 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning of Optimal Sequential Testing Policies
Sep 03, 2025



This paper studies an online learning problem that seeks optimal testing policies for a stream of subjects, each of whom can be evaluated through a sequence of candidate tests drawn from a common pool. We refer to this problem as the Online Testing Problem (OTP). Although conducting every candidate test for a subject provides more information, it is often preferable to select only a subset when tests are correlated and costly, and make decisions with partial information. If the joint distribution of test outcomes were known, the problem could be cast as a Markov Decision Process (MDP) and solved exactly. In practice, this distribution is unknown and must be learned online as subjects are tested. When a subject is not fully tested, the resulting missing data can bias estimates, making the problem fundamentally harder than standard episodic MDPs. We prove that the minimax regret must scale at least as $\Omega(T^{\frac{2}{3}})$, in contrast to the $\Theta(\sqrt{T})$ rate in episodic MDPs, revealing the difficulty introduced by missingness. This elevated lower bound is then matched by an Explore-Then-Commit algorithm whose cumulative regret is $\tilde{O}(T^{\frac{2}{3}})$ for both discrete and Gaussian distributions. To highlight the consequence of missingness-dependent rewards in OTP, we study a variant called the Online Cost-sensitive Maximum Entropy Sampling Problem, where rewards are independent of missing data. This structure enables an iterative-elimination algorithm that achieves $\tilde{O}(\sqrt{T})$ regret, breaking the $\Omega(T^{\frac{2}{3}})$ lower bound for OTP. Numerical results confirm our theory in both settings. Overall, this work deepens the understanding of the exploration--exploitation trade-off under missing data and guides the design of efficient sequential testing policies.
Mitigating Hallucination of Large Vision-Language Models via Dynamic Logits Calibration
Jun 26, 2025Large Vision-Language Models (LVLMs) have demonstrated significant advancements in multimodal understanding, yet they are frequently hampered by hallucination-the generation of text that contradicts visual input. Existing training-free decoding strategies exhibit critical limitations, including the use of static constraints that do not adapt to semantic drift during generation, inefficiency stemming from the need for multiple forward passes, and degradation of detail due to overly rigid intervention rules. To overcome these challenges, this paper introduces Dynamic Logits Calibration (DLC), a novel training-free decoding framework designed to dynamically align text generation with visual evidence at inference time. At the decoding phase, DLC step-wise employs CLIP to assess the semantic alignment between the input image and the generated text sequence. Then, the Relative Visual Advantage (RVA) of candidate tokens is evaluated against a dynamically updated contextual baseline, adaptively adjusting output logits to favor tokens that are visually grounded. Furthermore, an adaptive weighting mechanism, informed by a real-time context alignment score, carefully balances the visual guidance while ensuring the overall quality of the textual output. Extensive experiments conducted across diverse benchmarks and various LVLM architectures (such as LLaVA, InstructBLIP, and MiniGPT-4) demonstrate that DLC significantly reduces hallucinations, outperforming current methods while maintaining high inference efficiency by avoiding multiple forward passes. Overall, we present an effective and efficient decoding-time solution to mitigate hallucinations, thereby enhancing the reliability of LVLMs for more practices. Code will be released on Github.
ASMA-Tune: Unlocking LLMs' Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Mar 14, 2025Analysis and comprehension of assembly code are crucial in various applications, such as reverse engineering. However, the low information density and lack of explicit syntactic structures in assembly code pose significant challenges. Pioneering approaches with masked language modeling (MLM)-based methods have been limited by facilitating natural language interaction. While recent methods based on decoder-focused large language models (LLMs) have significantly enhanced semantic representation, they still struggle to capture the nuanced and sparse semantics in assembly code. In this paper, we propose Assembly Augmented Tuning (ASMA-Tune), an end-to-end structural-semantic instruction-tuning framework. Our approach synergizes encoder architectures with decoder-based LLMs through projector modules to enable comprehensive code understanding. Experiments show that ASMA-Tune outperforms existing benchmarks, significantly enhancing assembly code comprehension and instruction-following abilities. Our model and dataset are public at https://github.com/wxy3596/ASMA-Tune.
