 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenPros: A Large-Scale Dataset for Limited View Prostate Ultrasound Computed Tomography
May 18, 2025Prostate cancer is one of the most common and lethal cancers among men, making its early detection critically important. Although ultrasound imaging offers greater accessibility and cost-effectiveness compared to MRI, traditional transrectal ultrasound methods suffer from low sensitivity, especially in detecting anteriorly located tumors. Ultrasound computed tomography provides quantitative tissue characterization, but its clinical implementation faces significant challenges, particularly under anatomically constrained limited-angle acquisition conditions specific to prostate imaging. To address these unmet needs, we introduce OpenPros, the first large-scale benchmark dataset explicitly developed for limited-view prostate USCT. Our dataset includes over 280,000 paired samples of realistic 2D speed-of-sound (SOS) phantoms and corresponding ultrasound full-waveform data, generated from anatomically accurate 3D digital prostate models derived from real clinical MRI/CT scans and ex vivo ultrasound measurements, annotated by medical experts. Simulations are conducted under clinically realistic configurations using advanced finite-difference time-domain and Runge-Kutta acoustic wave solvers, both provided as open-source components. Through comprehensive baseline experiments, we demonstrate that state-of-the-art deep learning methods surpass traditional physics-based approaches in both inference efficiency and reconstruction accuracy. Nevertheless, current deep learning models still fall short of delivering clinically acceptable high-resolution images with sufficient accuracy. By publicly releasing OpenPros, we aim to encourage the development of advanced machine learning algorithms capable of bridging this performance gap and producing clinically usable, high-resolution, and highly accurate prostate ultrasound images. The dataset is publicly accessible at https://open-pros.github.io/.
Take Your Steps: Hierarchically Efficient Pulmonary Disease Screening via CT Volume Compression
Dec 03, 2024Deep learning models are widely used to process Computed Tomography (CT) data in the automated screening of pulmonary diseases, significantly reducing the workload of physicians. However, the three-dimensional nature of CT volumes involves an excessive number of voxels, which significantly increases the complexity of model processing. Previous screening approaches often overlook this issue, which undoubtedly reduces screening efficiency. Towards efficient and effective screening, we design a hierarchical approach to reduce the computational cost of pulmonary disease screening. The new approach re-organizes the screening workflows into three steps. First, we propose a Computed Tomography Volume Compression (CTVC) method to select a small slice subset that comprehensively represents the whole CT volume. Second, the selected CT slices are used to detect pulmonary diseases coarsely via a lightweight classification model. Third, an uncertainty measurement strategy is applied to identify samples with low diagnostic confidence, which are re-detected by radiologists. Experiments on two public pulmonary disease datasets demonstrate that our approach achieves comparable accuracy and recall while reducing the time by 50%-70% compared with the counterparts using full CT volumes. Besides, we also found that our approach outperforms previous cutting-edge CTVC methods in retaining important indications after compression.
Rethinking the Evaluation of Visible and Infrared Image Fusion
Oct 09, 2024



Visible and Infrared Image Fusion (VIF) has garnered significant interest across a wide range of high-level vision tasks, such as object detection and semantic segmentation. However, the evaluation of VIF methods remains challenging due to the absence of ground truth. This paper proposes a Segmentation-oriented Evaluation Approach (SEA) to assess VIF methods by incorporating the semantic segmentation task and leveraging segmentation labels available in latest VIF datasets. Specifically, SEA utilizes universal segmentation models, capable of handling diverse images and classes, to predict segmentation outputs from fused images and compare these outputs with segmentation labels. Our evaluation of recent VIF methods using SEA reveals that their performance is comparable or even inferior to using visible images only, despite nearly half of the infrared images demonstrating better performance than visible images. Further analysis indicates that the two metrics most correlated to our SEA are the gradient-based fusion metric $Q_{\text{ABF}}$ and the visual information fidelity metric $Q_{\text{VIFF}}$ in conventional VIF evaluation metrics, which can serve as proxies when segmentation labels are unavailable. We hope that our evaluation will guide the development of novel and practical VIF methods. The code has been released in \url{https://github.com/Yixuan-2002/SEA/}.
LLMCount: Enhancing Stationary mmWave Detection with Multimodal-LLM
Sep 24, 2024



Millimeter wave sensing provides people with the capability of sensing the surrounding crowds in a non-invasive and privacy-preserving manner, which holds huge application potential. However, detecting stationary crowds remains challenging due to several factors such as minimal movements (like breathing or casual fidgets), which can be easily treated as noise clusters during data collection and consequently filtered in the following processing procedures. Additionally, the uneven distribution of signal power due to signal power attenuation and interferences resulting from external reflectors or absorbers further complicates accurate detection. To address these challenges and enable stationary crowd detection across various application scenarios requiring specialized domain adaption, we introduce LLMCount, the first system to harness the capabilities of large-language models (LLMs) to enhance crowd detection performance. By exploiting the decision-making capability of LLM, we can successfully compensate the signal power to acquire a uniform distribution and thereby achieve a detection with higher accuracy. To assess the system's performance, comprehensive evaluations are conducted under diversified scenarios like hall, meeting room, and cinema. The evaluation results show that our proposed approach reaches high detection accuracy with lower overall latency compared with previous methods.
