 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
Thinking in Dynamics: How Multimodal Large Language Models Perceive, Track, and Reason Dynamics in Physical 4D World
Mar 13, 2026Humans inhabit a physical 4D world where geometric structure and semantic content evolve over time, constituting a dynamic 4D reality (spatial with temporal dimension). While current Multimodal Large Language Models (MLLMs) excel in static visual understanding, can they also be adept at "thinking in dynamics", i.e., perceive, track and reason about spatio-temporal dynamics in evolving scenes? To systematically assess their spatio-temporal reasoning and localized dynamics perception capabilities, we introduce Dyn-Bench, a large-scale benchmark built from diverse real-world and synthetic video datasets, enabling robust and scalable evaluation of spatio-temporal understanding. Through multi-stage filtering from massive 2D and 4D data sources, Dyn-Bench provides a high-quality collection of dynamic scenes, comprising 1k videos, 7k visual question answering (VQA) pairs, and 3k dynamic object grounding pairs. We probe general, spatial and region-level MLLMs to express how they think in dynamics both linguistically and visually, and find that existing models cannot simultaneously maintain strong performance in both spatio-temporal reasoning and dynamic object grounding, often producing inconsistent interpretations of motion and interaction. Notably, conventional prompting strategies (e.g., chain-of-thought or caption-based hints) provide limited improvement, whereas structured integration approaches, including Mask-Guided Fusion and Spatio-Temporal Textual Cognitive Map (ST-TCM), significantly enhance MLLMs' dynamics perception and spatio-temporal reasoning in the physical 4D world. Code and benchmark are available at https://dyn-bench.github.io/.
SwiftVLM: Efficient Vision-Language Model Inference via Cross-Layer Token Bypass
Feb 03, 2026Visual token pruning is a promising approach for reducing the computational cost of vision-language models (VLMs), and existing methods often rely on early pruning decisions to improve efficiency. While effective on coarse-grained reasoning tasks, they suffer from significant performance degradation on tasks requiring fine-grained visual details. Through layer-wise analysis, we reveal substantial discrepancies in visual token importance across layers, showing that tokens deemed unimportant at shallow layers can later become highly relevant for text-conditioned reasoning. To avoid irreversible critical information loss caused by premature pruning, we introduce a new pruning paradigm, termed bypass, which preserves unselected visual tokens and forwards them to subsequent pruning stages for re-evaluation. Building on this paradigm, we propose SwiftVLM, a simple and training-free method that performs pruning at model-specific layers with strong visual token selection capability, while enabling independent pruning decisions across layers. Experiments across multiple VLMs and benchmarks demonstrate that SwiftVLM consistently outperforms existing pruning strategies, achieving superior accuracy-efficiency trade-offs and more faithful visual token selection behavior.
HEAPr: Hessian-based Efficient Atomic Expert Pruning in Output Space
Sep 26, 2025Mixture-of-Experts (MoE) architectures in large language models (LLMs) deliver exceptional performance and reduced inference costs compared to dense LLMs. However, their large parameter counts result in prohibitive memory requirements, limiting practical deployment. While existing pruning methods primarily focus on expert-level pruning, this coarse granularity often leads to substantial accuracy degradation. In this work, we introduce HEAPr, a novel pruning algorithm that decomposes experts into smaller, indivisible atomic experts, enabling more precise and flexible atomic expert pruning. To measure the importance of each atomic expert, we leverage second-order information based on principles similar to Optimal Brain Surgeon (OBS) theory. To address the computational and storage challenges posed by second-order information, HEAPr exploits the inherent properties of atomic experts to transform the second-order information from expert parameters into that of atomic expert parameters, and further simplifies it to the second-order information of atomic expert outputs. This approach reduces the space complexity from $O(d^4)$, where d is the model's dimensionality, to $O(d^2)$. HEAPr requires only two forward passes and one backward pass on a small calibration set to compute the importance of atomic experts. Extensive experiments on MoE models, including DeepSeek MoE and Qwen MoE family, demonstrate that HEAPr outperforms existing expert-level pruning methods across a wide range of compression ratios and benchmarks. Specifically, HEAPr achieves nearly lossless compression at compression ratios of 20% ~ 25% in most models, while also reducing FLOPs nearly by 20%. The code can be found at \href{https://github.com/LLIKKE/HEAPr}{https://github.com/LLIKKE/HEAPr}.
Generative AI Meets Wireless Sensing: Towards Wireless Foundation Model
Sep 18, 2025



Generative Artificial Intelligence (GenAI) has made significant advancements in fields such as computer vision (CV) and natural language processing (NLP), demonstrating its capability to synthesize high-fidelity data and improve generalization. Recently, there has been growing interest in integrating GenAI into wireless sensing systems. By leveraging generative techniques such as data augmentation, domain adaptation, and denoising, wireless sensing applications, including device localization, human activity recognition, and environmental monitoring, can be significantly improved. This survey investigates the convergence of GenAI and wireless sensing from two complementary perspectives. First, we explore how GenAI can be integrated into wireless sensing pipelines, focusing on two modes of integration: as a plugin to augment task-specific models and as a solver to directly address sensing tasks. Second, we analyze the characteristics of mainstream generative models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models, and discuss their applicability and unique advantages across various wireless sensing tasks. We further identify key challenges in applying GenAI to wireless sensing and outline a future direction toward a wireless foundation model: a unified, pre-trained design capable of scalable, adaptable, and efficient signal understanding across diverse sensing tasks.
