 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WDT-MD: Wavelet Diffusion Transformers for Microaneurysm Detection in Fundus Images
Nov 16, 2025Microaneurysms (MAs), the earliest pathognomonic signs of Diabetic Retinopathy (DR), present as sub-60 $μm$ lesions in fundus images with highly variable photometric and morphological characteristics, rendering manual screening not only labor-intensive but inherently error-prone. While diffusion-based anomaly detection has emerged as a promising approach for automated MA screening, its clinical application is hindered by three fundamental limitations. First, these models often fall prey to "identity mapping", where they inadvertently replicate the input image. Second, they struggle to distinguish MAs from other anomalies, leading to high false positives. Third, their suboptimal reconstruction of normal features hampers overall performance. To address these challenges, we propose a Wavelet Diffusion Transformer framework for MA Detection (WDT-MD), which features three key innovations: a noise-encoded image conditioning mechanism to avoid "identity mapping" by perturbing image conditions during training; pseudo-normal pattern synthesis via inpainting to introduce pixel-level supervision, enabling discrimination between MAs and other anomalies; and a wavelet diffusion Transformer architecture that combines the global modeling capability of diffusion Transformers with multi-scale wavelet analysis to enhance reconstruction of normal retinal features. Comprehensive experiments on the IDRiD and e-ophtha MA datasets demonstrate that WDT-MD outperforms state-of-the-art methods in both pixel-level and image-level MA detection. This advancement holds significant promise for improving early DR screening.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
MIRA: A Novel Framework for Fusing Modalities in Medical RAG
Jul 10, 2025Multimodal Large Language Models (MLLMs) have significantly advanced AI-assisted medical diagnosis, but they often generate factually inconsistent responses that deviate from established medical knowledge. Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external sources, but it presents two key challenges. First, insufficient retrieval can miss critical information, whereas excessive retrieval can introduce irrelevant or misleading content, disrupting model output. Second, even when the model initially provides correct answers, over-reliance on retrieved data can lead to factual errors. To address these issues, we introduce the Multimodal Intelligent Retrieval and Augmentation (MIRA) framework, designed to optimize factual accuracy in MLLM. MIRA consists of two key components: (1) a calibrated Rethinking and Rearrangement module that dynamically adjusts the number of retrieved contexts to manage factual risk, and (2) A medical RAG framework integrating image embeddings and a medical knowledge base with a query-rewrite module for efficient multimodal reasoning. This enables the model to effectively integrate both its inherent knowledge and external references. Our evaluation of publicly available medical VQA and report generation benchmarks demonstrates that MIRA substantially enhances factual accuracy and overall performance, achieving new state-of-the-art results. Code is released at https://github.com/mbzuai-oryx/MIRA.
Dual-level Fuzzy Learning with Patch Guidance for Image Ordinal Regression
May 09, 2025Ordinal regression bridges regression and classification by assigning objects to ordered classes. While human experts rely on discriminative patch-level features for decisions, current approaches are limited by the availability of only image-level ordinal labels, overlooking fine-grained patch-level characteristics. In this paper, we propose a Dual-level Fuzzy Learning with Patch Guidance framework, named DFPG that learns precise feature-based grading boundaries from ambiguous ordinal labels, with patch-level supervision. Specifically, we propose patch-labeling and filtering strategies to enable the model to focus on patch-level features exclusively with only image-level ordinal labels available. We further design a dual-level fuzzy learning module, which leverages fuzzy logic to quantitatively capture and handle label ambiguity from both patch-wise and channel-wise perspectives. Extensive experiments on various image ordinal regression datasets demonstrate the superiority of our proposed method, further confirming its ability in distinguishing samples from difficult-to-classify categories. The code is available at https://github.com/ZJUMAI/DFPG-ord.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
OrderChain: A General Prompting Paradigm to Improve Ordinal Understanding Ability of MLLM
Apr 07, 2025Despite the remarkable progress of multimodal large language models (MLLMs), they continue to face challenges in achieving competitive performance on ordinal regression (OR; a.k.a. ordinal classification). To address this issue, this paper presents OrderChain, a novel and general prompting paradigm that improves the ordinal understanding ability of MLLMs by specificity and commonality modeling. Specifically, our OrderChain consists of a set of task-aware prompts to facilitate the specificity modeling of diverse OR tasks and a new range optimization Chain-of-Thought (RO-CoT), which learns a commonality way of thinking about OR tasks by uniformly decomposing them into multiple small-range optimization subtasks. Further, we propose a category recursive division (CRD) method to generate instruction candidate category prompts to support RO-CoT automatic optimization. Comprehensive experiments show that a Large Language and Vision Assistant (LLaVA) model with our OrderChain improves baseline LLaVA significantly on diverse OR datasets, e.g., from 47.5% to 93.2% accuracy on the Adience dataset for age estimation, and from 30.0% to 85.7% accuracy on the Diabetic Retinopathy dataset. Notably, LLaVA with our OrderChain also remarkably outperforms state-of-the-art methods by 27% on accuracy and 0.24 on MAE on the Adience dataset. To our best knowledge, our OrderChain is the first work that augments MLLMs for OR tasks, and the effectiveness is witnessed across a spectrum of OR datasets.