MambaCapsule: Towards Transparent Cardiac Disease Diagnosis with Electrocardiography Using Mamba Capsule Network
Jul 30, 2024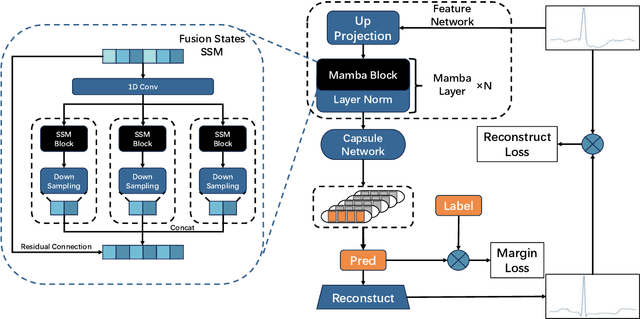

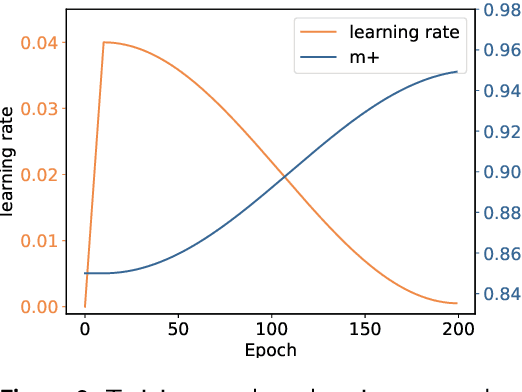
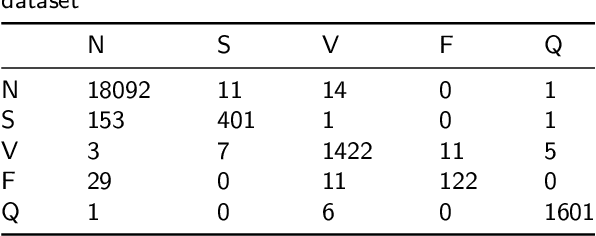
Cardiac arrhythmia, a condition characterized by irregular heartbeats, often serves as an early indication of various heart ailments. With the advent of deep learning, numerous innovative models have been introduced for diagnosing arrhythmias using Electrocardiogram (ECG) signals. However, recent studies solely focus on the performance of models, neglecting the interpretation of their results. This leads to a considerable lack of transparency, posing a significant risk in the actual diagnostic process. To solve this problem, this paper introduces MambaCapsule, a deep neural networks for ECG arrhythmias classification, which increases the explainability of the model while enhancing the accuracy.Our model utilizes Mamba for feature extraction and Capsule networks for prediction, providing not only a confidence score but also signal features. Akin to the processing mechanism of human brain, the model learns signal features and their relationship between them by reconstructing ECG signals in the predicted selection. The model evaluation was conducted on MIT-BIH and PTB dataset, following the AAMI standard. MambaCapsule has achieved a total accuracy of 99.54% and 99.59% on the test sets respectively. These results demonstrate the promising performance of under the standard test protocol.
TeleOR: Real-time Telemedicine System for Full-Scene Operating Room
Jul 29, 2024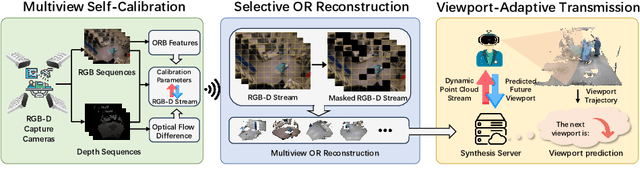


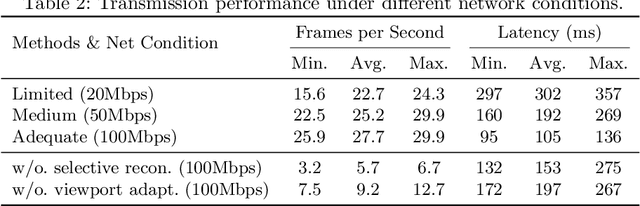
The advent of telemedicine represents a transformative development in leveraging technology to extend the reach of specialized medical expertise to remote surgeries, a field where the immediacy of expert guidance is paramount. However, the intricate dynamics of Operating Room (OR) scene pose unique challenges for telemedicine, particularly in achieving high-fidelity, real-time scene reconstruction and transmission amidst obstructions and bandwidth limitations. This paper introduces TeleOR, a pioneering system designed to address these challenges through real-time OR scene reconstruction for Tele-intervention. TeleOR distinguishes itself with three innovative approaches: dynamic self-calibration, which leverages inherent scene features for calibration without the need for preset markers, allowing for obstacle avoidance and real-time camera adjustment; selective OR reconstruction, focusing on dynamically changing scene segments to reduce reconstruction complexity; and viewport-adaptive transmission, optimizing data transmission based on real-time client feedback to efficiently deliver high-quality 3D reconstructions within bandwidth constraints. Comprehensive experiments on the 4D-OR surgical scene dataset demostrate the superiority and applicability of TeleOR, illuminating the potential to revolutionize tele-interventions by overcoming the spatial and technical barriers inherent in remote surgical guidance.