Symmetry Interactive Transformer with CNN Framework for Diagnosis of Alzheimer's Disease Using Structural MRI
Sep 10, 2025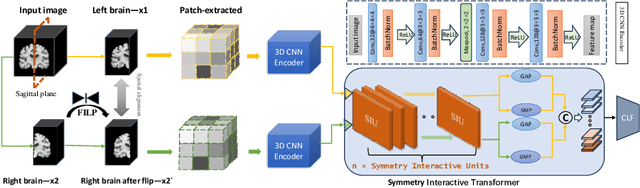
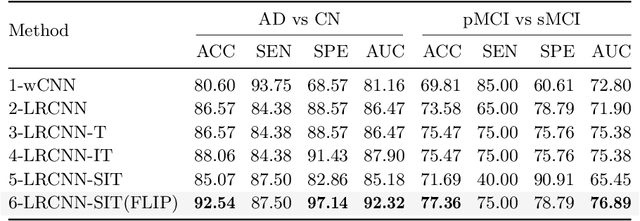
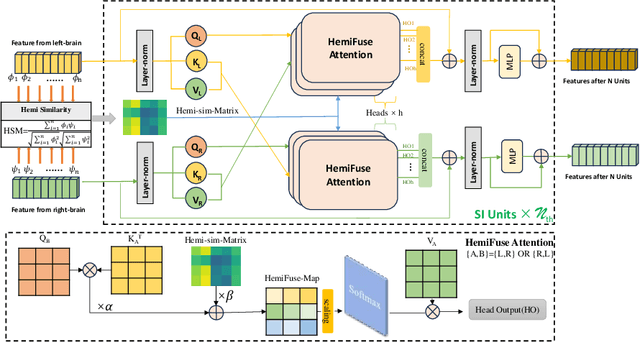
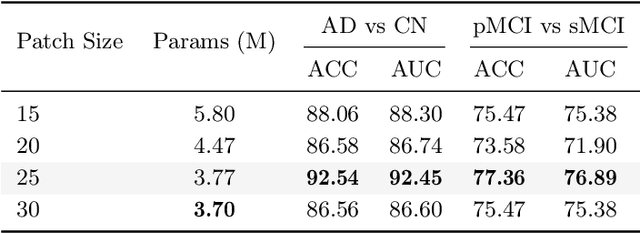
Structural magnetic resonance imaging (sMRI) combined with deep learning has achieved remarkable progress in the prediction and diagnosis of Alzheimer's disease (AD). Existing studies have used CNN and transformer to build a well-performing network, but most of them are based on pretraining or ignoring the asymmetrical character caused by brain disorders. We propose an end-to-end network for the detection of disease-based asymmetric induced by left and right brain atrophy which consist of 3D CNN Encoder and Symmetry Interactive Transformer (SIT). Following the inter-equal grid block fetch operation, the corresponding left and right hemisphere features are aligned and subsequently fed into the SIT for diagnostic analysis. SIT can help the model focus more on the regions of asymmetry caused by structural changes, thus improving diagnostic performance. We evaluated our method based on the ADNI dataset, and the results show that the method achieves better diagnostic accuracy (92.5\%) compared to several CNN methods and CNNs combined with a general transformer. The visualization results show that our network pays more attention in regions of brain atrophy, especially for the asymmetric pathological characteristics induced by AD, demonstrating the interpretability and effectiveness of the method.
OpenMoCap: Rethinking Optical Motion Capture under Real-world Occlusion
Aug 18, 2025Optical motion capture is a foundational technology driving advancements in cutting-edge fields such as virtual reality and film production. However, system performance suffers severely under large-scale marker occlusions common in real-world applications. An in-depth analysis identifies two primary limitations of current models: (i) the lack of training datasets accurately reflecting realistic marker occlusion patterns, and (ii) the absence of training strategies designed to capture long-range dependencies among markers. To tackle these challenges, we introduce the CMU-Occlu dataset, which incorporates ray tracing techniques to realistically simulate practical marker occlusion patterns. Furthermore, we propose OpenMoCap, a novel motion-solving model designed specifically for robust motion capture in environments with significant occlusions. Leveraging a marker-joint chain inference mechanism, OpenMoCap enables simultaneous optimization and construction of deep constraints between markers and joints. Extensive comparative experiments demonstrate that OpenMoCap consistently outperforms competing methods across diverse scenarios, while the CMU-Occlu dataset opens the door for future studies in robust motion solving. The proposed OpenMoCap is integrated into the MoSen MoCap system for practical deployment. The code is released at: https://github.com/qianchen214/OpenMoCap.
SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer
Aug 18, 2025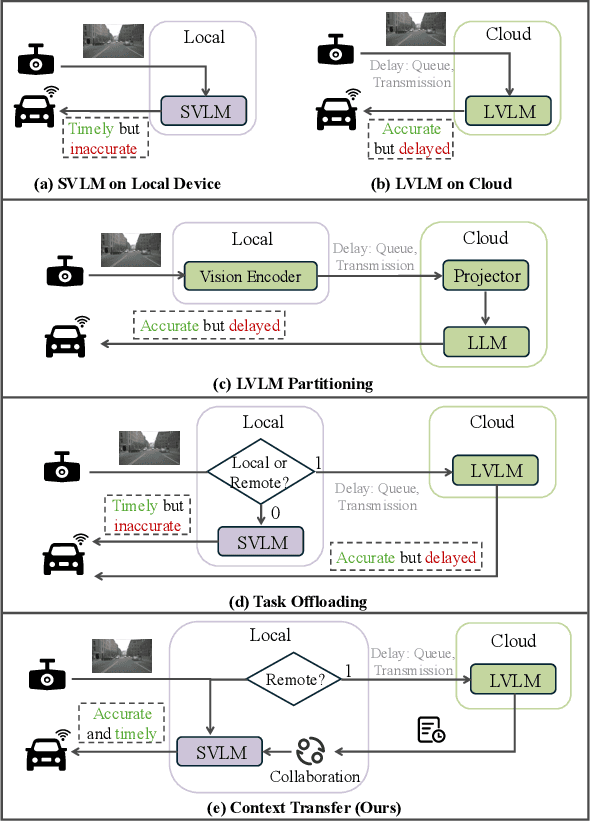
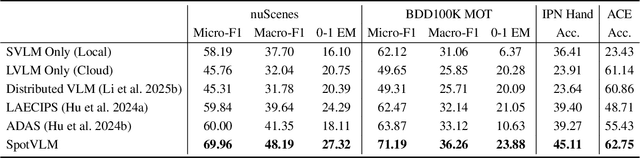
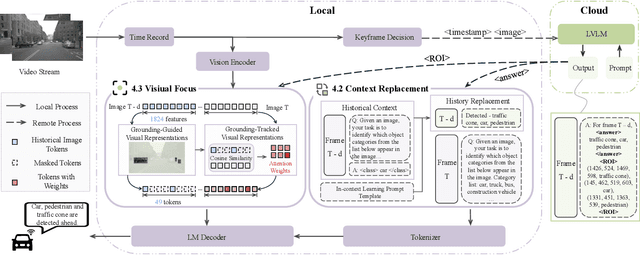
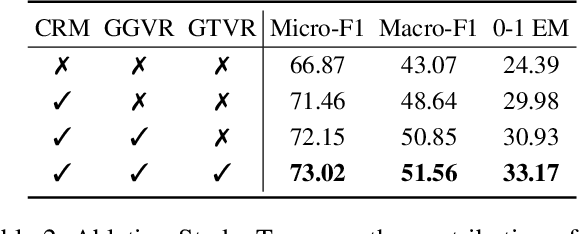
Vision-Language Models (VLMs) are increasingly deployed in real-time applications such as autonomous driving and human-computer interaction, which demand fast and reliable responses based on accurate perception. To meet these requirements, existing systems commonly employ cloud-edge collaborative architectures, such as partitioned Large Vision-Language Models (LVLMs) or task offloading strategies between Large and Small Vision-Language Models (SVLMs). However, these methods fail to accommodate cloud latency fluctuations and overlook the full potential of delayed but accurate LVLM responses. In this work, we propose a novel cloud-edge collaborative paradigm for VLMs, termed Context Transfer, which treats the delayed outputs of LVLMs as historical context to provide real-time guidance for SVLMs inference. Based on this paradigm, we design SpotVLM, which incorporates both context replacement and visual focus modules to refine historical textual input and enhance visual grounding consistency. Extensive experiments on three real-time vision tasks across four datasets demonstrate the effectiveness of the proposed framework. The new paradigm lays the groundwork for more effective and latency-aware collaboration strategies in future VLM systems.
SpecOffload: Unlocking Latent GPU Capacity for LLM Inference on Resource-Constrained Devices
May 15, 2025Efficient LLM inference on resource-constrained devices presents significant challenges in compute and memory utilization. Due to limited GPU memory, existing systems offload model weights to CPU memory, incurring substantial I/O overhead between the CPU and GPU. This leads to two major inefficiencies: (1) GPU cores are underutilized, often remaining idle while waiting for data to be loaded; and (2) GPU memory has low impact on performance, as reducing its capacity has minimal effect on overall throughput.In this paper, we propose SpecOffload, a high-throughput inference engine that embeds speculative decoding into offloading. Our key idea is to unlock latent GPU resources for storing and executing a draft model used for speculative decoding, thus accelerating inference at near-zero additional cost. To support this, we carefully orchestrate the interleaved execution of target and draft models in speculative decoding within the offloading pipeline, and propose a planner to manage tensor placement and select optimal parameters. Compared to the best baseline, SpecOffload improves GPU core utilization by 4.49x and boosts inference throughput by 2.54x. Our code is available at https://github.com/MobiSense/SpecOffload .
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.