 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight 'em Up: Enabling Few-Shot Low-Light 3D Gaussian Splatting with Multi-Scale Explicit Retinex Illumination Decoupling
Apr 27, 2026Full 360$^\circ$ novel view synthesis under low-light conditions remains challenging. Insufficient illumination, noise amplification, and view-dependent photometric inconsistencies prevent existing methods from jointly preserving geometric consistency and photorealism. Unsupervised approaches often exhibit color drift under large viewpoint variations, while supervised low-light enhancement models, though effective for 2D tasks, struggle to generalize to new scenes and typically require retraining. To address this issue, we propose MERID-GS, a Multi-Scale Explicit Retinex Illumination-Decoupled Gaussian framework for low-light 360$^\circ$ synthesis. Based on Retinex theory, the method explicitly separates illumination and reflectance, and suppresses noise propagation while enhancing dark-region structures via a learnable gain and Illumination-State-Guided Frequency Gating. Combined with lightweight Reflection Head and 3D Gaussian Splatting, MERID-GS adapts to new scenes with only a few shots and enables stable low-light novel view synthesis from sparse-view observations. In addition, we construct a low-light multi-view dataset covering full 360$^\circ$ scenes for joint evaluation. Thorough experiments across multiple datasets in this area demonstrate that MERID-GS achieves SOTA performance, exhibiting superior cross-scene generalization and view consistency. The source code and pre-trained models are available at https://github.com/YhuoyuH/MERID-GS..
POCA: Pareto-Optimal Curriculum Alignment for Visual Text Generation
Apr 27, 2026Current visual text generation models struggle with the trade-off between text accuracy and overall image coherence. We find that achieving high text accuracy can reduce aesthetic quality and instruction-following capability. Although reinforcement learning approaches can alleviate the problem through aligning with multiple rewards, they are often unstable for text generation, as existing approaches normally optimize multiple rewards in a weighted-sum way. In addition, it is difficult to balance the weight of each reward. Moreover, reinforcement learning requires a set of training instructions. A large number of prompts require more training time and computing resources, while a small set leads to poor performance. Hence, how to select the prompts for efficient training is an unsolved problem. In this study, we propose Pareto-Optimal Curriculum Alignment (POCA), a framework that addresses this issue as a multi-objective problem by: 1) identifying the Pareto-optimal set to avoid simple scalarization and 2) designing an adaptive curriculum alignment strategy to manage a learning sequence of a multi-reward dataset using automatic difficulty assessment, which is crucial for optimal convergence as RL methods explore in a limited data environment. In synergy, POCA finds the Pareto-optimal set in a unified reward space, which eliminates inconsistent signals to find the best trade-off solution from different rewards under an easy-to-hard optimization landscape. The experimental results show that POCA significantly improves all metrics such as CLIP, HPS scores and sentence accuracy.
Hackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
Apr 07, 2026The rapid advancement of Large Language Models (LLMs) has created new opportunities for Automated Penetration Testing (AutoPT), spawning numerous frameworks aimed at achieving end-to-end autonomous attacks. However, despite the proliferation of related studies, existing research generally lacks systematic architectural analysis and large-scale empirical comparisons under a unified benchmark. Therefore, this paper presents the first Systematization of Knowledge (SoK) focusing on the architectural design and comprehensive empirical evaluation of current LLM-based AutoPT frameworks. At systematization level, we comprehensively review existing framework designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks. At empirical level, we conduct large-scale experiments on 13 representative open-source AutoPT frameworks and 2 baseline frameworks utilizing a unified benchmark. The experiments consumed over 10 billion tokens in total and generated more than 1,500 execution logs, which were manually reviewed and analyzed over four months by a panel of more than 15 researchers with expertise in cybersecurity. By investigating the latest progress in this rapidly developing field, we provide researchers with a structured taxonomy to understand existing LLM-based AutoPT frameworks and a large-scale empirical benchmark, along with promising directions for future research.
Confidence-Calibrated Small-Large Language Model Collaboration for Cost-Efficient Reasoning
Mar 04, 2026Large language models (LLMs) demonstrate superior reasoning capabilities compared to small language models (SLMs), but incur substantially higher costs. We propose COllaborative REAsoner (COREA), a system that cascades an SLM with an LLM to achieve a balance between accuracy and cost in complex reasoning tasks. COREA first attempts to answer questions using the SLM, which outputs both an answer and a verbalized confidence score. Questions with confidence below a predefined threshold are deferred to the LLM for more accurate resolution. We introduce a reinforcement learning-based training algorithm that aligns the SLM's confidence through an additional confidence calibration reward. Extensive experiments demonstrate that our method jointly improves the SLM's reasoning ability and confidence calibration across diverse datasets and model backbones. Compared to using the LLM alone, COREA reduces cost by 21.5% and 16.8% on out-of-domain math and non-math datasets, respectively, with only an absolute pass@1 drop within 2%.
