 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecouple Searching from Training: Scaling Data Mixing via Model Merging for Large Language Model Pre-training
Jan 31, 2026Determining an effective data mixture is a key factor in Large Language Model (LLM) pre-training, where models must balance general competence with proficiency on hard tasks such as math and code. However, identifying an optimal mixture remains an open challenge, as existing approaches either rely on unreliable tiny-scale proxy experiments or require prohibitively expensive large-scale exploration. To address this, we propose Decouple Searching from Training Mix (DeMix), a novel framework that leverages model merging to predict optimal data ratios. Instead of training proxy models for every sampled mixture, DeMix trains component models on candidate datasets at scale and derives data mixture proxies via weighted model merging. This paradigm decouples search from training costs, enabling evaluation of unlimited sampled mixtures without extra training burden and thus facilitating better mixture discovery through more search trials. Extensive experiments demonstrate that DeMix breaks the trade-off between sufficiency, accuracy and efficiency, obtaining the optimal mixture with higher benchmark performance at lower search cost. Additionally, we release the DeMix Corpora, a comprehensive 22T-token dataset comprising high-quality pre-training data with validated mixtures to facilitate open research. Our code and DeMix Corpora is available at https://github.com/Lucius-lsr/DeMix.
One Token Is Enough: Improving Diffusion Language Models with a Sink Token
Jan 27, 2026Diffusion Language Models (DLMs) have emerged as a compelling alternative to autoregressive approaches, enabling parallel text generation with competitive performance. Despite these advantages, there is a critical instability in DLMs: the moving sink phenomenon. Our analysis indicates that sink tokens exhibit low-norm representations in the Transformer's value space, and that the moving sink phenomenon serves as a protective mechanism in DLMs to prevent excessive information mixing. However, their unpredictable positions across diffusion steps undermine inference robustness. To resolve this, we propose a simple but effective extra sink token implemented via a modified attention mask. Specifically, we introduce a special token constrained to attend solely to itself, while remaining globally visible to all other tokens. Experimental results demonstrate that introducing a single extra token stabilizes attention sinks, substantially improving model performance. Crucially, further analysis confirms that the effectiveness of this token is independent of its position and characterized by negligible semantic content, validating its role as a robust and dedicated structural sink.
Vclip: Face-based Speaker Generation by Face-voice Association Learning
Jan 06, 2026This paper discusses the task of face-based speech synthesis, a kind of personalized speech synthesis where the synthesized voices are constrained to perceptually match with a reference face image. Due to the lack of TTS-quality audio-visual corpora, previous approaches suffer from either low synthesis quality or domain mismatch induced by a knowledge transfer scheme. This paper proposes a new approach called Vclip that utilizes the facial-semantic knowledge of the CLIP encoder on noisy audio-visual data to learn the association between face and voice efficiently, achieving 89.63% cross-modal verification AUC score on Voxceleb testset. The proposed method then uses a retrieval-based strategy, combined with GMM-based speaker generation module for a downstream TTS system, to produce probable target speakers given reference images. Experimental results demonstrate that the proposed Vclip system in conjunction with the retrieval step can bridge the gap between face and voice features for face-based speech synthesis. And using the feedback information distilled from downstream TTS helps to synthesize voices that match closely with reference faces. Demos available at sos1sos2sixteen.github.io/vclip.
CommonVoice-SpeechRE and RPG-MoGe: Advancing Speech Relation Extraction with a New Dataset and Multi-Order Generative Framework
Sep 10, 2025Speech Relation Extraction (SpeechRE) aims to extract relation triplets directly from speech. However, existing benchmark datasets rely heavily on synthetic data, lacking sufficient quantity and diversity of real human speech. Moreover, existing models also suffer from rigid single-order generation templates and weak semantic alignment, substantially limiting their performance. To address these challenges, we introduce CommonVoice-SpeechRE, a large-scale dataset comprising nearly 20,000 real-human speech samples from diverse speakers, establishing a new benchmark for SpeechRE research. Furthermore, we propose the Relation Prompt-Guided Multi-Order Generative Ensemble (RPG-MoGe), a novel framework that features: (1) a multi-order triplet generation ensemble strategy, leveraging data diversity through diverse element orders during both training and inference, and (2) CNN-based latent relation prediction heads that generate explicit relation prompts to guide cross-modal alignment and accurate triplet generation. Experiments show our approach outperforms state-of-the-art methods, providing both a benchmark dataset and an effective solution for real-world SpeechRE. The source code and dataset are publicly available at https://github.com/NingJinzhong/SpeechRE_RPG_MoGe.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
Depth Any Video with Scalable Synthetic Data
Oct 14, 2024