A Survey on Ordinal Regression: Applications, Advances and Prospects
Mar 02, 2025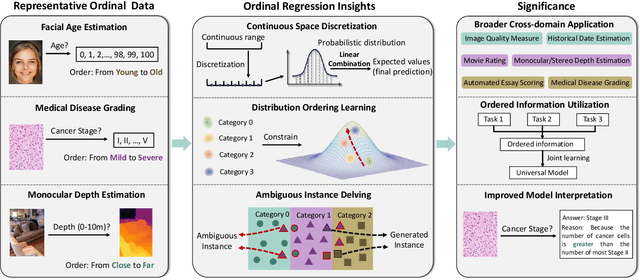
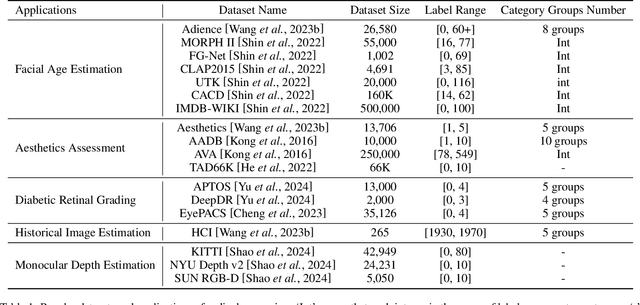
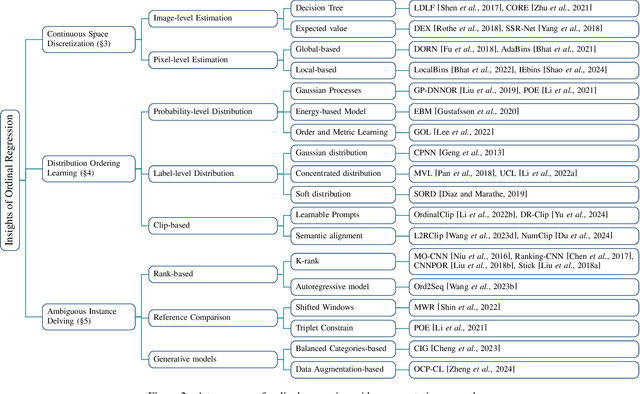
Ordinal regression refers to classifying object instances into ordinal categories. Ordinal regression is crucial for applications in various areas like facial age estimation, image aesthetics assessment, and even cancer staging, due to its capability to utilize ordered information effectively. More importantly, it also enhances model interpretation by considering category order, aiding the understanding of data trends and causal relationships. Despite significant recent progress, challenges remain, and further investigation of ordinal regression techniques and applications is essential to guide future research. In this survey, we present a comprehensive examination of advances and applications of ordinal regression. By introducing a systematic taxonomy, we meticulously classify the pertinent techniques and applications into three well-defined categories based on different strategies and objectives: Continuous Space Discretization, Distribution Ordering Learning, and Ambiguous Instance Delving. This categorization enables a structured exploration of diverse insights in ordinal regression problems, providing a framework for a more comprehensive understanding and evaluation of this field and its related applications. To our best knowledge, this is the first systematic survey of ordinal regression, which lays a foundation for future research in this fundamental and generic domain.
