 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Adaptive Masked Reconstruction for Self-Supervised Skeleton-Based Action Recognition
Jun 09, 2026Recently, masked skeleton reconstruction models have emerged as strong action representation learners, driving significant progress in self-supervised skeleton-based action recognition. However, existing state-of-the-art methods must predict an exceedingly large number of spatiotemporal patches, significantly prolonging training time. Besides, by treating all spatiotemporal regions equally during reconstruction, these models are distracted from learning the critical motion patterns that underlie action semantics. To address these challenges, we propose Adaptive Masked Reconstruction (AMR), a faster and stronger pre-training framework. We first decouple the decoder from the encoder, enabling flexible prediction of larger spatiotemporal patches and dramatically reducing reconstruction complexity. Given that larger patches contain more complex information, which is challenging to predict and consequently degrades performance, we accordingly introduce an adaptive guidance module. This module identifies regions of high motion informativeness, guiding the model to focus on the most discriminative parts of each patch and alleviating reconstruction difficulty. Experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets demonstrate that AMR not only accelerates pre-training substantially but also improves downstream recognition accuracy, surpassing current state-of-the-art approaches.
Not All Inputs Are Valid: Towards Open-Set Video Moment Retrieval Using Language
May 28, 2026Video Moment Retrieval (VMR) targets to retrieve the specific moment corresponding to a sentence query from an untrimmed video. Although recent works have made remarkable progress in this task, they implicitly are rooted in the closed-set assumption that all the given queries as video-relevant\footnote{In this paper, we treat ``video-relevant query'' as ``in-distribution (ID) query'' and ``video-irrelevant query'' as ``out-of-distribution (OOD) query''.}. Given an OOD query in open-set scenarios, they still utilize it for wrong retrieval, which might lead to irrecoverable losses in high-risk scenarios, \textit{e.g.}, criminal activity detection. To this end, we creatively explore a brand-new VMR setting termed Open-Set Video Moment Retrieval (OS-VMR), where we should not only retrieve the precise moments based on ID query, but also reject OOD queries. In this paper, we make the first attempt to step toward OS-VMR and propose a novel model \textbf{OpenVMR}, which first distinguishes ID and OOD queries based on the normalizing flow technology, and then conducts moment retrieval based on ID queries. Specifically, we first learn the ID distribution by constructing a normalizing flow, and assume the ID query distribution obeys the multi-variate Gaussian distribution. Then, we introduce an uncertainty score to search the ID-OOD separating boundary. After that, we refine the ID-OOD boundary by pulling together ID query features. Besides, video-query matching and frame-query matching are designed for coarse-grained and fine-grained cross-modal interaction, respectively. Finally, a positive-unlabeled learning module is introduced for moment retrieval. Experimental results on three VMR datasets show the effectiveness of our OpenVMR.
Rethinking Weakly-supervised Video Temporal Grounding From a Game Perspective
May 26, 2026This paper addresses the challenging task of weakly-supervised video temporal grounding. Existing approaches are generally based on the moment proposal selection framework that utilizes contrastive learning and reconstruction paradigm for scoring the pre-defined moment proposals. Although they have achieved significant progress, we argue that their current frameworks have overlooked two indispensable issues: 1) Coarse-grained cross-modal learning: previous methods solely capture the global video-level alignment with the query, failing to model the detailed consistency between video frames and query words for accurately grounding the moment boundaries. 2) Complex moment proposals: their performance severely relies on the quality of proposals, which are also time-consuming and complicated for selection. To this end, in this paper, we make the first attempt to tackle this task from a novel game perspective, which effectively learns the uncertain relationship between each vision-language pair with diverse granularity and flexible combination for multi-level cross-modal interaction.Specifically, we creatively model each video frame and query word as game players with multivariate cooperative game theory to learn their contribution to the cross-modal similarity score. By quantifying the trend of frame-word cooperation within a coalition via the game-theoretic interaction, we are able to value all uncertain but possible correspondence between frames and words. Finally, instead of using moment proposals, we utilize the learned query-guided frame-wise scores for better moment localization.Experiments show that our method achieves superior performance on both Charades-STA and ActivityNet Caption datasets.
