 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic SLAM with Rolling-Shutter Cameras and Low-Precision INS in Outdoor Environments
Apr 01, 2025Accurate localization and mapping in outdoor environments remains challenging when using consumer-grade hardware, particularly with rolling-shutter cameras and low-precision inertial navigation systems (INS). We present a novel semantic SLAM approach that leverages road elements such as lane boundaries, traffic signs, and road markings to enhance localization accuracy. Our system integrates real-time semantic feature detection with a graph optimization framework, effectively handling both rolling-shutter effects and INS drift. Using a practical hardware setup which consists of a rolling-shutter camera (3840*2160@30fps), IMU (100Hz), and wheel encoder (50Hz), we demonstrate significant improvements over existing methods. Compared to state-of-the-art approaches, our method achieves higher recall (up to 5.35\%) and precision (up to 2.79\%) in semantic element detection, while maintaining mean relative error (MRE) within 10cm and mean absolute error (MAE) around 1m. Extensive experiments in diverse urban environments demonstrate the robust performance of our system under varying lighting conditions and complex traffic scenarios, making it particularly suitable for autonomous driving applications. The proposed approach provides a practical solution for high-precision localization using affordable hardware, bridging the gap between consumer-grade sensors and production-level performance requirements.
A Benchmark for Vision-Centric HD Mapping by V2I Systems
Mar 31, 2025



Autonomous driving faces safety challenges due to a lack of global perspective and the semantic information of vectorized high-definition (HD) maps. Information from roadside cameras can greatly expand the map perception range through vehicle-to-infrastructure (V2I) communications. However, there is still no dataset from the real world available for the study on map vectorization onboard under the scenario of vehicle-infrastructure cooperation. To prosper the research on online HD mapping for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release a real-world dataset, which contains collaborative camera frames from both vehicles and roadside infrastructures, and provides human annotations of HD map elements. We also present an end-to-end neural framework (i.e., V2I-HD) leveraging vision-centric V2I systems to construct vectorized maps. To reduce computation costs and further deploy V2I-HD on autonomous vehicles, we introduce a directionally decoupled self-attention mechanism to V2I-HD. Extensive experiments show that V2I-HD has superior performance in real-time inference speed, as tested by our real-world dataset. Abundant qualitative results also demonstrate stable and robust map construction quality with low cost in complex and various driving scenes. As a benchmark, both source codes and the dataset have been released at OneDrive for the purpose of further study.
Video-based Traffic Light Recognition by Rockchip RV1126 for Autonomous Driving
Mar 31, 2025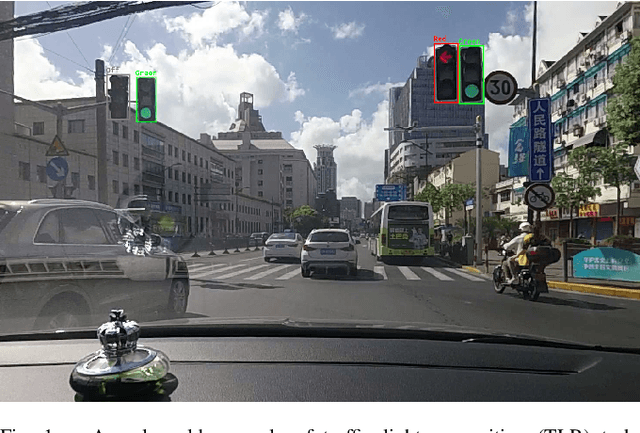
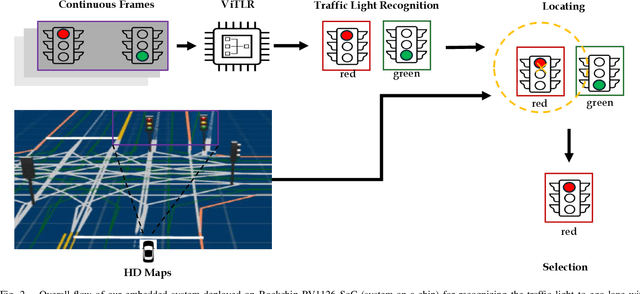
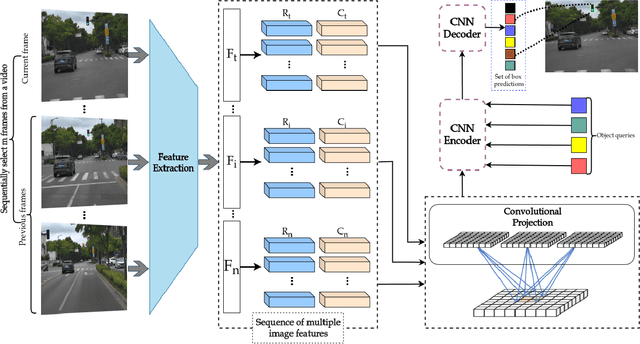
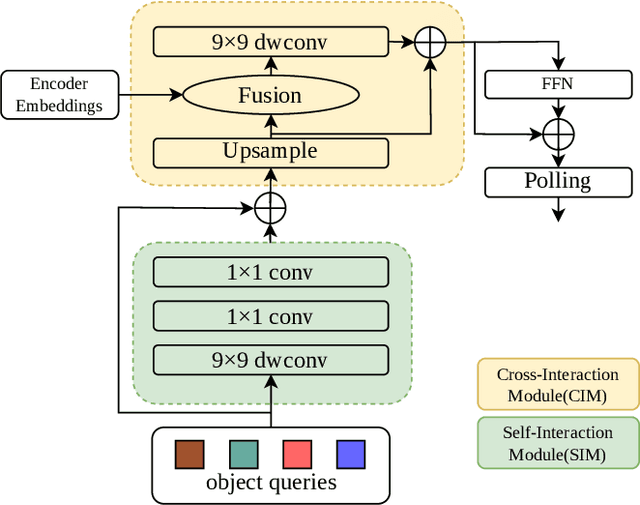
Real-time traffic light recognition is fundamental for autonomous driving safety and navigation in urban environments. While existing approaches rely on single-frame analysis from onboard cameras, they struggle with complex scenarios involving occlusions and adverse lighting conditions. We present \textit{ViTLR}, a novel video-based end-to-end neural network that processes multiple consecutive frames to achieve robust traffic light detection and state classification. The architecture leverages a transformer-like design with convolutional self-attention modules, which is optimized specifically for deployment on the Rockchip RV1126 embedded platform. Extensive