Video depth estimation has long been hindered by the scarcity of consistent and scalable ground truth data, leading to inconsistent and unreliable results. In this paper, we introduce Depth Any Video, a model that tackles the challenge through two key innovations. First, we develop a scalable synthetic data pipeline, capturing real-time video depth data from diverse synthetic environments, yielding 40,000 video clips of 5-second duration, each with precise depth annotations. Second, we leverage the powerful priors of generative video diffusion models to handle real-world videos effectively, integrating advanced techniques such as rotary position encoding and flow matching to further enhance flexibility and efficiency. Unlike previous models, which are limited to fixed-length video sequences, our approach introduces a novel mixed-duration training strategy that handles videos of varying lengths and performs robustly across different frame rates-even on single frames. At inference, we propose a depth interpolation method that enables our model to infer high-resolution video depth across sequences of up to 150 frames. Our model outperforms all previous generative depth models in terms of spatial accuracy and temporal consistency.
A Dual-Path Framework with Frequency-and-Time Excited Network for Anomalous Sound Detection
Sep 05, 2024



In contrast to human speech, machine-generated sounds of the same type often exhibit consistent frequency characteristics and discernible temporal periodicity. However, leveraging these dual attributes in anomaly detection remains relatively under-explored. In this paper, we propose an automated dual-path framework that learns prominent frequency and temporal patterns for diverse machine types. One pathway uses a novel Frequency-and-Time Excited Network (FTE-Net) to learn the salient features across frequency and time axes of the spectrogram. It incorporates a Frequency-and-Time Chunkwise Encoder (FTC-Encoder) and an excitation network. The other pathway uses a 1D convolutional network for utterance-level spectrum. Experimental results on the DCASE 2023 task 2 dataset show the state-of-the-art performance of our proposed method. Moreover, visualizations of the intermediate feature maps in the excitation network are provided to illustrate the effectiveness of our method.
Rethinking Visual Content Refinement in Low-Shot CLIP Adaptation
Jul 19, 2024

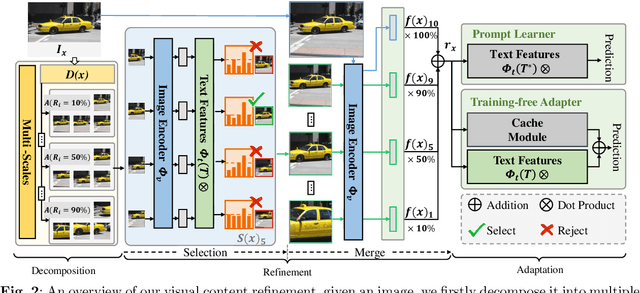

Recent adaptations can boost the low-shot capability of Contrastive Vision-Language Pre-training (CLIP) by effectively facilitating knowledge transfer. However, these adaptation methods are usually operated on the global view of an input image, and thus biased perception of partial local details of the image. To solve this problem, we propose a Visual Content Refinement (VCR) before the adaptation calculation during the test stage. Specifically, we first decompose the test image into different scales to shift the feature extractor's attention to the details of the image. Then, we select the image view with the max prediction margin in each scale to filter out the noisy image views, where the prediction margins are calculated from the pre-trained CLIP model. Finally, we merge the content of the aforementioned selected image views based on their scales to construct a new robust representation. Thus, the merged content can be directly used to help the adapter focus on both global and local parts without any extra training parameters. We apply our method to 3 popular low-shot benchmark tasks with 13 datasets and achieve a significant improvement over state-of-the-art methods. For example, compared to the baseline (Tip-Adapter) on the few-shot classification task, our method achieves about 2\% average improvement for both training-free and training-need settings.
TASeg: Temporal Aggregation Network for LiDAR Semantic Segmentation
Jul 13, 2024