Team of Thoughts: Efficient Test-time Scaling of Agentic Systems through Orchestrated Tool Calling
Feb 18, 2026Existing Multi-Agent Systems (MAS) typically rely on static, homogeneous model configurations, limiting their ability to exploit the distinct strengths of differently post-trained models. To address this, we introduce Team-of-Thoughts, a novel MAS architecture that leverages the complementary capabilities of heterogeneous agents via an orchestrator-tool paradigm. Our framework introduces two key mechanisms to optimize performance: (1) an orchestrator calibration scheme that identifies models with superior coordination capabilities, and (2) a self-assessment protocol where tool agents profile their own domain expertise to account for variations in post-training skills. During inference, the orchestrator dynamically activates the most suitable tool agents based on these proficiency profiles. Experiments on five reasoning and code generation benchmarks show that Team-of-Thoughts delivers consistently superior task performance. Notably, on AIME24 and LiveCodeBench, our approach achieves accuracies of 96.67% and 72.53%, respectively, substantially outperforming homogeneous role-play baselines, which score 80% and 65.93%.
Heterogeneous Computing: The Key to Powering the Future of AI Agent Inference
Jan 29, 2026AI agent inference is driving an inference heavy datacenter future and exposes bottlenecks beyond compute - especially memory capacity, memory bandwidth and high-speed interconnect. We introduce two metrics - Operational Intensity (OI) and Capacity Footprint (CF) - that jointly explain regimes the classic roofline analysis misses, including the memory capacity wall. Across agentic workflows (chat, coding, web use, computer use) and base model choices (GQA/MLA, MoE, quantization), OI/CF can shift dramatically, with long context KV cache making decode highly memory bound. These observations motivate disaggregated serving and system level heterogeneity: specialized prefill and decode accelerators, broader scale up networking, and decoupled compute-memory enabled by optical I/O. We further hypothesize agent-hardware co design, multiple inference accelerators within one system, and high bandwidth, large capacity memory disaggregation as foundations for adaptation to evolving OI/CF. Together, these directions chart a path to sustain efficiency and capability for large scale agentic AI inference.
Offline Policy Learning with Weight Clipping and Heaviside Composite Optimization
Jan 17, 2026Offline policy learning aims to use historical data to learn an optimal personalized decision rule. In the standard estimate-then-optimize framework, reweighting-based methods (e.g., inverse propensity weighting or doubly robust estimators) are widely used to produce unbiased estimates of policy values. However, when the propensity scores of some treatments are small, these reweighting-based methods suffer from high variance in policy value estimation, which may mislead the downstream policy optimization and yield a learned policy with inferior value. In this paper, we systematically develop an offline policy learning algorithm based on a weight-clipping estimator that truncates small propensity scores via a clipping threshold chosen to minimize the mean squared error (MSE) in policy value estimation. Focusing on linear policies, we address the bilevel and discontinuous objective induced by weight-clipping-based policy optimization by reformulating the problem as a Heaviside composite optimization problem, which provides a rigorous computational framework. The reformulated policy optimization problem is then solved efficiently using the progressive integer programming method, making practical policy learning tractable. We establish an upper bound for the suboptimality of the proposed algorithm, which reveals how the reduction in MSE of policy value estimation, enabled by our proposed weight-clipping estimator, leads to improved policy learning performance.
Statistical Robustness of Interval CVaR Based Regression Models under Perturbation and Contamination
Jan 16, 2026Robustness under perturbation and contamination is a prominent issue in statistical learning. We address the robust nonlinear regression based on the so-called interval conditional value-at-risk (In-CVaR), which is introduced to enhance robustness by trimming extreme losses. While recent literature shows that the In-CVaR based statistical learning exhibits superior robustness performance than classical robust regression models, its theoretical robustness analysis for nonlinear regression remains largely unexplored. We rigorously quantify robustness under contamination, with a unified study of distributional breakdown point for a broad class of regression models, including linear, piecewise affine and neural network models with $\ell_1$, $\ell_2$ and Huber losses. Moreover, we analyze the qualitative robustness of the In-CVaR based estimator under perturbation. We show that under several minor assumptions, the In-CVaR based estimator is qualitatively robust in terms of the Prokhorov metric if and only if the largest portion of losses is trimmed. Overall, this study analyzes robustness properties of In-CVaR based nonlinear regression models under both perturbation and contamination, which illustrates the advantages of In-CVaR risk measure over conditional value-at-risk and expectation for robust regression in both theory and numerical experiments.