Generation of Drug-Induced Cardiac Reactions towards Virtual Clinical Trials
Feb 11, 2025
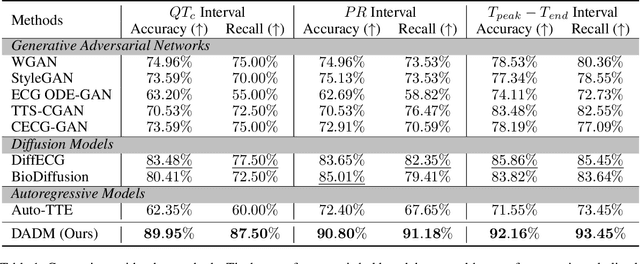
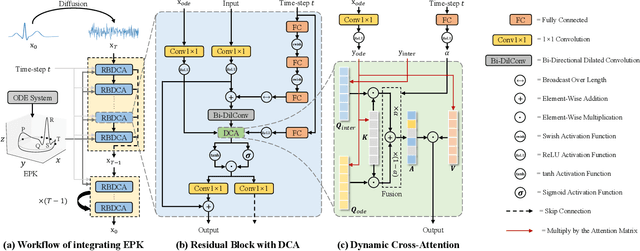
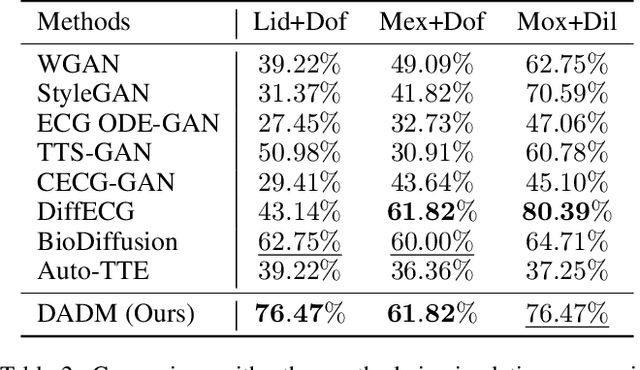
Clinical trials are pivotal in cardiac drug development, yet they often fail due to inadequate efficacy and unexpected safety issues, leading to significant financial losses. Using in-silico trials to replace a part of physical clinical trials, e.g., leveraging advanced generative models to generate drug-influenced electrocardiograms (ECGs), seems an effective method to reduce financial risk and potential harm to trial participants. While existing generative models have demonstrated progress in ECG generation, they fall short in modeling drug reactions due to limited fidelity and inability to capture individualized drug response patterns. In this paper, we propose a Drug-Aware Diffusion Model (DADM), which could simulate individualized drug reactions while ensuring fidelity. To ensure fidelity, we construct a set of ordinary differential equations to provide external physical knowledge (EPK) of the realistic ECG morphology. The EPK is used to adaptively constrain the morphology of the generated ECGs through a dynamic cross-attention (DCA) mechanism. Furthermore, we propose an extension of ControlNet to incorporate demographic and drug data, simulating individual drug reactions. We compare DADM with the other eight state-of-the-art ECG generative models on two real-world databases covering 8 types of drug regimens. The results demonstrate that DADM can more accurately simulate drug-induced changes in ECGs, improving the accuracy by at least 5.79% and recall by 8%.
Take Your Steps: Hierarchically Efficient Pulmonary Disease Screening via CT Volume Compression
Dec 03, 2024Deep learning models are widely used to process Computed Tomography (CT) data in the automated screening of pulmonary diseases, significantly reducing the workload of physicians. However, the three-dimensional nature of CT volumes involves an excessive number of voxels, which significantly increases the complexity of model processing. Previous screening approaches often overlook this issue, which undoubtedly reduces screening efficiency. Towards efficient and effective screening, we design a hierarchical approach to reduce the computational cost of pulmonary disease screening. The new approach re-organizes the screening workflows into three steps. First, we propose a Computed Tomography Volume Compression (CTVC) method to select a small slice subset that comprehensively represents the whole CT volume. Second, the selected CT slices are used to detect pulmonary diseases coarsely via a lightweight classification model. Third, an uncertainty measurement strategy is applied to identify samples with low diagnostic confidence, which are re-detected by radiologists. Experiments on two public pulmonary disease datasets demonstrate that our approach achieves comparable accuracy and recall while reducing the time by 50%-70% compared with the counterparts using full CT volumes. Besides, we also found that our approach outperforms previous cutting-edge CTVC methods in retaining important indications after compression.
The Traveling Bandit: A Framework for Bayesian Optimization with Movement Costs
Oct 18, 2024This paper introduces a framework for Bayesian Optimization (BO) with metric movement costs, addressing a critical challenge in practical applications where input alterations incur varying costs. Our approach is a convenient plug-in that seamlessly integrates with the existing literature on batched algorithms, where designs within batches are observed following the solution of a Traveling Salesman Problem. The proposed method provides a theoretical guarantee of convergence in terms of movement costs for BO. Empirically, our method effectively reduces average movement costs over time while maintaining comparable regret performance to conventional BO methods. This framework also shows promise for broader applications in various bandit settings with movement costs.