Training deep models for LiDAR semantic segmentation is challenging due to the inherent sparsity of point clouds. Utilizing temporal data is a natural remedy against the sparsity problem as it makes the input signal denser. However, previous multi-frame fusion algorithms fall short in utilizing sufficient temporal information due to the memory constraint, and they also ignore the informative temporal images. To fully exploit rich information hidden in long-term temporal point clouds and images, we present the Temporal Aggregation Network, termed TASeg. Specifically, we propose a Temporal LiDAR Aggregation and Distillation (TLAD) algorithm, which leverages historical priors to assign different aggregation steps for different classes. It can largely reduce memory and time overhead while achieving higher accuracy. Besides, TLAD trains a teacher injected with gt priors to distill the model, further boosting the performance. To make full use of temporal images, we design a Temporal Image Aggregation and Fusion (TIAF) module, which can greatly expand the camera FOV and enhance the present features. Temporal LiDAR points in the camera FOV are used as mediums to transform temporal image features to the present coordinate for temporal multi-modal fusion. Moreover, we develop a Static-Moving Switch Augmentation (SMSA) algorithm, which utilizes sufficient temporal information to enable objects to switch their motion states freely, thus greatly increasing static and moving training samples. Our TASeg ranks 1st on three challenging tracks, i.e., SemanticKITTI single-scan track, multi-scan track and nuScenes LiDAR segmentation track, strongly demonstrating the superiority of our method. Codes are available at https://github.com/LittlePey/TASeg.
Boosting Few-Shot Learning via Attentive Feature Regularization
Mar 23, 2024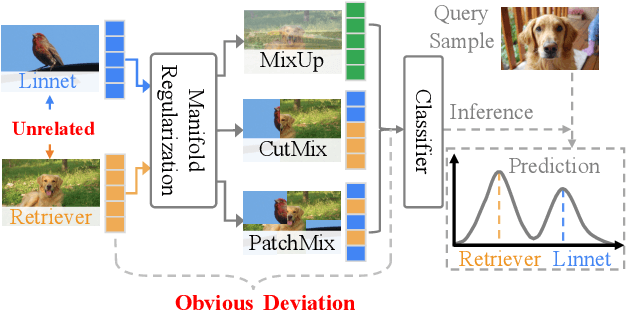
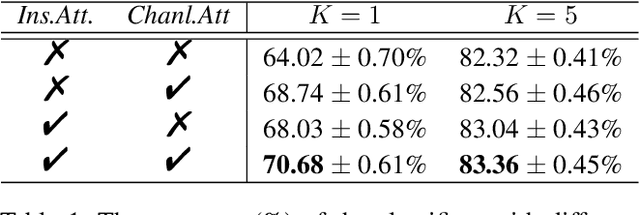
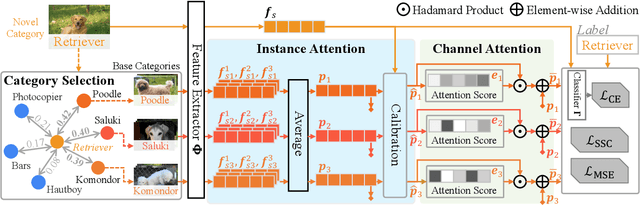
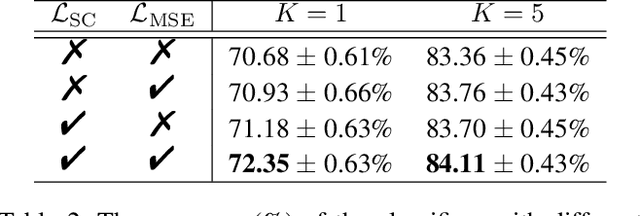
Few-shot learning (FSL) based on manifold regularization aims to improve the recognition capacity of novel objects with limited training samples by mixing two samples from different categories with a blending factor. However, this mixing operation weakens the feature representation due to the linear interpolation and the overlooking of the importance of specific channels. To solve these issues, this paper proposes attentive feature regularization (AFR) which aims to improve the feature representativeness and discriminability. In our approach, we first calculate the relations between different categories of semantic labels to pick out the related features used for regularization. Then, we design two attention-based calculations at both the instance and channel levels. These calculations enable the regularization procedure to focus on two crucial aspects: the feature complementarity through adaptive interpolation in related categories and the emphasis on specific feature channels. Finally, we combine these regularization strategies to significantly improve the classifier performance. Empirical studies on several popular FSL benchmarks demonstrate the effectiveness of AFR, which improves the recognition accuracy of novel categories without the need to retrain any feature extractor, especially in the 1-shot setting. Furthermore, the proposed AFR can seamlessly integrate into other FSL methods to improve classification performance.