Sentiment-Aware Extractive and Abstractive Summarization for Unstructured Text Mining
Dec 23, 2025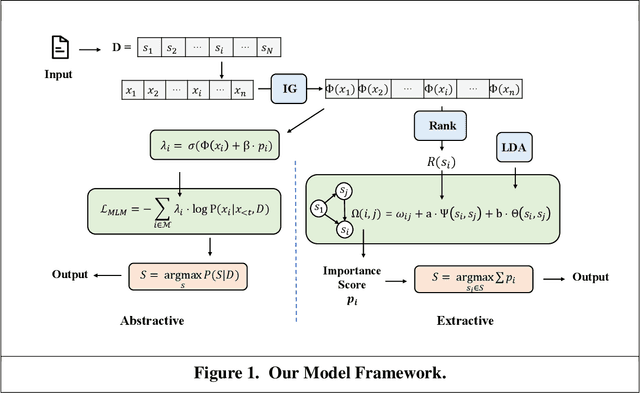
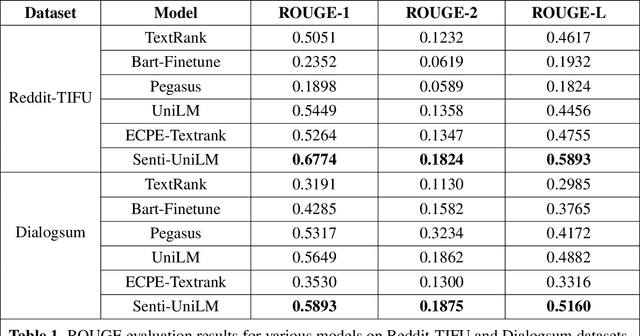
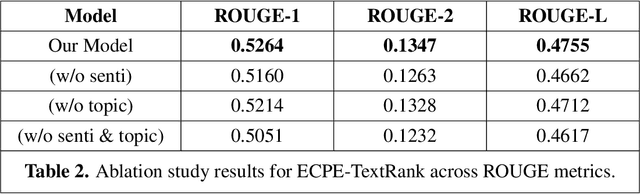
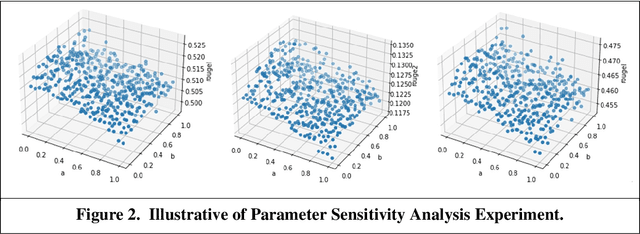
With the rapid growth of unstructured data from social media, reviews, and forums, text mining has become essential in Information Systems (IS) for extracting actionable insights. Summarization can condense fragmented, emotion-rich posts, but existing methods-optimized for structured news-struggle with noisy, informal content. Emotional cues are critical for IS tasks such as brand monitoring and market analysis, yet few studies integrate sentiment modeling into summarization of short user-generated texts. We propose a sentiment-aware framework extending extractive (TextRank) and abstractive (UniLM) approaches by embedding sentiment signals into ranking and generation processes. This dual design improves the capture of emotional nuances and thematic relevance, producing concise, sentiment-enriched summaries that enhance timely interventions and strategic decision-making in dynamic online environments.
Practical Global and Local Bounds in Gaussian Process Regression via Chaining
Nov 17, 2025Gaussian process regression (GPR) is a popular nonparametric Bayesian method that provides predictive uncertainty estimates and is widely used in safety-critical applications. While prior research has introduced various uncertainty bounds, most existing approaches require access to specific input features, and rely on posterior mean and variance estimates or the tuning of hyperparameters. These limitations hinder robustness and fail to capture the model's global behavior in expectation. To address these limitations, we propose a chaining-based framework for estimating upper and lower bounds on the expected extreme values over unseen data, without requiring access to specific input features. We provide kernel-specific refinements for commonly used kernels such as RBF and Matérn, in which our bounds are tighter than generic constructions. We further improve numerical tightness by avoiding analytical relaxations. In addition to global estimation, we also develop a novel method for local uncertainty quantification at specified inputs. This approach leverages chaining geometry through partition diameters, adapting to local structures without relying on posterior variance scaling. Our experimental results validate the theoretical findings and demonstrate that our method outperforms existing approaches on both synthetic and real-world datasets.