Multi-Modal CLIP-Informed Protein Editing
Jul 27, 2024Proteins govern most biological functions essential for life, but achieving controllable protein discovery and optimization remains challenging. Recently, machine learning-assisted protein editing (MLPE) has shown promise in accelerating optimization cycles and reducing experimental workloads. However, current methods struggle with the vast combinatorial space of potential protein edits and cannot explicitly conduct protein editing using biotext instructions, limiting their interactivity with human feedback. To fill these gaps, we propose a novel method called ProtET for efficient CLIP-informed protein editing through multi-modality learning. Our approach comprises two stages: in the pretraining stage, contrastive learning aligns protein-biotext representations encoded by two large language models (LLMs), respectively. Subsequently, during the protein editing stage, the fused features from editing instruction texts and original protein sequences serve as the final editing condition for generating target protein sequences. Comprehensive experiments demonstrated the superiority of ProtET in editing proteins to enhance human-expected functionality across multiple attribute domains, including enzyme catalytic activity, protein stability and antibody specific binding ability. And ProtET improves the state-of-the-art results by a large margin, leading to significant stability improvements of 16.67% and 16.90%. This capability positions ProtET to advance real-world artificial protein editing, potentially addressing unmet academic, industrial, and clinical needs.
PoCo: A Self-Supervised Approach via Polar Transformation Based Progressive Contrastive Learning for Ophthalmic Disease Diagnosis
Mar 28, 2024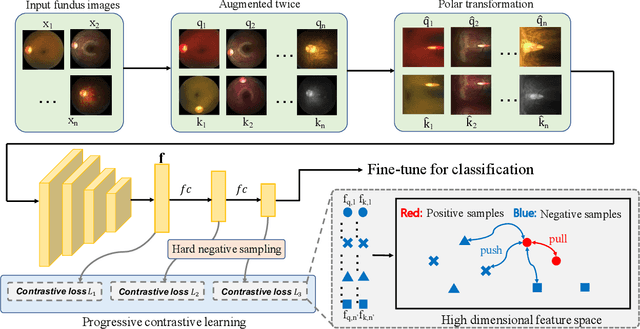
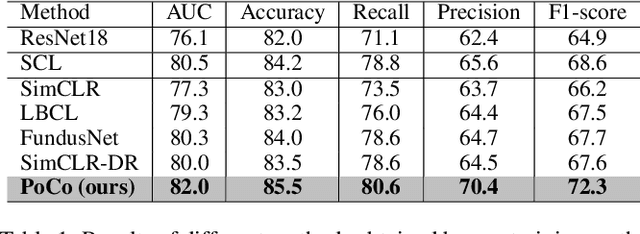


Automatic ophthalmic disease diagnosis on fundus images is important in clinical practice. However, due to complex fundus textures and limited annotated data, developing an effective automatic method for this problem is still challenging. In this paper, we present a self-supervised method via polar transformation based progressive contrastive learning, called PoCo, for ophthalmic disease diagnosis. Specifically, we novelly inject the polar transformation into contrastive learning to 1) promote contrastive learning pre-training to be faster and more stable and 2) naturally capture task-free and rotation-related textures, which provides insights into disease recognition on fundus images. Beneficially, simple normal translation-invariant convolution on transformed images can equivalently replace the complex rotation-invariant and sector convolution on raw images. After that, we develop a progressive contrastive learning method to efficiently utilize large unannotated images and a novel progressive hard negative sampling scheme to gradually reduce the negative sample number for efficient training and performance enhancement. Extensive experiments on three public ophthalmic disease datasets show that our PoCo achieves state-of-the-art performance with good generalization ability, validating that our method can reduce annotation efforts and provide reliable diagnosis. Codes are available at \url{https://github.com/wjh892521292/PoCo}.
DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
Mar 19, 2024We present DetToolChain, a novel prompting paradigm, to unleash the zero-shot object detection ability of multimodal large language models (MLLMs), such as GPT-4V and Gemini. Our approach consists of a detection prompting toolkit inspired by high-precision detection priors and a new Chain-of-Thought to implement these prompts. Specifically, the prompts in the toolkit are designed to guide the MLLM to focus on regional information (e.g., zooming in), read coordinates according to measure standards (e.g., overlaying rulers and compasses), and infer from the contextual information (e.g., overlaying scene graphs). Building upon these tools, the new detection chain-of-thought can automatically decompose the task into simple subtasks, diagnose the predictions, and plan for progressive box refinements. The effectiveness of our framework is demonstrated across a spectrum of detection tasks, especially hard cases. Compared to existing state-of-the-art methods, GPT-4V with our DetToolChain improves state-of-the-art object detectors by +21.5% AP50 on MS COCO Novel class set for open-vocabulary detection, +24.23% Acc on RefCOCO val set for zero-shot referring expression comprehension, +14.5% AP on D-cube describe object detection FULL setting.
BlindDiff: Empowering Degradation Modelling in Diffusion Models for Blind Image Super-Resolution
Mar 15, 2024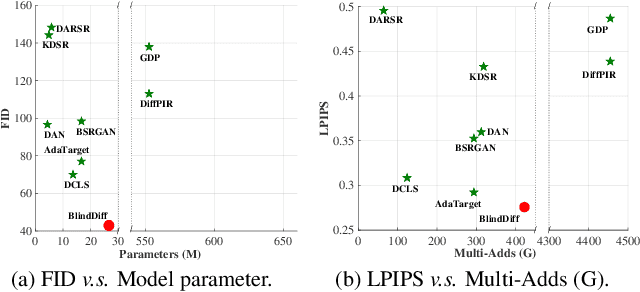

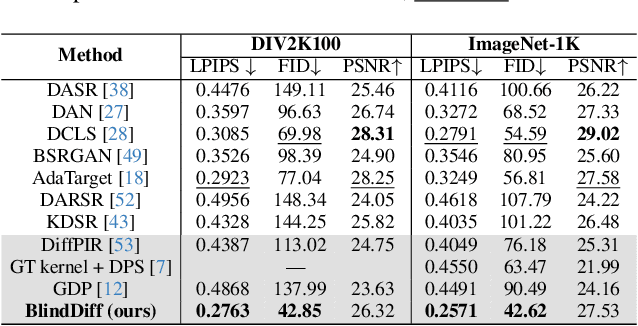
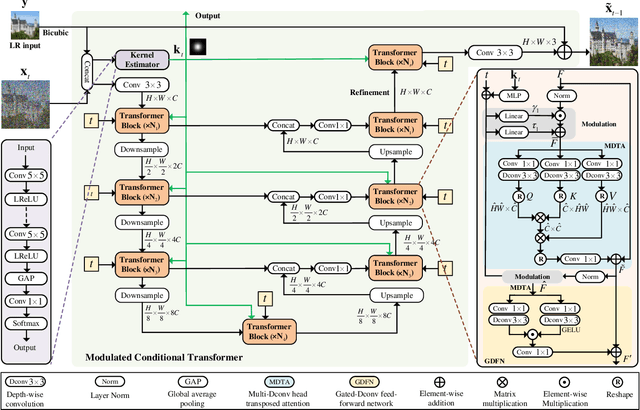
Diffusion models (DM) have achieved remarkable promise in image super-resolution (SR). However, most of them are tailored to solving non-blind inverse problems with fixed known degradation settings, limiting their adaptability to real-world applications that involve complex unknown degradations. In this work, we propose BlindDiff, a DM-based blind SR method to tackle the blind degradation settings in SISR. BlindDiff seamlessly integrates the MAP-based optimization into DMs, which constructs a joint distribution of the low-resolution (LR) observation, high-resolution (HR) data, and degradation kernels for the data and kernel priors, and solves the blind SR problem by unfolding MAP approach along with the reverse process. Unlike most DMs, BlindDiff firstly presents a modulated conditional transformer (MCFormer) that is pre-trained with noise and kernel constraints, further serving as a posterior sampler to provide both priors simultaneously. Then, we plug a simple yet effective kernel-aware gradient term between adjacent sampling iterations that guides the diffusion model to learn degradation consistency knowledge. This also enables to joint refine the degradation model as well as HR images by observing the previous denoised sample. With the MAP-based reverse diffusion process, we show that BlindDiff advocates alternate optimization for blur kernel estimation and HR image restoration in a mutual reinforcing manner. Experiments on both synthetic and real-world datasets show that BlindDiff achieves the state-of-the-art performance with significant model complexity reduction compared to recent DM-based methods. Code will be available at \url{https://github.com/lifengcs/BlindDiff}