 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Hallucination in Large Vision-Language Models with Active Retrieval Augmentation
Aug 01, 2024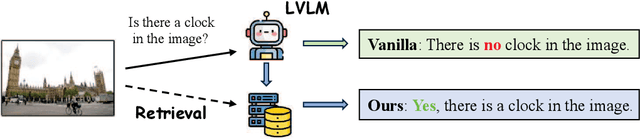
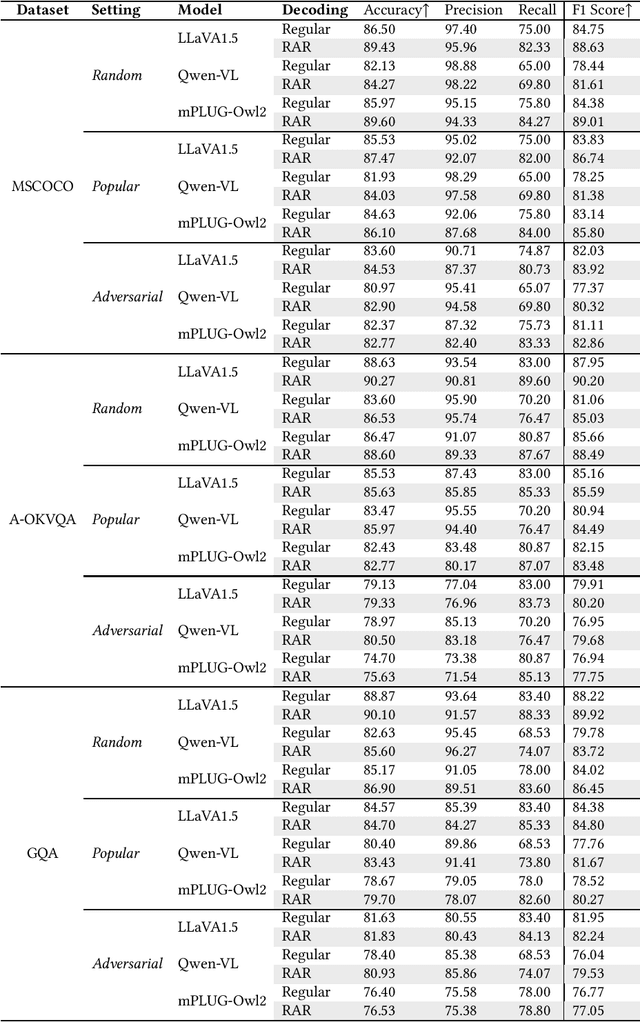
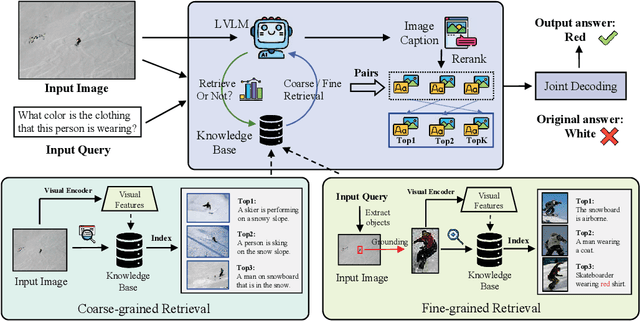
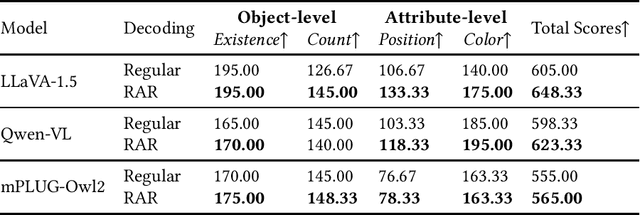
Despite the remarkable ability of large vision-language models (LVLMs) in image comprehension, these models frequently generate plausible yet factually incorrect responses, a phenomenon known as hallucination.Recently, in large language models (LLMs), augmenting LLMs by retrieving information from external knowledge resources has been proven as a promising solution to mitigate hallucinations.However, the retrieval augmentation in LVLM significantly lags behind the widespread applications of LVLM. Moreover, when transferred to augmenting LVLMs, sometimes the hallucination degree of the model is even exacerbated.Motivated by the research gap and counter-intuitive phenomenon, we introduce a novel framework, the Active Retrieval-Augmented large vision-language model (ARA), specifically designed to address hallucinations by incorporating three critical dimensions: (i) dissecting the retrieval targets based on the inherent hierarchical structures of images. (ii) pinpointing the most effective retrieval methods and filtering out the reliable retrieval results. (iii) timing the retrieval process to coincide with episodes of low certainty, while circumventing unnecessary retrieval during periods of high certainty. To assess the capability of our proposed ARA model in reducing hallucination, we employ three widely used LVLM models (LLaVA-1.5, Qwen-VL, and mPLUG-Owl2) across four benchmarks. Our empirical observations suggest that by utilizing fitting retrieval mechanisms and timing the retrieval judiciously, we can effectively mitigate the hallucination problem. We hope that this study can provide deeper insights into how to adapt the retrieval augmentation to LVLMs for reducing hallucinations with more effective retrieval and minimal retrieval occurrences.