 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoQuant: Shaping Activation Distributions for Low-Bit LLM Quantization
May 25, 2026Low-bit activation quantization remains a major bottleneck in efficient large language model (LLM) deployment. The difficulty is not only that activations contain outliers, but that their distributions are often poorly matched to a low-bit uniform quantizer. Existing post-training quantization (PTQ) methods suppress peaks, balance channels, or minimize reconstruction error, yet they rarely specify what activation distribution is actually easy to discretize. As a result, activations may appear numerically smoother while still incurring large quantization error because the quantization range remains wide or most values collapse into a few levels near the mean. We recast activation transformation as quantizer-facing distribution design and analyze quantization error from an information-theoretic perspective. Our analysis shows that quantization-friendly activations should jointly have a smaller numerical range and sufficient dispersion within that range. Guided by this analysis, we propose InfoQuant, a train-free method that employs Peak Suppression Orthogonal Transformation (PSOT) to shape activations into more quantization-friendly distributions. We further introduce adaptive outlier-token selection to improve the robustness of PSOT during optimization. Across multiple LLM families, InfoQuant consistently outperforms prior PTQ and end-to-end training baselines. Under W4A4KV4, it preserves 97% of floating-point accuracy on average and reduces the LLaMA-2 13B performance gap by 42% over the previous state of the art. Code is available at [https://github.com/LLIKKE/InfoQuant](https://github.com/LLIKKE/InfoQuant)
HeteroCache: A Dynamic Retrieval Approach to Heterogeneous KV Cache Compression for Long-Context LLM Inference
Jan 20, 2026The linear memory growth of the KV cache poses a significant bottleneck for LLM inference in long-context tasks. Existing static compression methods often fail to preserve globally important information, principally because they overlook the attention drift phenomenon where token significance evolves dynamically. Although recent dynamic retrieval approaches attempt to address this issue, they typically suffer from coarse-grained caching strategies and incur high I/O overhead due to frequent data transfers. To overcome these limitations, we propose HeteroCache, a training-free dynamic compression framework. Our method is built on two key insights: attention heads exhibit diverse temporal heterogeneity, and there is significant spatial redundancy among heads within the same layer. Guided by these insights, HeteroCache categorizes heads based on stability and redundancy. Consequently, we apply a fine-grained weighting strategy that allocates larger cache budgets to heads with rapidly shifting attention to capture context changes, thereby addressing the inefficiency of coarse-grained strategies. Furthermore, we employ a hierarchical storage mechanism in which a subset of representative heads monitors attention shift, and trigger an asynchronous, on-demand retrieval of contexts from the CPU, effectively hiding I/O latency. Finally, experiments demonstrate that HeteroCache achieves state-of-the-art performance on multiple long-context benchmarks and accelerates decoding by up to $3\times$ compared to the original model in the 224K context. Our code will be open-source.
Dual-level Fuzzy Learning with Patch Guidance for Image Ordinal Regression
May 09, 2025Ordinal regression bridges regression and classification by assigning objects to ordered classes. While human experts rely on discriminative patch-level features for decisions, current approaches are limited by the availability of only image-level ordinal labels, overlooking fine-grained patch-level characteristics. In this paper, we propose a Dual-level Fuzzy Learning with Patch Guidance framework, named DFPG that learns precise feature-based grading boundaries from ambiguous ordinal labels, with patch-level supervision. Specifically, we propose patch-labeling and filtering strategies to enable the model to focus on patch-level features exclusively with only image-level ordinal labels available. We further design a dual-level fuzzy learning module, which leverages fuzzy logic to quantitatively capture and handle label ambiguity from both patch-wise and channel-wise perspectives. Extensive experiments on various image ordinal regression datasets demonstrate the superiority of our proposed method, further confirming its ability in distinguishing samples from difficult-to-classify categories. The code is available at https://github.com/ZJUMAI/DFPG-ord.
GCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
Adapt2Reward: Adapting Video-Language Models to Generalizable Robotic Rewards via Failure Prompts
Jul 20, 2024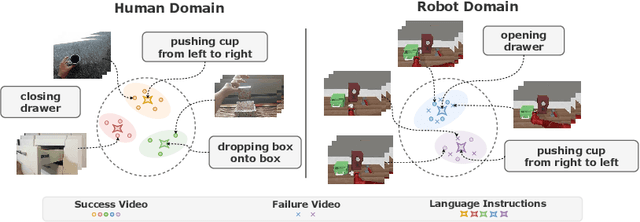
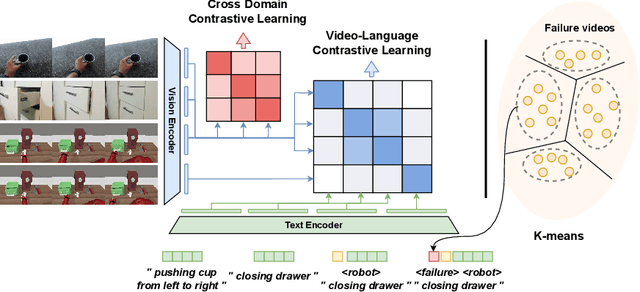
For a general-purpose robot to operate in reality, executing a broad range of instructions across various environments is imperative. Central to the reinforcement learning and planning for such robotic agents is a generalizable reward function. Recent advances in vision-language models, such as CLIP, have shown remarkable performance in the domain of deep learning, paving the way for open-domain visual recognition. However, collecting data on robots executing various language instructions across multiple environments remains a challenge. This paper aims to transfer video-language models with robust generalization into a generalizable language-conditioned reward function, only utilizing robot video data from a minimal amount of tasks in a singular environment. Unlike common robotic datasets used for training reward functions, human video-language datasets rarely contain trivial failure videos. To enhance the model's ability to distinguish between successful and failed robot executions, we cluster failure video features to enable the model to identify patterns within. For each cluster, we integrate a newly trained failure prompt into the text encoder to represent the corresponding failure mode. Our language-conditioned reward function shows outstanding generalization to new environments and new instructions for robot planning and reinforcement learning.
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
Oct 12, 2023



In the context of autonomous driving, the significance of effective feature learning is widely acknowledged. While conventional 3D self-supervised pre-training methods have shown widespread success, most methods follow the ideas originally designed for 2D images. In this paper, we present UniPAD, a novel self-supervised learning paradigm applying 3D volumetric differentiable rendering. UniPAD implicitly encodes 3D space, facilitating the reconstruction of continuous 3D shape structures and the intricate appearance characteristics of their 2D projections. The flexibility of our method enables seamless integration into both 2D and 3D frameworks, enabling a more holistic comprehension of the scenes. We manifest the feasibility and effectiveness of UniPAD by conducting extensive experiments on various downstream 3D tasks. Our method significantly improves lidar-, camera-, and lidar-camera-based baseline by 9.1, 7.7, and 6.9 NDS, respectively. Notably, our pre-training pipeline achieves 73.2 NDS for 3D object detection and 79.4 mIoU for 3D semantic segmentation on the nuScenes validation set, achieving state-of-the-art results in comparison with previous methods. The code will be available at https://github.com/Nightmare-n/UniPAD.
M$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
A Study of Unsupervised Evaluation Metrics for Practical and Automatic Domain Adaptation
Aug 01, 2023
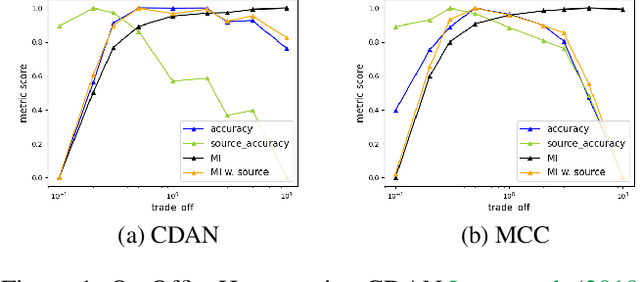
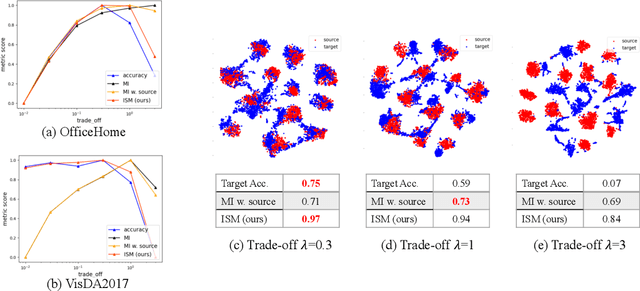
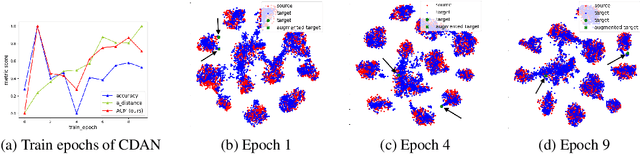
Unsupervised domain adaptation (UDA) methods facilitate the transfer of models to target domains without labels. However, these methods necessitate a labeled target validation set for hyper-parameter tuning and model selection. In this paper, we aim to find an evaluation metric capable of assessing the quality of a transferred model without access to target validation labels. We begin with the metric based on mutual information of the model prediction. Through empirical analysis, we identify three prevalent issues with this metric: 1) It does not account for the source structure. 2) It can be easily attacked. 3) It fails to detect negative transfer caused by the over-alignment of source and target features. To address the first two issues, we incorporate source accuracy into the metric and employ a new MLP classifier that is held out during training, significantly improving the result. To tackle the final issue, we integrate this enhanced metric with data augmentation, resulting in a novel unsupervised UDA metric called the Augmentation Consistency Metric (ACM). Additionally, we empirically demonstrate the shortcomings of previous experiment settings and conduct large-scale experiments to validate the effectiveness of our proposed metric. Furthermore, we employ our metric to automatically search for the optimal hyper-parameter set, achieving superior performance compared to manually tuned sets across four common benchmarks. Codes will be available soon.