Scalable Autoregressive Monocular Depth Estimation
Nov 18, 2024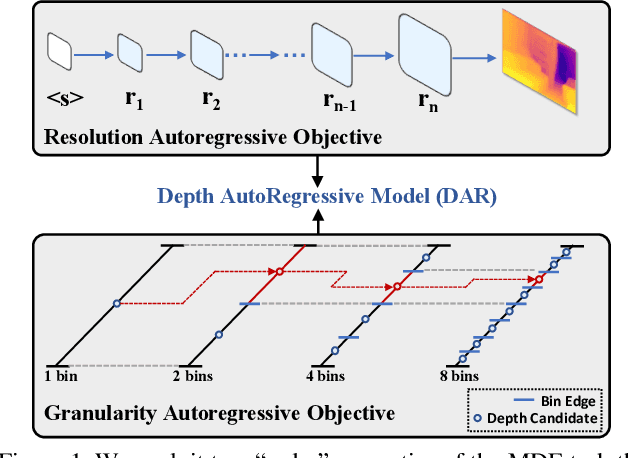
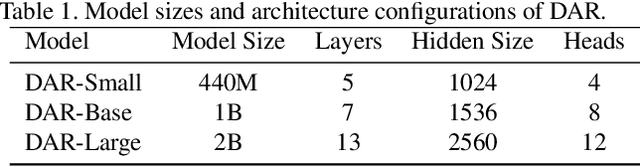
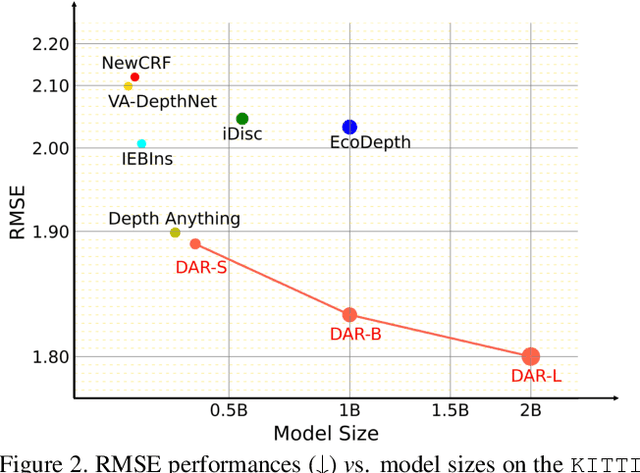
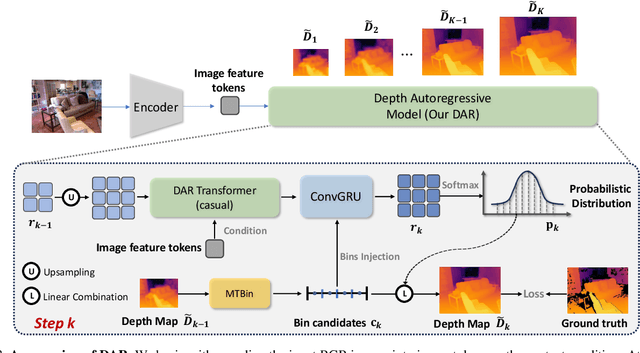
This paper proposes a new autoregressive model as an effective and scalable monocular depth estimator. Our idea is simple: We tackle the monocular depth estimation (MDE) task with an autoregressive prediction paradigm, based on two core designs. First, our depth autoregressive model (DAR) treats the depth map of different resolutions as a set of tokens, and conducts the low-to-high resolution autoregressive objective with a patch-wise casual mask. Second, our DAR recursively discretizes the entire depth range into more compact intervals, and attains the coarse-to-fine granularity autoregressive objective in an ordinal-regression manner. By coupling these two autoregressive objectives, our DAR establishes new state-of-the-art (SOTA) on KITTI and NYU Depth v2 by clear margins. Further, our scalable approach allows us to scale the model up to 2.0B and achieve the best RMSE of 1.799 on the KITTI dataset (5% improvement) compared to 1.896 by the current SOTA (Depth Anything). DAR further showcases zero-shot generalization ability on unseen datasets. These results suggest that DAR yields superior performance with an autoregressive prediction paradigm, providing a promising approach to equip modern autoregressive large models (e.g., GPT-4o) with depth estimation capabilities.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.