 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatureLM: Deciphering the Language of Nature for Scientific Discovery
Feb 11, 2025



Foundation models have revolutionized natural language processing and artificial intelligence, significantly enhancing how machines comprehend and generate human languages. Inspired by the success of these foundation models, researchers have developed foundation models for individual scientific domains, including small molecules, materials, proteins, DNA, and RNA. However, these models are typically trained in isolation, lacking the ability to integrate across different scientific domains. Recognizing that entities within these domains can all be represented as sequences, which together form the "language of nature", we introduce Nature Language Model (briefly, NatureLM), a sequence-based science foundation model designed for scientific discovery. Pre-trained with data from multiple scientific domains, NatureLM offers a unified, versatile model that enables various applications including: (i) generating and optimizing small molecules, proteins, RNA, and materials using text instructions; (ii) cross-domain generation/design, such as protein-to-molecule and protein-to-RNA generation; and (iii) achieving state-of-the-art performance in tasks like SMILES-to-IUPAC translation and retrosynthesis on USPTO-50k. NatureLM offers a promising generalist approach for various scientific tasks, including drug discovery (hit generation/optimization, ADMET optimization, synthesis), novel material design, and the development of therapeutic proteins or nucleotides. We have developed NatureLM models in different sizes (1 billion, 8 billion, and 46.7 billion parameters) and observed a clear improvement in performance as the model size increases.
Large Margin Prototypical Network for Few-shot Relation Classification with Fine-grained Features
Sep 06, 2024Relation classification (RC) plays a pivotal role in both natural language understanding and knowledge graph completion. It is generally formulated as a task to recognize the relationship between two entities of interest appearing in a free-text sentence. Conventional approaches on RC, regardless of feature engineering or deep learning based, can obtain promising performance on categorizing common types of relation leaving a large proportion of unrecognizable long-tail relations due to insufficient labeled instances for training. In this paper, we consider few-shot learning is of great practical significance to RC and thus improve a modern framework of metric learning for few-shot RC. Specifically, we adopt the large-margin ProtoNet with fine-grained features, expecting they can generalize well on long-tail relations. Extensive experiments were conducted by FewRel, a large-scale supervised few-shot RC dataset, to evaluate our framework: LM-ProtoNet (FGF). The results demonstrate that it can achieve substantial improvements over many baseline approaches.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
Towards Knowledge-driven Autonomous Driving
Dec 12, 2023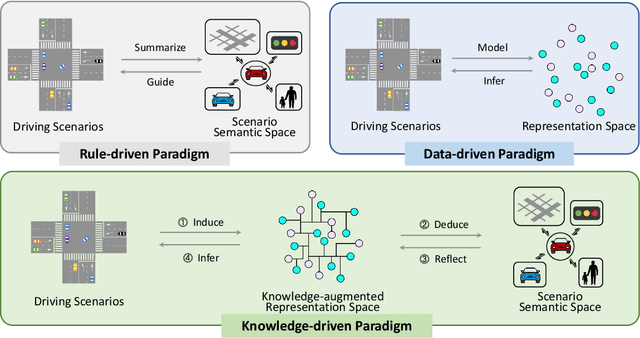
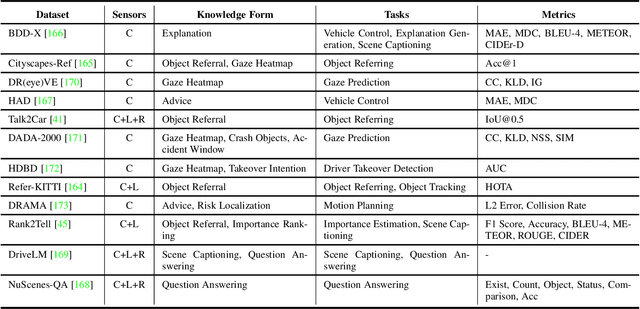
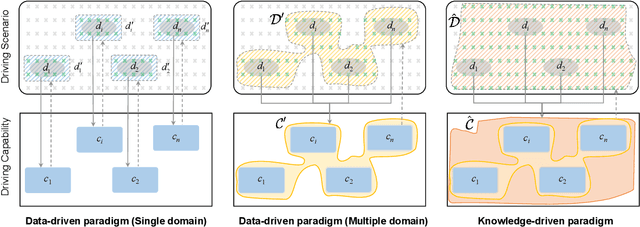
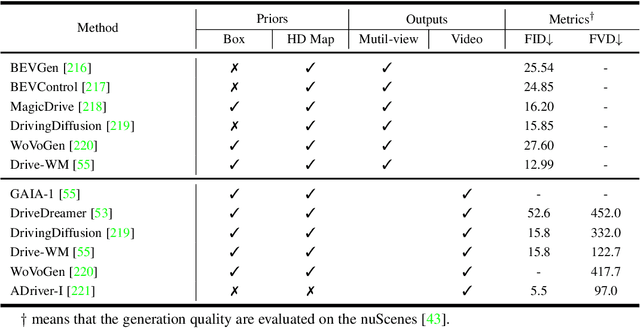
This paper explores the emerging knowledge-driven autonomous driving technologies. Our investigation highlights the limitations of current autonomous driving systems, in particular their sensitivity to data bias, difficulty in handling long-tail scenarios, and lack of interpretability. Conversely, knowledge-driven methods with the abilities of cognition, generalization and life-long learning emerge as a promising way to overcome these challenges. This paper delves into the essence of knowledge-driven autonomous driving and examines its core components: dataset \& benchmark, environment, and driver agent. By leveraging large language models, world models, neural rendering, and other advanced artificial intelligence techniques, these components collectively contribute to a more holistic, adaptive, and intelligent autonomous driving system. The paper systematically organizes and reviews previous research efforts in this area, and provides insights and guidance for future research and practical applications of autonomous driving. We will continually share the latest updates on cutting-edge developments in knowledge-driven autonomous driving along with the relevant valuable open-source resources at: \url{https://github.com/PJLab-ADG/awesome-knowledge-driven-AD}.
