 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMoGen: Real-time Human Interaction-to-Reaction Generation via Modular Learning from Diverse Data
Apr 01, 2026Human behaviors in real-world environments are inherently interactive, with an individual's motion shaped by surrounding agents and the scene. Such capabilities are essential for applications in virtual avatars, interactive animation, and human-robot collaboration. We target real-time human interaction-to-reaction generation, which generates the ego's future motion from dynamic multi-source cues, including others' actions, scene geometry, and optional high-level semantic inputs. This task is fundamentally challenging due to (i) limited and fragmented interaction data distributed across heterogeneous single-person, human-human, and human-scene domains, and (ii) the need to produce low-latency yet high-fidelity motion responses during continuous online interaction. To address these challenges, we propose ReMoGen (Reaction Motion Generation), a modular learning framework for real-time interaction-to-reaction generation. ReMoGen leverages a universal motion prior learned from large-scale single-person motion datasets and adapts it to target interaction domains through independently trained Meta-Interaction modules, enabling robust generalization under data-scarce and heterogeneous supervision. To support responsive online interaction, ReMoGen performs segment-level generation together with a lightweight Frame-wise Segment Refinement module that incorporates newly observed cues at the frame level, improving both responsiveness and temporal coherence without expensive full-sequence inference. Extensive experiments across human-human, human-scene, and mixed-modality interaction settings show that ReMoGen produces high-quality, coherent, and responsive reactions, while generalizing effectively across diverse interaction scenarios.
STAGE: A Stream-Centric Generative World Model for Long-Horizon Driving-Scene Simulation
Jun 16, 2025The generation of temporally consistent, high-fidelity driving videos over extended horizons presents a fundamental challenge in autonomous driving world modeling. Existing approaches often suffer from error accumulation and feature misalignment due to inadequate decoupling of spatio-temporal dynamics and limited cross-frame feature propagation mechanisms. To address these limitations, we present STAGE (Streaming Temporal Attention Generative Engine), a novel auto-regressive framework that pioneers hierarchical feature coordination and multi-phase optimization for sustainable video synthesis. To achieve high-quality long-horizon driving video generation, we introduce Hierarchical Temporal Feature Transfer (HTFT) and a novel multi-stage training strategy. HTFT enhances temporal consistency between video frames throughout the video generation process by modeling the temporal and denoising process separately and transferring denoising features between frames. The multi-stage training strategy is to divide the training into three stages, through model decoupling and auto-regressive inference process simulation, thereby accelerating model convergence and reducing error accumulation. Experiments on the Nuscenes dataset show that STAGE has significantly surpassed existing methods in the long-horizon driving video generation task. In addition, we also explored STAGE's ability to generate unlimited-length driving videos. We generated 600 frames of high-quality driving videos on the Nuscenes dataset, which far exceeds the maximum length achievable by existing methods.
HUMOF: Human Motion Forecasting in Interactive Social Scenes
Jun 05, 2025Complex scenes present significant challenges for predicting human behaviour due to the abundance of interaction information, such as human-human and humanenvironment interactions. These factors complicate the analysis and understanding of human behaviour, thereby increasing the uncertainty in forecasting human motions. Existing motion prediction methods thus struggle in these complex scenarios. In this paper, we propose an effective method for human motion forecasting in interactive scenes. To achieve a comprehensive representation of interactions, we design a hierarchical interaction feature representation so that high-level features capture the overall context of the interactions, while low-level features focus on fine-grained details. Besides, we propose a coarse-to-fine interaction reasoning module that leverages both spatial and frequency perspectives to efficiently utilize hierarchical features, thereby enhancing the accuracy of motion predictions. Our method achieves state-of-the-art performance across four public datasets. Code will be released when this paper is published.
EvolvingGrasp: Evolutionary Grasp Generation via Efficient Preference Alignment
Mar 19, 2025



Dexterous robotic hands often struggle to generalize effectively in complex environments due to the limitations of models trained on low-diversity data. However, the real world presents an inherently unbounded range of scenarios, making it impractical to account for every possible variation. A natural solution is to enable robots learning from experience in complex environments, an approach akin to evolution, where systems improve through continuous feedback, learning from both failures and successes, and iterating toward optimal performance. Motivated by this, we propose EvolvingGrasp, an evolutionary grasp generation method that continuously enhances grasping performance through efficient preference alignment. Specifically, we introduce Handpose wise Preference Optimization (HPO), which allows the model to continuously align with preferences from both positive and negative feedback while progressively refining its grasping strategies. To further enhance efficiency and reliability during online adjustments, we incorporate a Physics-aware Consistency Model within HPO, which accelerates inference, reduces the number of timesteps needed for preference finetuning, and ensures physical plausibility throughout the process. Extensive experiments across four benchmark datasets demonstrate state of the art performance of our method in grasp success rate and sampling efficiency. Our results validate that EvolvingGrasp enables evolutionary grasp generation, ensuring robust, physically feasible, and preference-aligned grasping in both simulation and real scenarios.