evaluations on two real-world datasets demonstrate that \textit{ViTLR} achieves state-of-the-art performance while maintaining real-time processing capabilities (>25 FPS) on RV1126's NPU. The system shows superior robustness across temporal stability, varying target distances, and challenging environmental conditions compared to existing single-frame approaches. We have successfully integrated \textit{ViTLR} into an ego-lane traffic light recognition system using HD maps for autonomous driving applications. The complete implementation, including source code and datasets, is made publicly available to facilitate further research in this domain.
A Concise Survey on Lane Topology Reasoning for HD Mapping
Mar 31, 2025



Lane topology reasoning techniques play a crucial role in high-definition (HD) mapping and autonomous driving applications. While recent years have witnessed significant advances in this field, there has been limited effort to consolidate these works into a comprehensive overview. This survey systematically reviews the evolution and current state of lane topology reasoning methods, categorizing them into three major paradigms: procedural modeling-based methods, aerial imagery-based methods, and onboard sensors-based methods. We analyze the progression from early rule-based approaches to modern learning-based solutions utilizing transformers, graph neural networks (GNNs), and other deep learning architectures. The paper examines standardized evaluation metrics, including road-level measures (APLS and TLTS score), and lane-level metrics (DET and TOP score), along with performance comparisons on benchmark datasets such as OpenLane-V2. We identify key technical challenges, including dataset availability and model efficiency, and outline promising directions for future research. This comprehensive review provides researchers and practitioners with insights into the theoretical frameworks, practical implementations, and emerging trends in lane topology reasoning for HD mapping applications.
MONOPOLY: Learning to Price Public Facilities for Revaluing Private Properties with Large-Scale Urban Data
Nov 27, 2024The value assessment of private properties is an attractive but challenging task which is widely concerned by a majority of people around the world. A prolonged topic among us is ``\textit{how much is my house worth?}''. To answer this question, most experienced agencies would like to price a property given the factors of its attributes as well as the demographics and the public facilities around it. However, no one knows the exact prices of these factors, especially the values of public facilities which may help assess private properties. In this paper, we introduce our newly launched project ``Monopoly'' (named after a classic board game) in which we propose a distributed approach for revaluing private properties by learning to price public facilities (such as hospitals etc.) with the large-scale urban data we have accumulated via Baidu Maps. To be specific, our method organizes many points of interest (POIs) into an undirected weighted graph and formulates multiple factors including the virtual prices of surrounding public facilities as adaptive variables to parallelly estimate the housing prices we know. Then the prices of both public facilities and private properties can be iteratively updated according to the loss of prediction until convergence. We have conducted extensive experiments with the large-scale urban data of several metropolises in China. Results show that our approach outperforms several mainstream methods with significant margins. Further insights from more in-depth discussions demonstrate that the ``Monopoly'' is an innovative application in the interdisciplinary field of business intelligence and urban computing, and it will be beneficial to tens of millions of our users for investments and to the governments for urban planning as well as taxation.