On the Road with GPT-4V: Early Explorations of Visual-Language Model on Autonomous Driving
Nov 28, 2023The pursuit of autonomous driving technology hinges on the sophisticated integration of perception, decision-making, and control systems. Traditional approaches, both data-driven and rule-based, have been hindered by their inability to grasp the nuance of complex driving environments and the intentions of other road users. This has been a significant bottleneck, particularly in the development of common sense reasoning and nuanced scene understanding necessary for safe and reliable autonomous driving. The advent of Visual Language Models (VLM) represents a novel frontier in realizing fully autonomous vehicle driving. This report provides an exhaustive evaluation of the latest state-of-the-art VLM, GPT-4V(ision), and its application in autonomous driving scenarios. We explore the model's abilities to understand and reason about driving scenes, make decisions, and ultimately act in the capacity of a driver. Our comprehensive tests span from basic scene recognition to complex causal reasoning and real-time decision-making under varying conditions. Our findings reveal that GPT-4V demonstrates superior performance in scene understanding and causal reasoning compared to existing autonomous systems. It showcases the potential to handle out-of-distribution scenarios, recognize intentions, and make informed decisions in real driving contexts. However, challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks. These limitations underscore the need for further research and development. Project is now available on GitHub for interested parties to access and utilize: \url{https://github.com/PJLab-ADG/GPT4V-AD-Exploration}
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase
Sep 11, 2023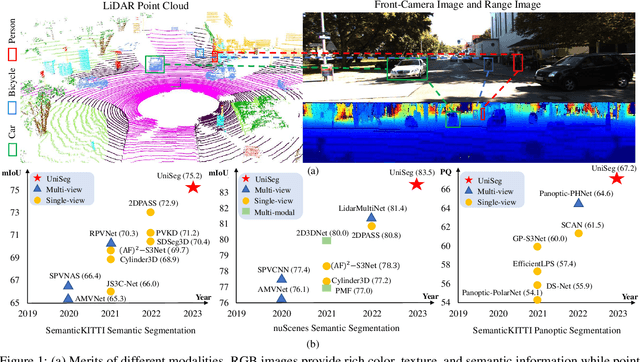

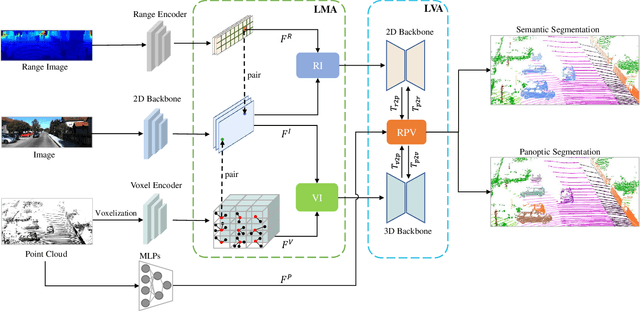
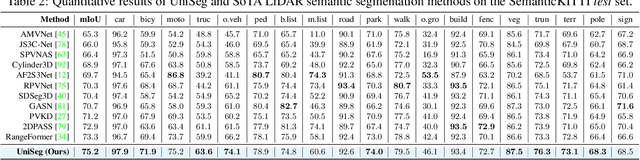
Point-, voxel-, and range-views are three representative forms of point clouds. All of them have accurate 3D measurements but lack color and texture information. RGB images are a natural complement to these point cloud views and fully utilizing the comprehensive information of them benefits more robust perceptions. In this paper, we present a unified multi-modal LiDAR segmentation network, termed UniSeg, which leverages the information of RGB images and three views of the point cloud, and accomplishes semantic segmentation and panoptic segmentation simultaneously. Specifically, we first design the Learnable cross-Modal Association (LMA) module to automatically fuse voxel-view and range-view features with image features, which fully utilize the rich semantic information of images and are robust to calibration errors. Then, the enhanced voxel-view and range-view features are transformed to the point space,where three views of point cloud features are further fused adaptively by the Learnable cross-View Association module (LVA). Notably, UniSeg achieves promising results in three public benchmarks, i.e., SemanticKITTI, nuScenes, and Waymo Open Dataset (WOD); it ranks 1st on two challenges of two benchmarks, including the LiDAR semantic segmentation challenge of nuScenes and panoptic segmentation challenges of SemanticKITTI. Besides, we construct the OpenPCSeg codebase, which is the largest and most comprehensive outdoor LiDAR segmentation codebase. It contains most of the popular outdoor LiDAR segmentation algorithms and provides reproducible implementations. The OpenPCSeg codebase will be made publicly available at https://github.com/PJLab-ADG/PCSeg.