FreeCap: Hybrid Calibration-Free Motion Capture in Open Environments
Nov 07, 2024
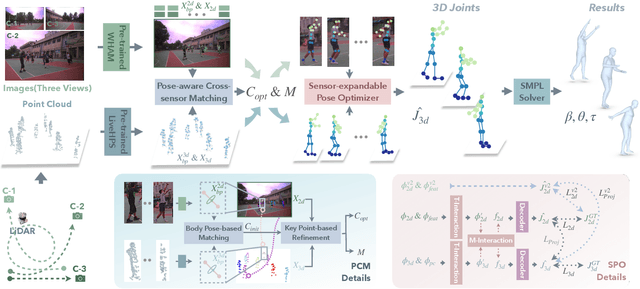
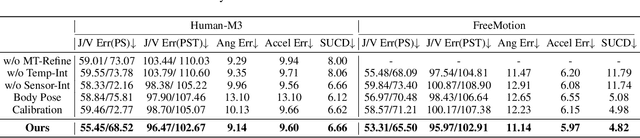

We propose a novel hybrid calibration-free method FreeCap to accurately capture global multi-person motions in open environments. Our system combines a single LiDAR with expandable moving cameras, allowing for flexible and precise motion estimation in a unified world coordinate. In particular, We introduce a local-to-global pose-aware cross-sensor human-matching module that predicts the alignment among each sensor, even in the absence of calibration. Additionally, our coarse-to-fine sensor-expandable pose optimizer further optimizes the 3D human key points and the alignments, it is also capable of incorporating additional cameras to enhance accuracy. Extensive experiments on Human-M3 and FreeMotion datasets demonstrate that our method significantly outperforms state-of-the-art single-modal methods, offering an expandable and efficient solution for multi-person motion capture across various applications.
Registration between Point Cloud Streams and Sequential Bounding Boxes via Gradient Descent
Sep 14, 2024In this paper, we propose an algorithm for registering sequential bounding boxes with point cloud streams. Unlike popular point cloud registration techniques, the alignment of the point cloud and the bounding box can rely on the properties of the bounding box, such as size, shape, and temporal information, which provides substantial support and performance gains. Motivated by this, we propose a new approach to tackle this problem. Specifically, we model the registration process through an overall objective function that includes the final goal and all constraints. We then optimize the function using gradient descent. Our experiments show that the proposed method performs remarkably well with a 40\% improvement in IoU and demonstrates more robust registration between point cloud streams and sequential bounding boxes
Can LVLMs Obtain a Driver's License? A Benchmark Towards Reliable AGI for Autonomous Driving
Sep 04, 2024Large Vision-Language Models (LVLMs) have recently garnered significant attention, with many efforts aimed at harnessing their general knowledge to enhance the interpretability and robustness of autonomous driving models. However, LVLMs typically rely on large, general-purpose datasets and lack the specialized expertise required for professional and safe driving. Existing vision-language driving datasets focus primarily on scene understanding and decision-making, without providing explicit guidance on traffic rules and driving skills, which are critical aspects directly related to driving safety. To bridge this gap, we propose IDKB, a large-scale dataset containing over one million data items collected from various countries, including driving handbooks, theory test data, and simulated road test data. Much like the process of obtaining a driver's license, IDKB encompasses nearly all the explicit knowledge needed for driving from theory to practice. In particular, we conducted comprehensive tests on 15 LVLMs using IDKB to assess their reliability in the context of autonomous driving and provided extensive analysis. We also fine-tuned popular models, achieving notable performance improvements, which further validate the significance of our dataset. The project page can be found at: \url{https://4dvlab.github.io/project_page/idkb.html}
MCPDepth: Omnidirectional Depth Estimation via Stereo Matching from Multi-Cylindrical Panoramas
Aug 03, 2024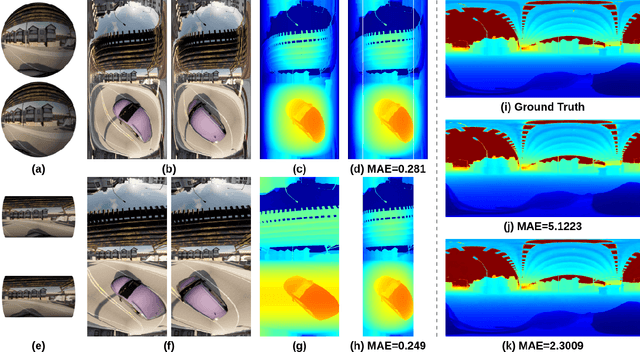
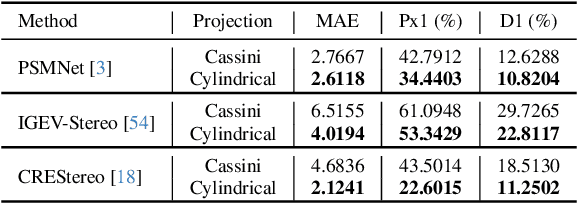
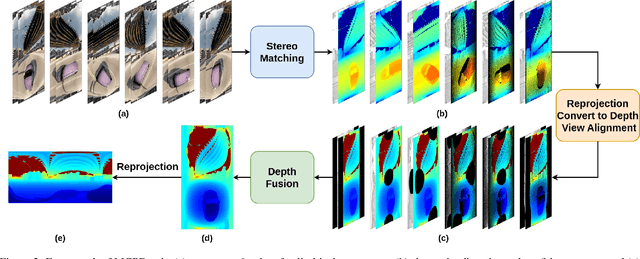
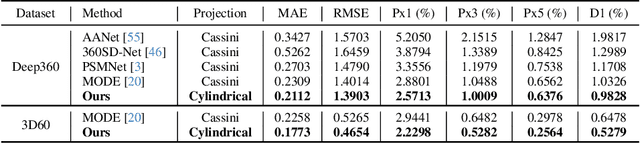