Enhancing Semi-Supervised Learning via Representative and Diverse Sample Selection
Sep 18, 2024Semi-Supervised Learning (SSL) has become a preferred paradigm in many deep learning tasks, which reduces the need for human labor. Previous studies primarily focus on effectively utilising the labelled and unlabeled data to improve performance. However, we observe that how to select samples for labelling also significantly impacts performance, particularly under extremely low-budget settings. The sample selection task in SSL has been under-explored for a long time. To fill in this gap, we propose a Representative and Diverse Sample Selection approach (RDSS). By adopting a modified Frank-Wolfe algorithm to minimise a novel criterion $\alpha$-Maximum Mean Discrepancy ($\alpha$-MMD), RDSS samples a representative and diverse subset for annotation from the unlabeled data. We demonstrate that minimizing $\alpha$-MMD enhances the generalization ability of low-budget learning. Experimental results show that RDSS consistently improves the performance of several popular SSL frameworks and outperforms the state-of-the-art sample selection approaches used in Active Learning (AL) and Semi-Supervised Active Learning (SSAL), even with constrained annotation budgets.
Alleviating Hallucination in Large Vision-Language Models with Active Retrieval Augmentation
Aug 01, 2024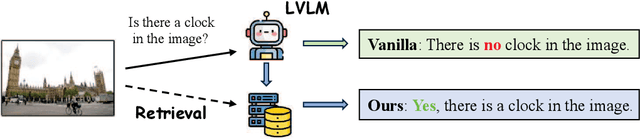
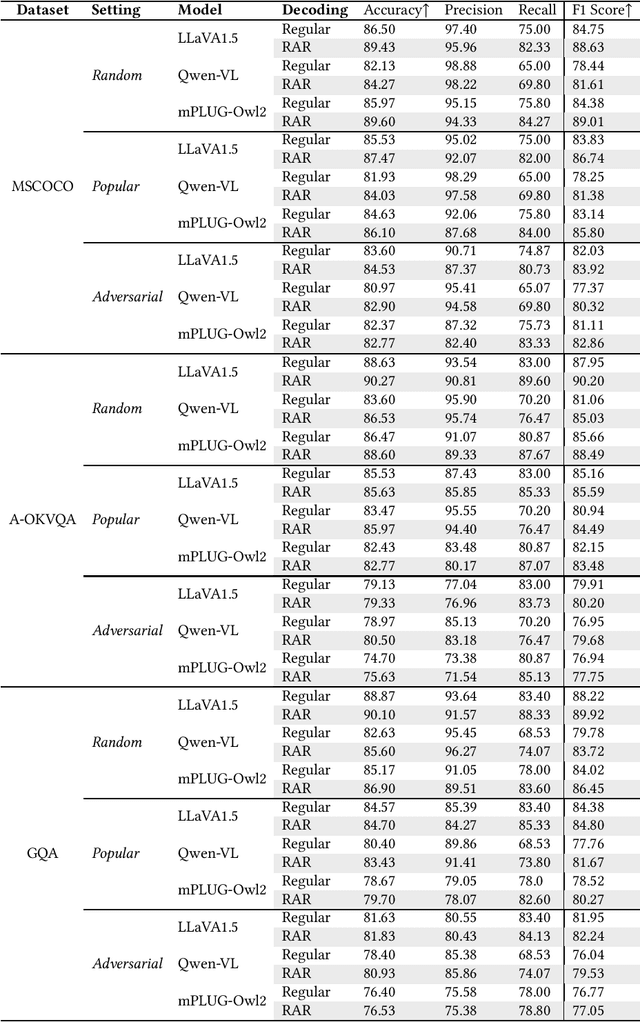
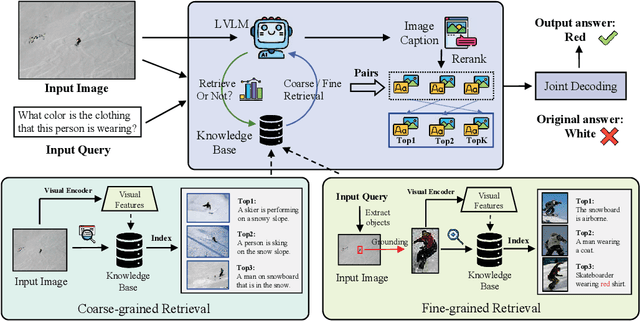
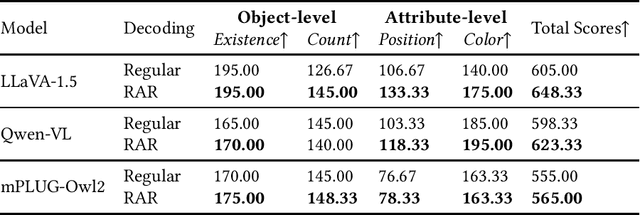
Despite the remarkable ability of large vision-language models (LVLMs) in image comprehension, these models frequently generate plausible yet factually incorrect responses, a phenomenon known as hallucination.Recently, in large language models (LLMs), augmenting LLMs by retrieving information from external knowledge resources has been proven as a promising solution to mitigate hallucinations.However, the retrieval augmentation in LVLM significantly lags behind the widespread applications of LVLM. Moreover, when transferred to augmenting LVLMs, sometimes the hallucination degree of the model is even exacerbated.Motivated by the research gap and counter-intuitive phenomenon, we introduce a novel framework, the Active Retrieval-Augmented large vision-language model (ARA), specifically designed to address hallucinations by incorporating three critical dimensions: (i) dissecting the retrieval targets based on the inherent hierarchical structures of images. (ii) pinpointing the most effective