DuMapper: Towards Automatic Verification of Large-Scale POIs with Street Views at Baidu Maps
Nov 27, 2024
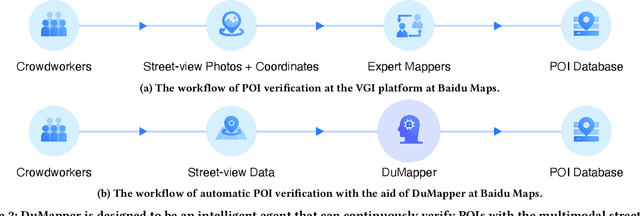

With the increased popularity of mobile devices, Web mapping services have become an indispensable tool in our daily lives. To provide user-satisfied services, such as location searches, the point of interest (POI) database is the fundamental infrastructure, as it archives multimodal information on billions of geographic locations closely related to people's lives, such as a shop or a bank. Therefore, verifying the correctness of a large-scale POI database is vital. To achieve this goal, many industrial companies adopt volunteered geographic information (VGI) platforms that enable thousands of crowdworkers and expert mappers to verify POIs seamlessly; but to do so, they have to spend millions of dollars every year. To save the tremendous labor costs, we devised DuMapper, an automatic system for large-scale POI verification with the multimodal street-view data at Baidu Maps. DuMapper takes the signboard image and the coordinates of a real-world place as input to generate a low-dimensional vector, which can be leveraged by ANN algorithms to conduct a more accurate search through billions of archived POIs in the database for verification within milliseconds. It can significantly increase the throughput of POI verification by $50$ times. DuMapper has already been deployed in production since \DuMPOnline, which dramatically improves the productivity and efficiency of POI verification at Baidu Maps. As of December 31, 2021, it has enacted over $405$ million iterations of POI verification within a 3.5-year period, representing an approximate workload of $800$ high-performance expert mappers.
Personalized Route Recommendation Based on User Habits for Vehicle Navigation
Sep 21, 2024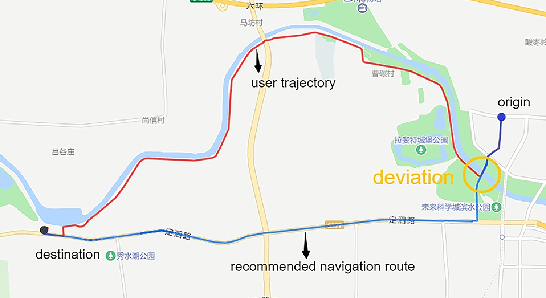

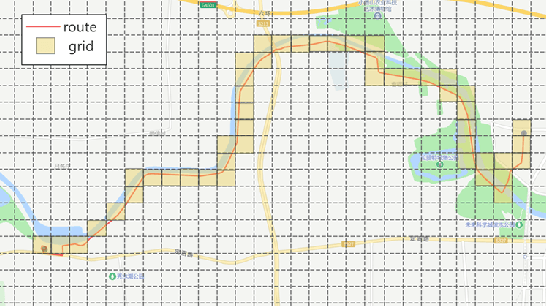
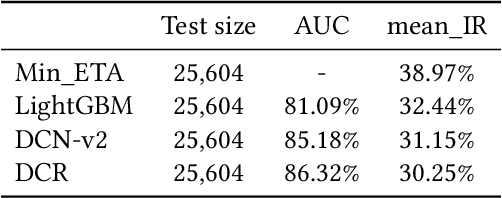
Navigation route recommendation is one of the important functions of intelligent transportation. However, users frequently deviate from recommended routes for various reasons, with personalization being a key problem in the field of research. This paper introduces a personalized route recommendation method based on user historical navigation data. First, we formulate route sorting as a pointwise problem based on a large set of pertinent features. Second, we construct route features and user profiles to establish a comprehensive feature dataset. Furthermore, we propose a Deep-Cross-Recurrent (DCR) learning model aimed at learning route sorting scores and offering customized route recommendations. This approach effectively captures recommended navigation routes and user preferences by integrating DCN-v2 and LSTM. In offline evaluations, our method compared with the minimum ETA (estimated time of arrival), LightGBM, and DCN-v2 indicated 8.72%, 2.19%, and 0.9% reduction in the mean inconsistency rate respectively, demonstrating significant improvements in recommendation accuracy.
