 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnockoff-Guided Compressive Sensing: A Statistical Machine Learning Framework for Support-Assured Signal Recovery
May 30, 2025This paper introduces a novel Knockoff-guided compressive sensing framework, referred to as \TheName{}, which enhances signal recovery by leveraging precise false discovery rate (FDR) control during the support identification phase. Unlike LASSO, which jointly performs support selection and signal estimation without explicit error control, our method guarantees FDR control in finite samples, enabling more reliable identification of the true signal support. By separating and controlling the support recovery process through statistical Knockoff filters, our framework achieves more accurate signal reconstruction, especially in challenging scenarios where traditional methods fail. We establish theoretical guarantees demonstrating how FDR control directly ensures recovery performance under weaker conditions than traditional $\ell_1$-based compressive sensing methods, while maintaining accurate signal reconstruction. Extensive numerical experiments demonstrate that our proposed Knockoff-based method consistently outperforms LASSO-based and other state-of-the-art compressive sensing techniques. In simulation studies, our method improves F1-score by up to 3.9x over baseline methods, attributed to principled false discovery rate (FDR) control and enhanced support recovery. The method also consistently yields lower reconstruction and relative errors. We further validate the framework on real-world datasets, where it achieves top downstream predictive performance across both regression and classification tasks, often narrowing or even surpassing the performance gap relative to uncompressed signals. These results establish \TheName{} as a robust and practical alternative to existing approaches, offering both theoretical guarantees and strong empirical performance through statistically grounded support selection.
Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models
May 21, 2025Large Language Models (LLMs) demonstrate the ability to solve reasoning and mathematical problems using the Chain-of-Thought (CoT) technique. Expanding CoT length, as seen in models such as DeepSeek-R1, significantly enhances this reasoning for complex problems, but requires costly and high-quality long CoT data and fine-tuning. This work, inspired by the deep thinking paradigm of DeepSeek-R1, utilizes a steering technique to enhance the reasoning ability of an LLM without external datasets. Our method first employs Sparse Autoencoders (SAEs) to extract interpretable features from vanilla CoT. These features are then used to steer the LLM's internal states during generation. Recognizing that many LLMs do not have corresponding pre-trained SAEs, we further introduce a novel SAE-free steering algorithm, which directly computes steering directions from the residual activations of an LLM, obviating the need for an explicit SAE. Experimental results demonstrate that both our SAE-based and subsequent SAE-free steering algorithms significantly enhance the reasoning capabilities of LLMs.
Semantic SLAM with Rolling-Shutter Cameras and Low-Precision INS in Outdoor Environments
Apr 01, 2025Accurate localization and mapping in outdoor environments remains challenging when using consumer-grade hardware, particularly with rolling-shutter cameras and low-precision inertial navigation systems (INS). We present a novel semantic SLAM approach that leverages road elements such as lane boundaries, traffic signs, and road markings to enhance localization accuracy. Our system integrates real-time semantic feature detection with a graph optimization framework, effectively handling both rolling-shutter effects and INS drift. Using a practical hardware setup which consists of a rolling-shutter camera (3840*2160@30fps), IMU (100Hz), and wheel encoder (50Hz), we demonstrate significant improvements over existing methods. Compared to state-of-the-art approaches, our method achieves higher recall (up to 5.35\%) and precision (up to 2.79\%) in semantic element detection, while maintaining mean relative error (MRE) within 10cm and mean absolute error (MAE) around 1m. Extensive experiments in diverse urban environments demonstrate the robust performance of our system under varying lighting conditions and complex traffic scenarios, making it particularly suitable for autonomous driving applications. The proposed approach provides a practical solution for high-precision localization using affordable hardware, bridging the gap between consumer-grade sensors and production-level performance requirements.