We introduce Multi-Cylindrical Panoramic Depth Estimation (MCPDepth), a two-stage framework for omnidirectional depth estimation via stereo matching between multiple cylindrical panoramas. MCPDepth uses cylindrical panoramas for initial stereo matching and then fuses the resulting depth maps across views. A circular attention module is employed to overcome the distortion along the vertical axis. MCPDepth exclusively utilizes standard network components, simplifying deployment to embedded devices and outperforming previous methods that require custom kernels. We theoretically and experimentally compare spherical and cylindrical projections for stereo matching, highlighting the advantages of the cylindrical projection. MCPDepth achieves state-of-the-art performance with an 18.8% reduction in mean absolute error (MAE) for depth on the outdoor synthetic dataset Deep360 and a 19.9% reduction on the indoor real-scene dataset 3D60.
TASeg: Temporal Aggregation Network for LiDAR Semantic Segmentation
Jul 13, 2024



Training deep models for LiDAR semantic segmentation is challenging due to the inherent sparsity of point clouds. Utilizing temporal data is a natural remedy against the sparsity problem as it makes the input signal denser. However, previous multi-frame fusion algorithms fall short in utilizing sufficient temporal information due to the memory constraint, and they also ignore the informative temporal images. To fully exploit rich information hidden in long-term temporal point clouds and images, we present the Temporal Aggregation Network, termed TASeg. Specifically, we propose a Temporal LiDAR Aggregation and Distillation (TLAD) algorithm, which leverages historical priors to assign different aggregation steps for different classes. It can largely reduce memory and time overhead while achieving higher accuracy. Besides, TLAD trains a teacher injected with gt priors to distill the model, further boosting the performance. To make full use of temporal images, we design a Temporal Image Aggregation and Fusion (TIAF) module, which can greatly expand the camera FOV and enhance the present features. Temporal LiDAR points in the camera FOV are used as mediums to transform temporal image features to the present coordinate for temporal multi-modal fusion. Moreover, we develop a Static-Moving Switch Augmentation (SMSA) algorithm, which utilizes sufficient temporal information to enable objects to switch their motion states freely, thus greatly increasing static and moving training samples. Our TASeg ranks 1st on three challenging tracks, i.e., SemanticKITTI single-scan track, multi-scan track and nuScenes LiDAR segmentation track, strongly demonstrating the superiority of our method. Codes are available at https://github.com/LittlePey/TASeg.
A Unified Framework for Human-centric Point Cloud Video Understanding
Mar 29, 2024Human-centric Point Cloud Video Understanding (PVU) is an emerging field focused on extracting and interpreting human-related features from sequences of human point clouds, further advancing downstream human-centric tasks and applications. Previous works usually focus on tackling one specific task and rely on huge labeled data, which has poor generalization capability. Considering that human has specific characteristics, including the structural semantics of human body and the dynamics of human motions, we propose a unified framework to make full use of the prior knowledge and explore the inherent features in the data itself for generalized human-centric point cloud video understanding. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various human-related tasks, including action recognition and 3D pose estimation. All datasets and code will be released soon.