 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Testing in LLMs: Insights into Decision-Making Vulnerabilities
May 19, 2025As Large Language Models (LLMs) become increasingly integrated into real-world decision-making systems, understanding their behavioural vulnerabilities remains a critical challenge for AI safety and alignment. While existing evaluation metrics focus primarily on reasoning accuracy or factual correctness, they often overlook whether LLMs are robust to adversarial manipulation or capable of using adaptive strategy in dynamic environments. This paper introduces an adversarial evaluation framework designed to systematically stress-test the decision-making processes of LLMs under interactive and adversarial conditions. Drawing on methodologies from cognitive psychology and game theory, our framework probes how models respond in two canonical tasks: the two-armed bandit task and the Multi-Round Trust Task. These tasks capture key aspects of exploration-exploitation trade-offs, social cooperation, and strategic flexibility. We apply this framework to several state-of-the-art LLMs, including GPT-3.5, GPT-4, Gemini-1.5, and DeepSeek-V3, revealing model-specific susceptibilities to manipulation and rigidity in strategy adaptation. Our findings highlight distinct behavioral patterns across models and emphasize the importance of adaptability and fairness recognition for trustworthy AI deployment. Rather than offering a performance benchmark, this work proposes a methodology for diagnosing decision-making weaknesses in LLM-based agents, providing actionable insights for alignment and safety research.
TS-SatMVSNet: Slope Aware Height Estimation for Large-Scale Earth Terrain Multi-view Stereo
Jan 02, 2025



3D terrain reconstruction with remote sensing imagery achieves cost-effective and large-scale earth observation and is crucial for safeguarding natural disasters, monitoring ecological changes, and preserving the environment.Recently, learning-based multi-view stereo~(MVS) methods have shown promise in this task. However, these methods simply modify the general learning-based MVS framework for height estimation, which overlooks the terrain characteristics and results in insufficient accuracy. Considering that the Earth's surface generally undulates with no drastic changes and can be measured by slope, integrating slope considerations into MVS frameworks could enhance the accuracy of terrain reconstructions. To this end, we propose an end-to-end slope-aware height estimation network named TS-SatMVSNet for large-scale remote sensing terrain reconstruction.To effectively obtain the slope representation, drawing from mathematical gradient concepts, we innovatively proposed a height-based slope calculation strategy to first calculate a slope map from a height map to measure the terrain undulation. To fully integrate slope information into the MVS pipeline, we separately design two slope-guided modules to enhance reconstruction outcomes at both micro and macro levels. Specifically, at the micro level, we designed a slope-guided interval partition module for refined height estimation using slope values. At the macro level, a height correction module is proposed, using a learnable Gaussian smoothing operator to amend the inaccurate height values. Additionally, to enhance the efficacy of height estimation, we proposed a slope direction loss for implicitly optimizing height estimation results. Extensive experiments on the WHU-TLC dataset and MVS3D dataset show that our proposed method achieves state-of-the-art performance and demonstrates competitive generalization ability.
Neural Implicit Field Editing Considering Object-environment Interaction
Nov 01, 2023



The 3D scene editing method based on neural implicit field has gained wide attention. It has achieved excellent results in 3D editing tasks. However, existing methods often blend the interaction between objects and scene environment. The change of scene appearance like shadows is failed to be displayed in the rendering view. In this paper, we propose an Object and Scene environment Interaction aware (OSI-aware) system, which is a novel two-stream neural rendering system considering object and scene environment interaction. To obtain illuminating conditions from the mixture soup, the system successfully separates the interaction between objects and scene environment by intrinsic decomposition method. To study the corresponding changes to the scene appearance from object-level editing tasks, we introduce a depth map guided scene inpainting method and shadow rendering method by point matching strategy. Extensive experiments demonstrate that our novel pipeline produce reasonable appearance changes in scene editing tasks. It also achieve competitive performance for the rendering quality in novel-view synthesis tasks.
ARAI-MVSNet: A multi-view stereo depth estimation network with adaptive depth range and depth interval
Aug 17, 2023Multi-View Stereo~(MVS) is a fundamental problem in geometric computer vision which aims to reconstruct a scene using multi-view images with known camera parameters. However, the mainstream approaches represent the scene with a fixed all-pixel depth range and equal depth interval partition, which will result in inadequate utilization of depth planes and imprecise depth estimation. In this paper, we present a novel multi-stage coarse-to-fine framework to achieve adaptive all-pixel depth range and depth interval. We predict a coarse depth map in the first stage, then an Adaptive Depth Range Prediction module is proposed in the second stage to zoom in the scene by leveraging the reference image and the obtained depth map in the first stage and predict a more accurate all-pixel depth range for the following stages. In the third and fourth stages, we propose an Adaptive Depth Interval Adjustment module to achieve adaptive variable interval partition for pixel-wise depth range. The depth interval distribution in this module is normalized by Z-score, which can allocate dense depth hypothesis planes around the potential ground truth depth value and vice versa to achieve more accurate depth estimation. Extensive experiments on four widely used benchmark datasets~(DTU, TnT, BlendedMVS, ETH 3D) demonstrate that our model achieves state-of-the-art performance and yields competitive generalization ability. Particularly, our method achieves the highest Acc and Overall on the DTU dataset, while attaining the highest Recall and $F_{1}$-score on the Tanks and Temples intermediate and advanced dataset. Moreover, our method also achieves the lowest $e_{1}$ and $e_{3}$ on the BlendedMVS dataset and the highest Acc and $F_{1}$-score on the ETH 3D dataset, surpassing all listed methods.Project website: https://github.com/zs670980918/ARAI-MVSNet
A Descriptive Study of Variable Discretization and Cost-Sensitive Logistic Regression on Imbalanced Credit Data
Dec 28, 2018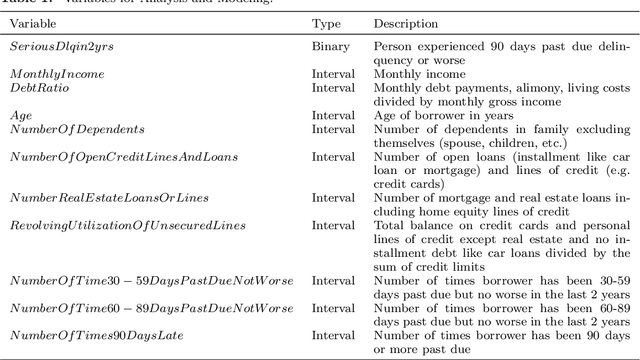