retrieval methods and filtering out the reliable retrieval results. (iii) timing the retrieval process to coincide with episodes of low certainty, while circumventing unnecessary retrieval during periods of high certainty. To assess the capability of our proposed ARA model in reducing hallucination, we employ three widely used LVLM models (LLaVA-1.5, Qwen-VL, and mPLUG-Owl2) across four benchmarks. Our empirical observations suggest that by utilizing fitting retrieval mechanisms and timing the retrieval judiciously, we can effectively mitigate the hallucination problem. We hope that this study can provide deeper insights into how to adapt the retrieval augmentation to LVLMs for reducing hallucinations with more effective retrieval and minimal retrieval occurrences.
Cross-Table Pretraining towards a Universal Function Space for Heterogeneous Tabular Data
Jun 01, 2024


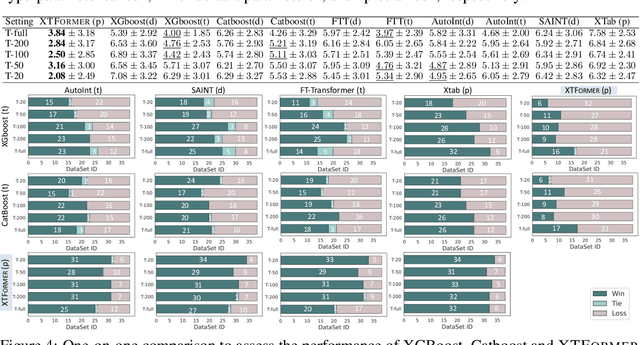
Tabular data from different tables exhibit significant diversity due to varied definitions and types of features, as well as complex inter-feature and feature-target relationships. Cross-dataset pretraining, which learns reusable patterns from upstream data to support downstream tasks, have shown notable success in various fields. Yet, when applied to tabular data prediction, this paradigm faces challenges due to the limited reusable patterns among diverse tabular datasets (tables) and the general scarcity of tabular data available for fine-tuning. In this study, we fill this gap by introducing a cross-table pretrained Transformer, XTFormer, for versatile downstream tabular prediction tasks. Our methodology insight is pretraining XTFormer to establish a "meta-function" space that encompasses all potential feature-target mappings. In pre-training, a variety of potential mappings are extracted from pre-training tabular datasets and are embedded into the "meta-function" space, and suited mappings are extracted from the "meta-function" space for downstream tasks by a specified coordinate positioning approach. Experiments show that, in 190 downstream tabular prediction tasks, our cross-table pretrained XTFormer wins both XGBoost and Catboost on 137 (72%) tasks, and surpasses representative deep learning models FT-Transformer and the tabular pre-training approach XTab on 144 (76%) and 162 (85%) tasks.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

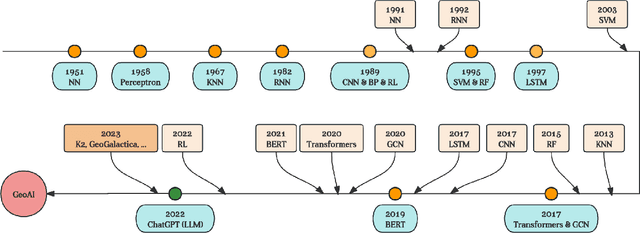
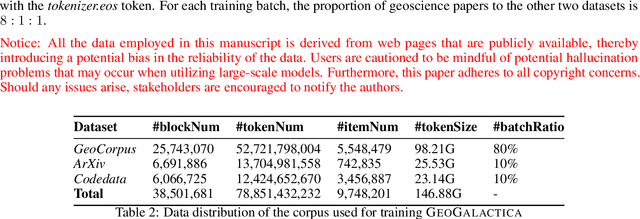
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.