs to capture high-frequency features, leading to better detail and texture enhancement. The designed cross-level feature fusion module performs operations such as concatenation and multiplication on features from different levels, ensuring sufficient interaction and enhancement between diverse features. Our proposed PDCFNet achieves a PSNR of 27.37 and an SSIM of 92.02 on the UIEB dataset, attaining the best performance to date. Our code is available at https://github.com/zhangsong1213/PDCFNet.
Respiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024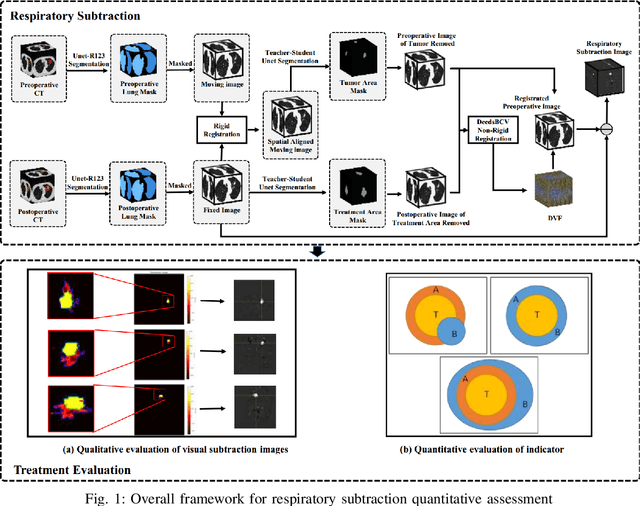
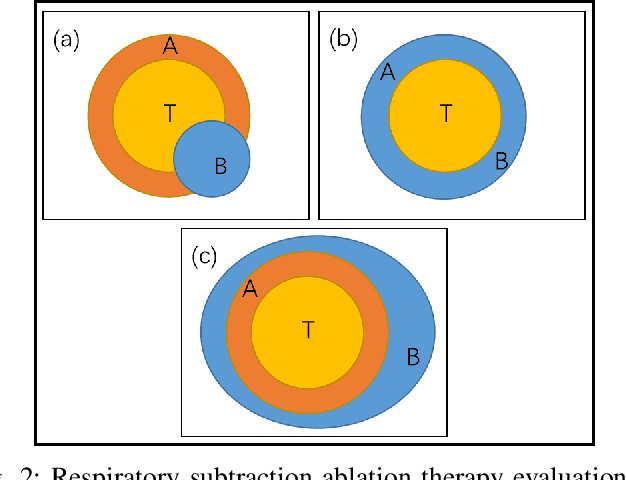
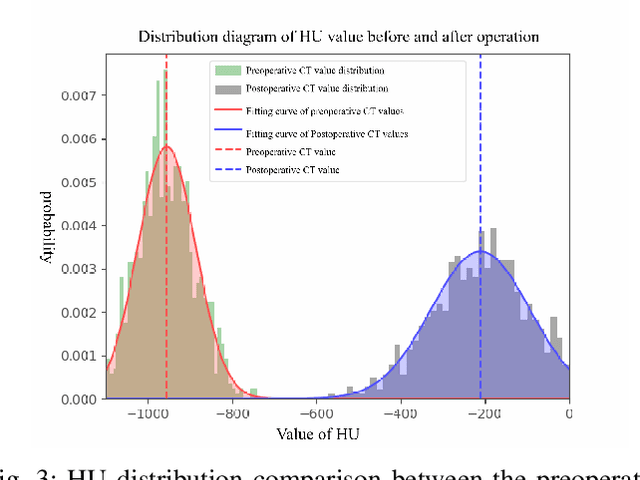
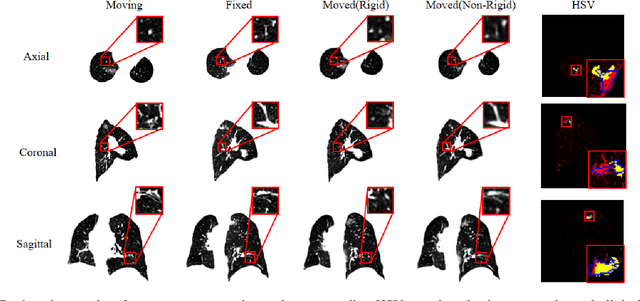
Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
Mamba-UIE: Enhancing Underwater Images with Physical Model Constraint
Jul 27, 2024



In underwater image enhancement (UIE), convolutional neural networks (CNN) have inherent limitations in modeling long-range dependencies and are less effective in recovering global features. While Transformers excel at modeling long-range dependencies, their quadratic computational complexity with increasing image resolution presents significant efficiency challenges. Additionally, most supervised learning methods lack effective physical model constraint, which can lead to insufficient realism and overfitting in generated images. To address these issues, we propose a physical model constraint-based underwater image enhancement framework, Mamba-UIE. Specifically, we decompose the input image into four components: underwater scene radiance, direct transmission map, backscatter transmission map, and global background light. These components are reassembled according to the revised underwater image formation model, and the reconstruction consistency constraint is applied between the reconstructed image and the original image, thereby achieving effective physical constraint on the underwater image enhancement process. To tackle the quadratic computational complexity of Transformers when handling long sequences, we introduce the Mamba-UIE network based on linear complexity state space models (SSM). By incorporating the Mamba in Convolution block, long-range dependencies are modeled at both the channel and spatial levels, while the CNN backbone is retained to recover local features and details. Extensive experiments on three public datasets demonstrate that our proposed Mamba-UIE outperforms existing state-of-the-art methods, achieving a PSNR of 27.13 and an SSIM of 0.93 on the UIEB dataset. Our method is available at https://github.com/zhangsong1213/Mamba-UIE.