Training classification models on imbalanced data sets tends to result in bias towards the majority class. In this paper, we demonstrate how the variable discretization and Cost-Sensitive Logistic Regression help mitigate this bias on an imbalanced credit scoring data set. 10-fold cross-validation is used as the evaluation method, and the performance measurements are ROC curves and the associated Area Under the Curve. The results show that good variable discretization and Cost-Sensitive Logistic Regression with the best class weight can reduce the model bias and/or variance. It is also shown that effective variable selection helps reduce the model variance. From the algorithm perspective, Cost-Sensitive Logistic Regression is beneficial for increasing the prediction ability of predictors even if they are not in their best forms and keeping the multivariate effect and univariate effect of predictors consistent. From the predictors perspective, the variable discretization performs slightly better than Cost-Sensitive Logistic Regression, provides more reasonable coefficient estimates for predictors which have nonlinear relationship against their empirical logit, and is robust to penalty weights of misclassifications of events and non-events determined by their proportions.
Influence of the Event Rate on Discrimination Abilities of Bankruptcy Prediction Models
Mar 10, 2018

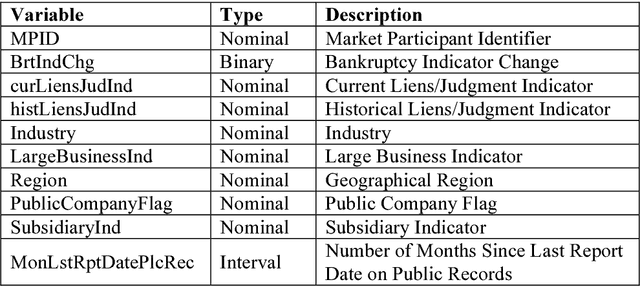
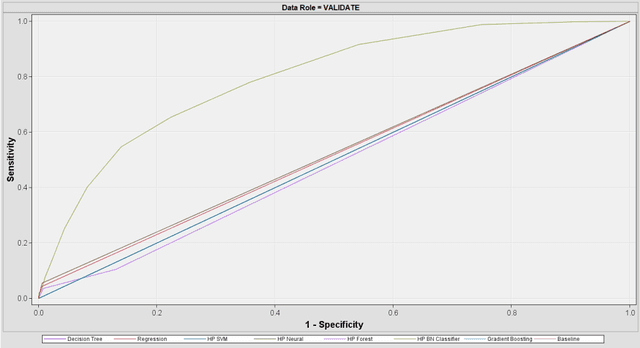
In bankruptcy prediction, the proportion of events is very low, which is often oversampled to eliminate this bias. In this paper, we study the influence of the event rate on discrimination abilities of bankruptcy prediction models. First the statistical association and significance of public records and firmographics indicators with the bankruptcy were explored. Then the event rate was oversampled from 0.12% to 10%, 20%, 30%, 40%, and 50%, respectively. Seven models were developed, including Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, Support Vector Machine, Bayesian Network, and Neural Network. Under different event rates, models were comprehensively evaluated and compared based on Kolmogorov-Smirnov Statistic, accuracy, F1 score, Type I error, Type II error, and ROC curve on the hold-out dataset with their best probability cut-offs. Results show that Bayesian Network is the most insensitive to the event rate, while Support Vector Machine is the most sensitive.