Video-based Traffic Light Recognition by Rockchip RV1126 for Autonomous Driving
Mar 31, 2025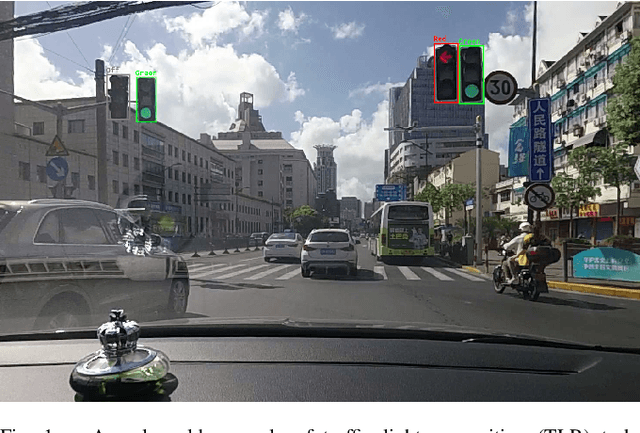
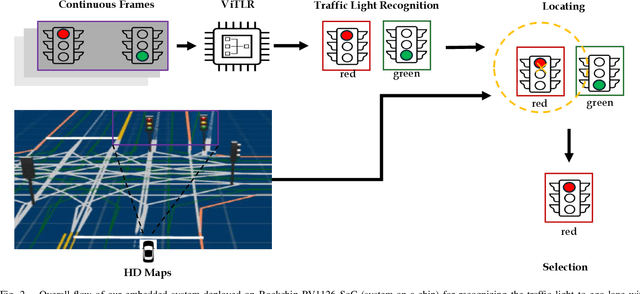
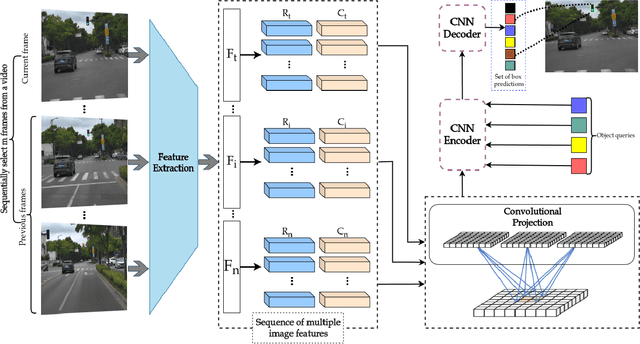
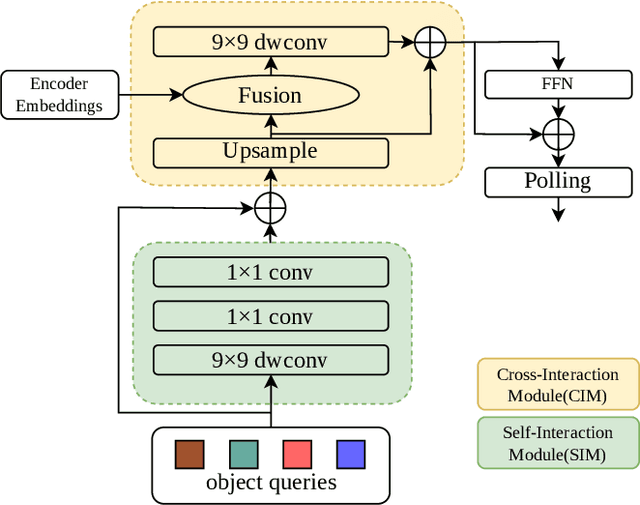
Real-time traffic light recognition is fundamental for autonomous driving safety and navigation in urban environments. While existing approaches rely on single-frame analysis from onboard cameras, they struggle with complex scenarios involving occlusions and adverse lighting conditions. We present \textit{ViTLR}, a novel video-based end-to-end neural network that processes multiple consecutive frames to achieve robust traffic light detection and state classification. The architecture leverages a transformer-like design with convolutional self-attention modules, which is optimized specifically for deployment on the Rockchip RV1126 embedded platform. Extensive evaluations on two real-world datasets demonstrate that \textit{ViTLR} achieves state-of-the-art performance while maintaining real-time processing capabilities (>25 FPS) on RV1126's NPU. The system shows superior robustness across temporal stability, varying target distances, and challenging environmental conditions compared to existing single-frame approaches. We have successfully integrated \textit{ViTLR} into an ego-lane traffic light recognition system using HD maps for autonomous driving applications. The complete implementation, including source code and datasets, is made publicly available to facilitate further research in this domain.