SelFLoc: Selective Feature Fusion for Large-scale Point Cloud-based Place Recognition
Jun 05, 2023



Point cloud-based place recognition is crucial for mobile robots and autonomous vehicles, especially when the global positioning sensor is not accessible. LiDAR points are scattered on the surface of objects and buildings, which have strong shape priors along different axes. To enhance message passing along particular axes, Stacked Asymmetric Convolution Block (SACB) is designed, which is one of the main contributions in this paper. Comprehensive experiments demonstrate that asymmetric convolution and its corresponding strategies employed by SACB can contribute to the more effective representation of point cloud feature. On this basis, Selective Feature Fusion Block (SFFB), which is formed by stacking point- and channel-wise gating layers in a predefined sequence, is proposed to selectively boost salient local features in certain key regions, as well as to align the features before fusion phase. SACBs and SFFBs are combined to construct a robust and accurate architecture for point cloud-based place recognition, which is termed SelFLoc. Comparative experimental results show that SelFLoc achieves the state-of-the-art (SOTA) performance on the Oxford and other three in-house benchmarks with an improvement of 1.6 absolute percentages on mean average recall@1.
CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention
Mar 13, 2023
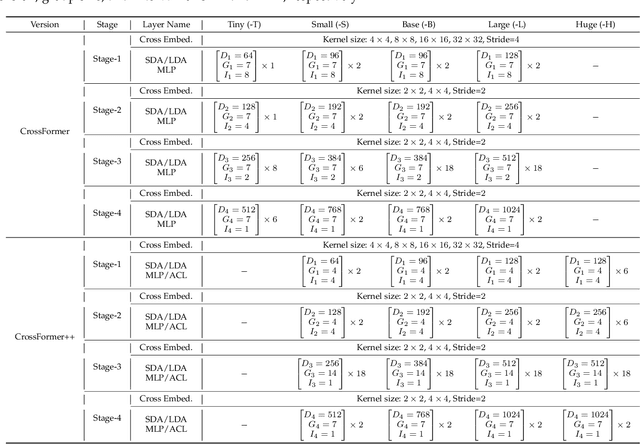
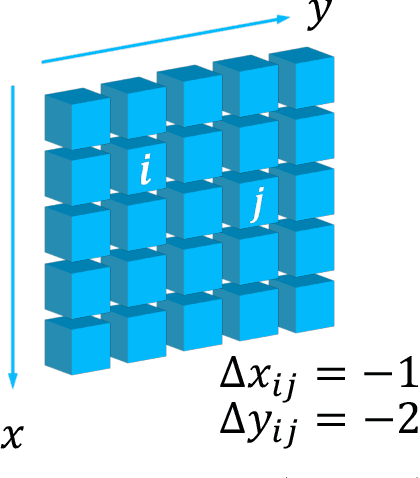
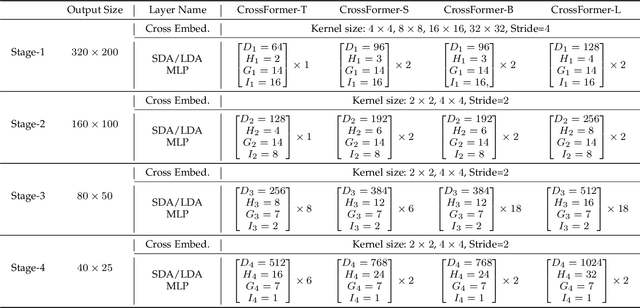
While features of different scales are perceptually important to visual inputs, existing vision transformers do not yet take advantage of them explicitly. To this end, we first propose a cross-scale vision transformer, CrossFormer. It introduces a cross-scale embedding layer (CEL) and a long-short distance attention (LSDA). On the one hand, CEL blends each token with multiple patches of different scales, providing the self-attention module itself with cross-scale features. On the other hand, LSDA splits the self-attention module into a short-distance one and a long-distance counterpart, which not only reduces the computational burden but also keeps both small-scale and large-scale features in the tokens. Moreover, through experiments on CrossFormer, we observe another two issues that affect vision transformers' performance, i.e. the enlarging self-attention maps and amplitude explosion. Thus, we further propose a progressive group size (PGS) paradigm and an amplitude cooling layer (ACL) to alleviate the two issues, respectively. The CrossFormer incorporating with PGS and ACL is called CrossFormer++. Extensive experiments show that CrossFormer++ outperforms the other vision transformers on image classification, object detection, instance segmentation, and semantic segmentation tasks. The code will be available at: https://github.com/cheerss/CrossFormer.