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
Jun 08, 2023



We present a novel multi-view implicit surface reconstruction technique, termed StreetSurf, that is readily applicable to street view images in widely-used autonomous driving datasets, such as Waymo-perception sequences, without necessarily requiring LiDAR data. As neural rendering research expands rapidly, its integration into street views has started to draw interests. Existing approaches on street views either mainly focus on novel view synthesis with little exploration of the scene geometry, or rely heavily on dense LiDAR data when investigating reconstruction. Neither of them investigates multi-view implicit surface reconstruction, especially under settings without LiDAR data. Our method extends prior object-centric neural surface reconstruction techniques to address the unique challenges posed by the unbounded street views that are captured with non-object-centric, long and narrow camera trajectories. We delimit the unbounded space into three parts, close-range, distant-view and sky, with aligned cuboid boundaries, and adapt cuboid/hyper-cuboid hash-grids along with road-surface initialization scheme for finer and disentangled representation. To further address the geometric errors arising from textureless regions and insufficient viewing angles, we adopt geometric priors that are estimated using general purpose monocular models. Coupled with our implementation of efficient and fine-grained multi-stage ray marching strategy, we achieve state of the art reconstruction quality in both geometry and appearance within only one to two hours of training time with a single RTX3090 GPU for each street view sequence. Furthermore, we demonstrate that the reconstructed implicit surfaces have rich potential for various downstream tasks, including ray tracing and LiDAR simulation.
Speech Fusion to Face: Bridging the Gap Between Human's Vocal Characteristics and Facial Imaging
Jun 10, 2020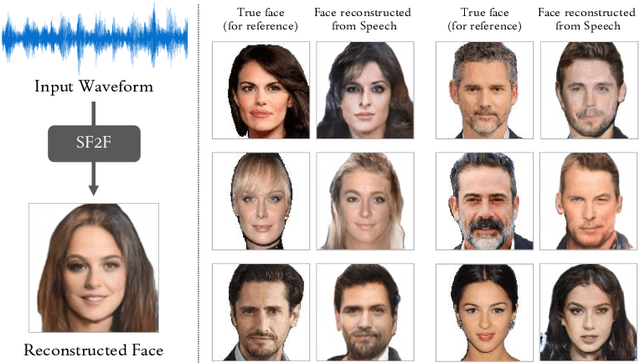
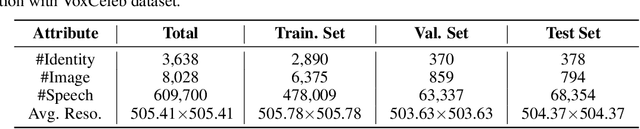
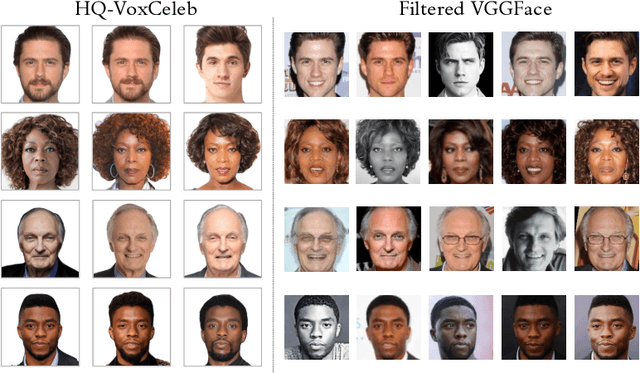

While deep learning technologies are now capable of generating realistic images confusing humans, the research efforts are turning to the synthesis of images for more concrete and application-specific purposes. Facial image generation based on vocal characteristics from speech is one of such important yet challenging tasks. It is the key enabler to influential use cases of image generation, especially for business in public security and entertainment. Existing solutions to the problem of speech2face renders limited image quality and fails to preserve facial similarity due to the lack of quality dataset for training and appropriate integration of vocal features. In this paper, we investigate these key technical challenges and propose Speech Fusion to Face, or SF2F in short, attempting to address the issue of facial image quality and the poor connection between vocal feature domain and modern image generation models. By adopting new strategies on data model and training, we demonstrate dramatic performance boost over state-of-the-art solution, by doubling the recall of individual identity, and lifting the quality score from 15 to 19 based on the mutual information score with VGGFace classifier.