A Concise Survey on Lane Topology Reasoning for HD Mapping
Mar 31, 2025



Lane topology reasoning techniques play a crucial role in high-definition (HD) mapping and autonomous driving applications. While recent years have witnessed significant advances in this field, there has been limited effort to consolidate these works into a comprehensive overview. This survey systematically reviews the evolution and current state of lane topology reasoning methods, categorizing them into three major paradigms: procedural modeling-based methods, aerial imagery-based methods, and onboard sensors-based methods. We analyze the progression from early rule-based approaches to modern learning-based solutions utilizing transformers, graph neural networks (GNNs), and other deep learning architectures. The paper examines standardized evaluation metrics, including road-level measures (APLS and TLTS score), and lane-level metrics (DET and TOP score), along with performance comparisons on benchmark datasets such as OpenLane-V2. We identify key technical challenges, including dataset availability and model efficiency, and outline promising directions for future research. This comprehensive review provides researchers and practitioners with insights into the theoretical frameworks, practical implementations, and emerging trends in lane topology reasoning for HD mapping applications.
A Benchmark for Vision-Centric HD Mapping by V2I Systems
Mar 31, 2025



Autonomous driving faces safety challenges due to a lack of global perspective and the semantic information of vectorized high-definition (HD) maps. Information from roadside cameras can greatly expand the map perception range through vehicle-to-infrastructure (V2I) communications. However, there is still no dataset from the real world available for the study on map vectorization onboard under the scenario of vehicle-infrastructure cooperation. To prosper the research on online HD mapping for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release a real-world dataset, which contains collaborative camera frames from both vehicles and roadside infrastructures, and provides human annotations of HD map elements. We also present an end-to-end neural framework (i.e., V2I-HD) leveraging vision-centric V2I systems to construct vectorized maps. To reduce computation costs and further deploy V2I-HD on autonomous vehicles, we introduce a directionally decoupled self-attention mechanism to V2I-HD. Extensive experiments show that V2I-HD has superior performance in real-time inference speed, as tested by our real-world dataset. Abundant qualitative results also demonstrate stable and robust map construction quality with low cost in complex and various driving scenes. As a benchmark, both source codes and the dataset have been released at OneDrive for the purpose of further study.
Evaluating LLM-based Agents for Multi-Turn Conversations: A Survey
Mar 28, 2025This survey examines evaluation methods for large language model (LLM)-based agents in multi-turn conversational settings. Using a PRISMA-inspired framework, we systematically reviewed nearly 250 scholarly sources, capturing the state of the art from various venues of publication, and establishing a solid foundation for our analysis. Our study offers a structured approach by developing two interrelated taxonomy systems: one that defines \emph{what to evaluate} and another that explains \emph{how to evaluate}. The first taxonomy identifies key components of LLM-based agents for multi-turn conversations and their evaluation dimensions, including task completion, response quality, user experience, memory and context retention, as well as planning and tool integration. These components ensure that the performance of conversational agents is assessed in a holistic and meaningful manner. The second taxonomy system focuses on the evaluation methodologies. It categorizes approaches into annotation-based evaluations, automated metrics, hybrid strategies that combine human assessments with quantitative measures, and self-judging methods utilizing LLMs. This framework not only captures traditional metrics derived from language understanding, such as BLEU and ROUGE scores, but also incorporates advanced techniques that reflect the dynamic, interactive nature of multi-turn dialogues.