ALPS: An Auto-Labeling and Pre-training Scheme for Remote Sensing Segmentation With Segment Anything Model
Jun 16, 2024In the fast-growing field of Remote Sensing (RS) image analysis, the gap between massive unlabeled datasets and the ability to fully utilize these datasets for advanced RS analytics presents a significant challenge. To fill the gap, our work introduces an innovative auto-labeling framework named ALPS (Automatic Labeling for Pre-training in Segmentation), leveraging the Segment Anything Model (SAM) to predict precise pseudo-labels for RS images without necessitating prior annotations or additional prompts. The proposed pipeline significantly reduces the labor and resource demands traditionally associated with annotating RS datasets. By constructing two comprehensive pseudo-labeled RS datasets via ALPS for pre-training purposes, our approach enhances the performance of downstream tasks across various benchmarks, including iSAID and ISPRS Potsdam. Experiments demonstrate the effectiveness of our framework, showcasing its ability to generalize well across multiple tasks even under the scarcity of extensively annotated datasets, offering a scalable solution to automatic segmentation and annotation challenges in the field. In addition, the proposed a pipeline is flexible and can be applied to medical image segmentation, remarkably boosting the performance. Note that ALPS utilizes pre-trained SAM to semi-automatically annotate RS images without additional manual annotations. Though every component in the pipeline has bee well explored, integrating clustering algorithms with SAM and novel pseudo-label alignment significantly enhances RS segmentation, as an off-the-shelf tool for pre-training data preparation. Our source code is available at: https://github.com/StriveZs/ALPS.
NeRO: Neural Road Surface Reconstruction
May 17, 2024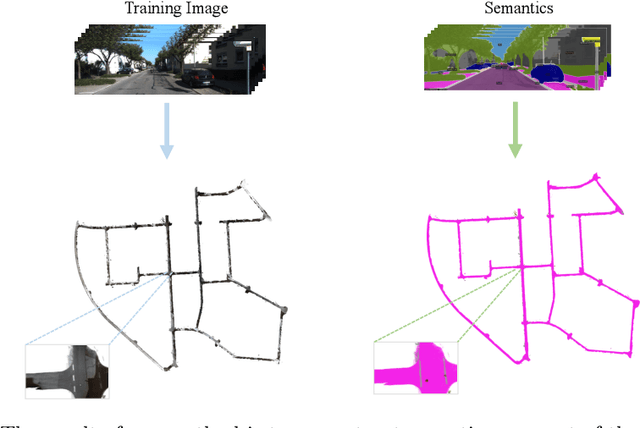
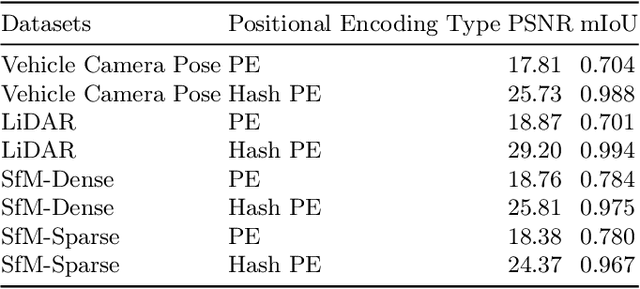
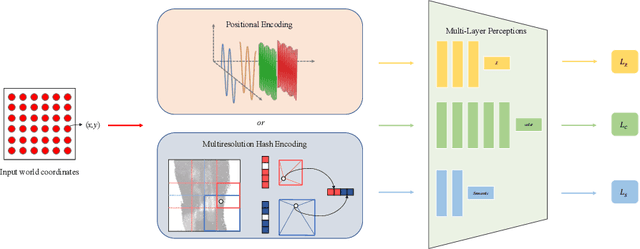

In computer vision and graphics, the accurate reconstruction of road surfaces is pivotal for various applications, especially in autonomous driving. This paper introduces a novel method leveraging the Multi-Layer Perceptrons (MLPs) framework to reconstruct road surfaces in height, color, and semantic information by input world coordinates x and y. Our approach NeRO uses encoding techniques based on MLPs, significantly improving the performance of the complex details, speeding up the training speed, and reducing neural network size. The effectiveness of this method is demonstrated through its superior performance, which indicates a promising direction for rendering road surfaces with semantics applications, particularly in applications demanding visualization of road conditions, 4D labeling, and semantic groupings.