PasteGAN: A Semi-Parametric Method to Generate Image from Scene Graph
May 05, 2019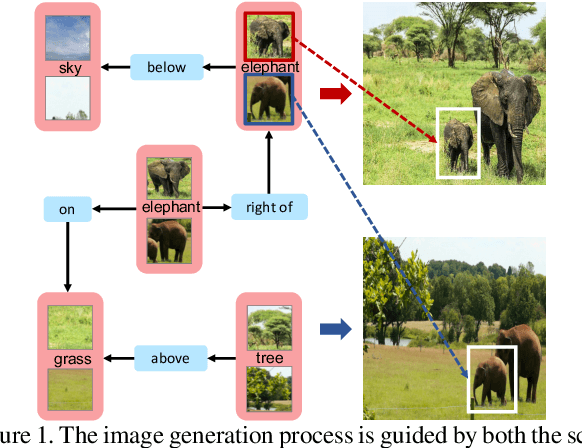
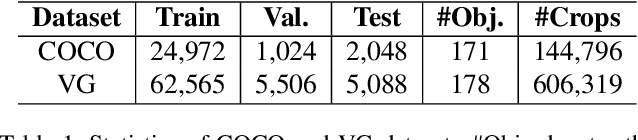
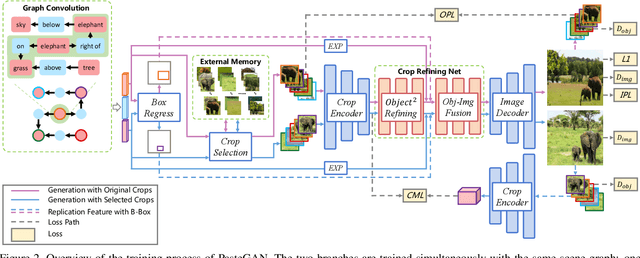
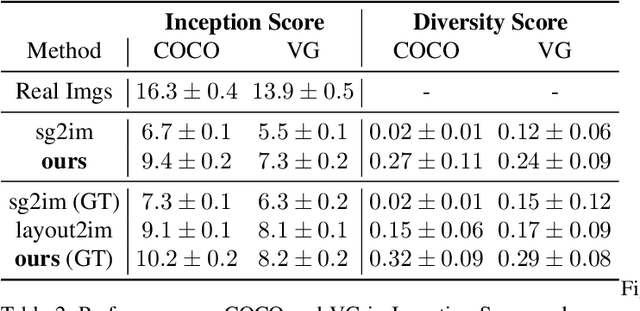
Despite some exciting progress on high-quality image generation from structured~(scene graphs) or free-form~(sentences) descriptions, most of them only guarantee the image-level semantical consistency, \ie the generated image matching the semantic meaning of the description. However, it still lacks the investigations on synthesizing the images in a more controllable way, like finely manipulating the visual appearance of every object. Therefore, to generate the images with preferred objects and rich interactions, we propose a semi-parametric method, denoted as PasteGAN, for generating the image from the scene graph, where spatial arrangements of the objects and their pair-wise relationships are defined by the scene graph and the object appearances are determined by given object crops. To enhance the interactions of the objects in the output, we design a Crop Refining Network to embed the objects as well as their relationships into one map. Multiple losses work collaboratively to guarantee the generated images highly respecting the crops and complying with the scene graphs while maintaining excellent image quality. A crop selector is also proposed to pick the most-compatible crops from our external object tank by encoding the interactions around the objects in the scene graph if the crops are not provided. Evaluated on Visual Genome and COCO-Stuff, our proposed method significantly outperforms the SOTA methods on both Inception Score and Diversity Score with a huge margin. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with given objects.