SOLA-GCL: Subgraph-Oriented Learnable Augmentation Method for Graph Contrastive Learning
Mar 13, 2025Graph contrastive learning has emerged as a powerful technique for learning graph representations that are robust and discriminative. However, traditional approaches often neglect the critical role of subgraph structures, particularly the intra-subgraph characteristics and inter-subgraph relationships, which are crucial for generating informative and diverse contrastive pairs. These subgraph features are crucial as they vary significantly across different graph types, such as social networks where they represent communities, and biochemical networks where they symbolize molecular interactions. To address this issue, our work proposes a novel subgraph-oriented learnable augmentation method for graph contrastive learning, termed SOLA-GCL, that centers around subgraphs, taking full advantage of the subgraph information for data augmentation. Specifically, SOLA-GCL initially partitions a graph into multiple densely connected subgraphs based on their intrinsic properties. To preserve and enhance the unique characteristics inherent to subgraphs, a graph view generator optimizes augmentation strategies for each subgraph, thereby generating tailored views for graph contrastive learning. This generator uses a combination of intra-subgraph and inter-subgraph augmentation strategies, including node dropping, feature masking, intra-edge perturbation, inter-edge perturbation, and subgraph swapping. Extensive experiments have been conducted on various graph learning applications, ranging from social networks to molecules, under semi-supervised learning, unsupervised learning, and transfer learning settings to demonstrate the superiority of our proposed approach over the state-of-the-art in GCL.
Knoop: Practical Enhancement of Knockoff with Over-Parameterization for Variable Selection
Jan 28, 2025Variable selection plays a crucial role in enhancing modeling effectiveness across diverse fields, addressing the challenges posed by high-dimensional datasets of correlated variables. This work introduces a novel approach namely Knockoff with over-parameterization (Knoop) to enhance Knockoff filters for variable selection. Specifically, Knoop first generates multiple knockoff variables for each original variable and integrates them with the original variables into an over-parameterized Ridgeless regression model. For each original variable, Knoop evaluates the coefficient distribution of its knockoffs and compares these with the original