Fundus-R1: Training a Fundus-Reading MLLM with Knowledge-Aware Reasoning on Public Data
Apr 09, 2026Fundus imaging such as CFP, OCT and UWF is crucial for the early detection of retinal anomalies and diseases. Fundus image understanding, due to its knowledge-intensive nature, poses a challenging vision-language task. An emerging approach to addressing the task is to post-train a generic multimodal large language model (MLLM), either by supervised finetuning (SFT) or by reinforcement learning with verifiable rewards (RLVR), on a considerable amount of in-house samples paired with high-quality clinical reports. However, these valuable samples are not publicly accessible, which not only hinders reproducibility but also practically limits research to few players. To overcome the barrier, we make a novel attempt to train a reasoning-enhanced fundus-reading MLLM, which we term Fundus-R1, using exclusively public datasets, wherein over 94\% of the data are annotated with only image-level labels. Our technical contributions are two-fold. First, we propose a RAG-based method for composing image-specific, knowledge-aware reasoning traces. Such auto-generated traces link visual findings identified by a generic MLLM to the image labels in terms of ophthalmic knowledge. Second, we enhance RLVR with a process reward that encourages self-consistency of the generated reasoning trace in each rollout. Extensive experiments on three fundus-reading benchmarks, i.e., FunBench, Omni-Fundus and GMAI-Fundus, show that Fundus-R1 clearly outperforms multiple baselines, including its generic counterpart (Qwen2.5-VL) and a stronger edition post-trained without using the generated traces. This work paves the way for training powerful fundus-reading MLLMs with publicly available data.
TSHA: A Benchmark for Visual Language Models in Trustworthy Safety Hazard Assessment Scenarios
Mar 31, 2026Recent advances in vision-language models (VLMs) have accelerated their application to indoor safety hazards assessment. However, existing benchmarks suffer from three fundamental limitations: (1) heavy reliance on synthetic datasets constructed via simulation software, creating a significant domain gap with real-world environments; (2) oversimplified safety tasks with artificial constraints on hazard and scene types, thereby limiting model generalization; and (3) absence of rigorous evaluation protocols to thoroughly assess model capabilities in complex home safety scenarios. To address these challenges, we introduce TSHA (\textbf{T}rustworthy \textbf{S}afety \textbf{H}azards \textbf{A}ssessment), a comprehensive benchmark comprising 81,809 carefully curated training samples drawn from four complementary sources: existing indoor datasets, internet images, AIGC images, and newly captured images. This benchmark set also includes a highly challenging test set with 1707 samples, comprising not only a carefully selected subset from the training distribution but also newly added videos and panoramic images containing multiple safety hazards, used to evaluate the model's robustness in complex safety scenarios. Extensive experiments on 23 popular VLMs demonstrate that current VLMs lack robust capabilities for safety hazard assessment. Importantly, models trained on the TSHA training set not only achieve a significant performance improvement of up to +18.3 points on the TSHA test set but also exhibit enhanced generalizability across other benchmarks, underscoring the substantial contribution and importance of the TSHA benchmark.