Large Margin Prototypical Network for Few-shot Relation Classification with Fine-grained Features
Sep 06, 2024Relation classification (RC) plays a pivotal role in both natural language understanding and knowledge graph completion. It is generally formulated as a task to recognize the relationship between two entities of interest appearing in a free-text sentence. Conventional approaches on RC, regardless of feature engineering or deep learning based, can obtain promising performance on categorizing common types of relation leaving a large proportion of unrecognizable long-tail relations due to insufficient labeled instances for training. In this paper, we consider few-shot learning is of great practical significance to RC and thus improve a modern framework of metric learning for few-shot RC. Specifically, we adopt the large-margin ProtoNet with fine-grained features, expecting they can generalize well on long-tail relations. Extensive experiments were conducted by FewRel, a large-scale supervised few-shot RC dataset, to evaluate our framework: LM-ProtoNet (FGF). The results demonstrate that it can achieve substantial improvements over many baseline approaches.
HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
Sep 05, 2024



The increasing interest in international travel has raised the demand of retrieving point of interests in multiple languages. This is even superior to find local venues such as restaurants and scenic spots in unfamiliar languages when traveling abroad. Multilingual POI retrieval, enabling users to find desired POIs in a demanded language using queries in numerous languages, has become an indispensable feature of today's global map applications such as Baidu Maps. This task is non-trivial because of two key challenges: (1) visiting sparsity and (2) multilingual query-POI matching. To this end, we propose a Heterogeneous Graph Attention Matching Network (HGAMN) to concurrently address both challenges. Specifically, we construct a heterogeneous graph that contains two types of nodes: POI node and query node using the search logs of Baidu Maps. To alleviate challenge \#1, we construct edges between different POI nodes to link the low-frequency POIs with the high-frequency ones, which enables the transfer of knowledge from the latter to the former. To mitigate challenge \#2, we construct edges between POI and query nodes based on the co-occurrences between queries and POIs, where queries in different languages and formulations can be aggregated for individual POIs. Moreover, we develop an attention-based network to jointly learn node representations of the heterogeneous graph and further design a cross-attention module to fuse the representations of both types of nodes for query-POI relevance scoring. Extensive experiments conducted on large-scale real-world datasets from Baidu Maps demonstrate the superiority and effectiveness of HGAMN. In addition, HGAMN has already been deployed in production at Baidu Maps, and it successfully keeps serving hundreds of millions of requests every day.
MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search
Sep 05, 2024


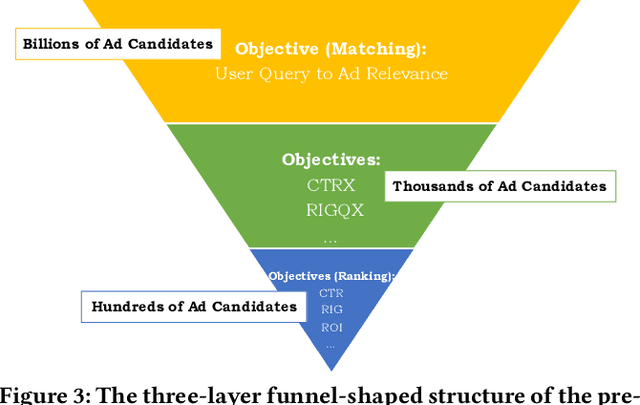
Baidu runs the largest commercial web search engine in China, serving hundreds of millions of online users every day in response to a great variety of queries. In order to build a high-efficiency sponsored search engine, we used to adopt a three-layer funnel-shaped structure to screen and sort hundreds of ads from billions of ad candidates subject to the requirement of low response latency and the restraints of computing resources. Given a user query, the top matching layer is responsible for providing semantically relevant ad candidates to the next layer, while the ranking layer at the bottom concerns more about business indicators (e.g., CPM, ROI, etc.) of those ads. The clear separation between the matching and ranking objectives results in a lower commercial return. The Mobius project has been established to address this serious issue. It is our first attempt to train the matching layer to consider CPM as an additional optimization objective besides the query-ad relevance, via directly predicting CTR (click-through rate) from billions of query-ad pairs. Specifically, this paper will elaborate on how we adopt active learning to overcome the insufficiency of click history at the matching layer when training our neural click networks offline, and how we use the SOTA ANN search technique for retrieving ads more efficiently (Here ``ANN'' stands for approximate nearest neighbor search). We contribute the solutions to Mobius-V1 as the first version of our next generation query-ad matching system.