coefficients to conduct an anomaly-based significance test, ensuring robust variable selection. Extensive experiments demonstrate superior performance compared to existing methods in both simulation and real-world datasets. Knoop achieves a notably higher Area under the Curve (AUC) of the Receiver Operating Characteristic (ROC) Curve for effectively identifying relevant variables against the ground truth by controlled simulations, while showcasing enhanced predictive accuracy across diverse regression and classification tasks. The analytical results further backup our observations.
* An earlier version of our paper at Machine Learning
EICopilot: Search and Explore Enterprise Information over Large-scale Knowledge Graphs with LLM-driven Agents
Jan 23, 2025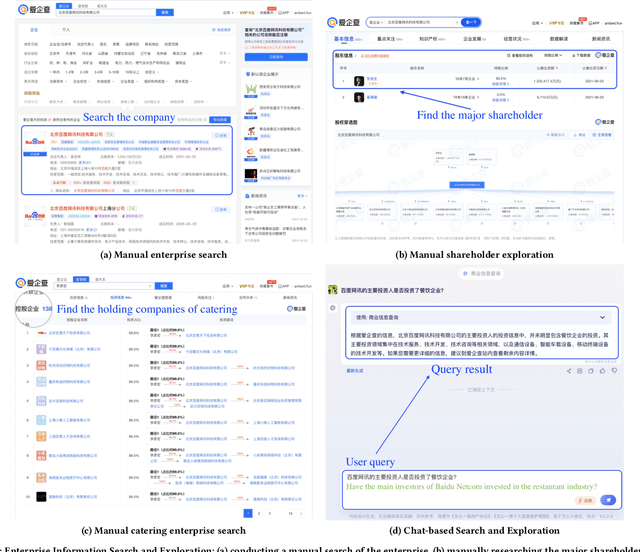
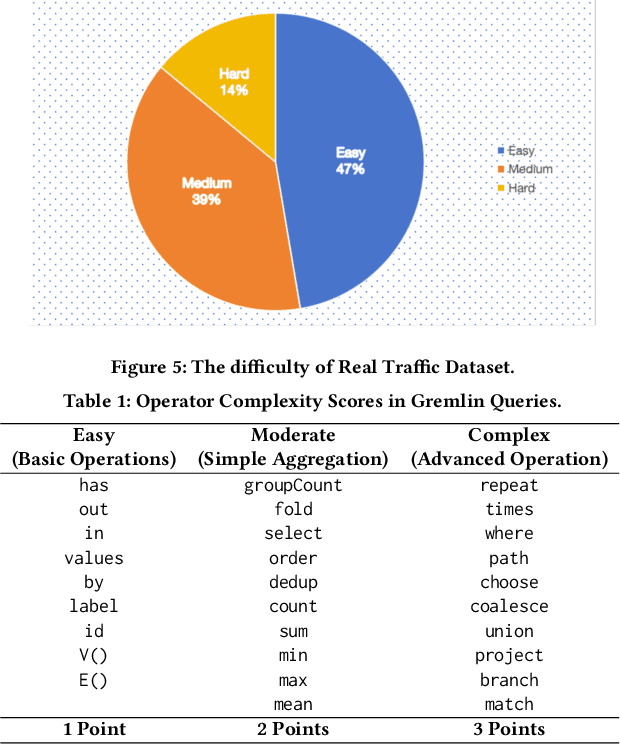
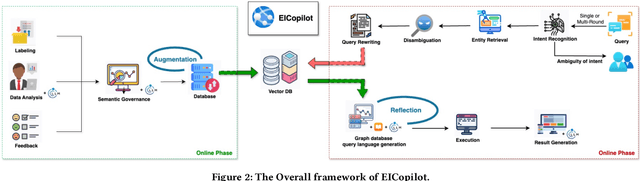
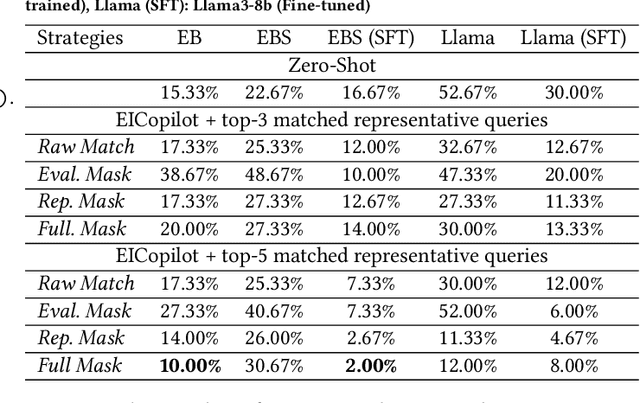
The paper introduces EICopilot, an novel agent-based solution enhancing search and exploration of enterprise registration data within extensive online knowledge graphs like those detailing legal entities, registered capital, and major shareholders. Traditional methods necessitate text-based queries and manual subgraph explorations, often resulting in time-consuming processes. EICopilot, deployed as a chatbot via Baidu Enterprise Search, improves this landscape by utilizing Large Language Models (LLMs) to interpret natural language queries. This solution automatically generates and executes Gremlin scripts, providing efficient summaries of complex enterprise relationships. Distinct feature a data pre-processing pipeline that compiles and annotates representative queries into a vector database of examples for In-context learning (ICL), a comprehensive reasoning pipeline combining Chain-of-Thought with ICL to enhance Gremlin script generation for knowledge graph search and exploration, and a novel query masking strategy that improves intent recognition for heightened script accuracy. Empirical evaluations demonstrate the superior performance of EICopilot, including speed and accuracy, over baseline methods, with the \emph{Full Mask} variant achieving a syntax error rate reduction to as low as 10.00% and an execution correctness of up to 82.14%. These components collectively contribute to superior querying capabilities and summarization of intricate datasets, positioning EICopilot as a groundbreaking tool in the exploration and exploitation of large-scale knowledge graphs for enterprise information search.