FashionMAC: Deformation-Free Fashion Image Generation with Fine-Grained Model Appearance Customization
Nov 18, 2025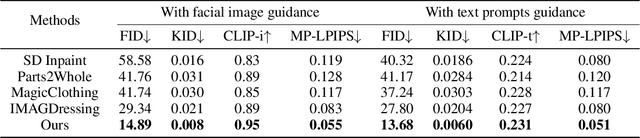
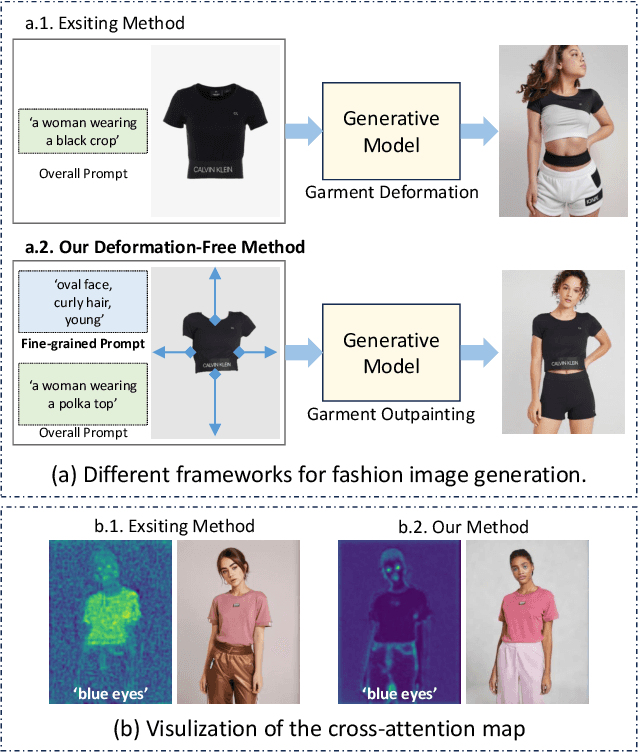

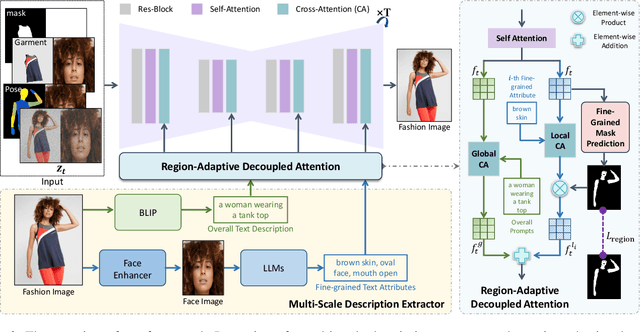
Garment-centric fashion image generation aims to synthesize realistic and controllable human models dressing a given garment, which has attracted growing interest due to its practical applications in e-commerce. The key challenges of the task lie in two aspects: (1) faithfully preserving the garment details, and (2) gaining fine-grained controllability over the model's appearance. Existing methods typically require performing garment deformation in the generation process, which often leads to garment texture distortions. Also, they fail to control the fine-grained attributes of the generated models, due to the lack of specifically designed mechanisms. To address these issues, we propose FashionMAC, a novel diffusion-based deformation-free framework that achieves high-quality and controllable fashion showcase image generation. The core idea of our framework is to eliminate the need for performing garment deformation and directly outpaint the garment segmented from a dressed person, which enables faithful preservation of the intricate garment details. Moreover, we propose a novel region-adaptive decoupled attention (RADA) mechanism along with a chained mask injection strategy to achieve fine-grained appearance controllability over the synthesized human models. Specifically, RADA adaptively predicts the generated regions for each fine-grained text attribute and enforces the text attribute to focus on the predicted regions by a chained mask injection strategy, significantly enhancing the visual fidelity and the controllability. Extensive experiments validate the superior performance of our framework compared to existing state-of-the-art methods.
Towards Efficient General Feature Prediction in Masked Skeleton Modeling
Sep 03, 2025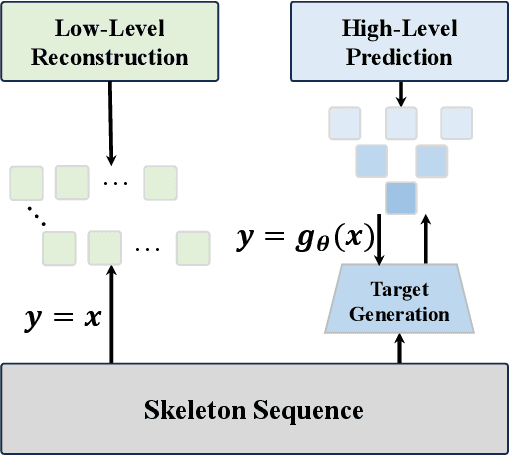
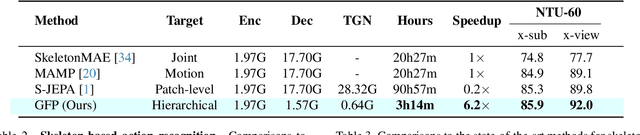
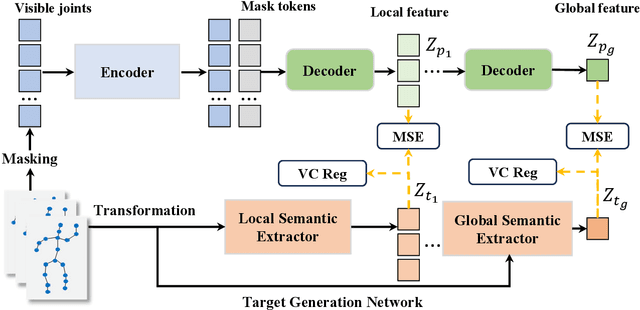
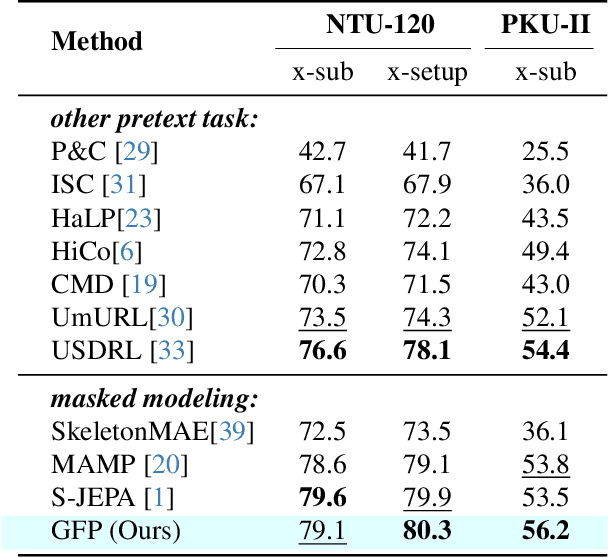
Recent advances in the masked autoencoder (MAE) paradigm have significantly propelled self-supervised skeleton-based action recognition. However, most existing approaches limit reconstruction targets to raw joint coordinates or their simple variants, resulting in computational redundancy and limited semantic representation. To address this, we propose a novel General Feature Prediction framework (GFP) for efficient mask skeleton modeling. Our key innovation is replacing conventional low-level reconstruction with high-level feature prediction that spans from local motion patterns to global semantic representations. Specifically, we introduce a collaborative learning framework where a lightweight target generation network dynamically produces diversified supervision signals across spatial-temporal hierarchies, avoiding reliance on pre-computed offline features. The framework incorporates constrained optimization to ensure feature diversity while preventing model collapse. Experiments on NTU RGB+D 60, NTU RGB+D 120 and PKU-MMD demonstrate the benefits of our approach: Computational efficiency (with 6.2$\times$ faster training than standard masked skeleton modeling methods) and superior representation quality, achieving state-of-the-art performance in various downstream tasks.
UW-3DGS: Underwater 3D Reconstruction with Physics-Aware Gaussian Splatting
Aug 08, 2025Underwater 3D scene reconstruction faces severe challenges from light absorption, scattering, and turbidity, which degrade geometry and color fidelity in traditional methods like Neural Radiance Fields (NeRF). While NeRF extensions such as SeaThru-NeRF incorporate physics-based models, their MLP reliance limits efficiency and spatial resolution in hazy environments. We introduce UW-3DGS, a novel framework adapting 3D Gaussian Splatting (3DGS) for robust underwater reconstruction. Key innovations include: (1) a plug-and-play learnable underwater image formation module using voxel-based regression for spatially varying attenuation and backscatter; and (2) a Physics-Aware Uncertainty Pruning (PAUP) branch that adaptively removes noisy floating Gaussians via uncertainty scoring, ensuring artifact-free geometry. The pipeline operates in training and rendering stages. During training, noisy Gaussians are optimized end-to-end with underwater parameters, guided by PAUP pruning and scattering modeling. In rendering, refined Gaussians produce clean Unattenuated Radiance Images (URIs) free from media effects, while learned physics enable realistic Underwater Images (UWIs) with accurate light transport. Experiments on SeaThru-NeRF and UWBundle datasets show superior performance, achieving PSNR of 27.604, SSIM of 0.868, and LPIPS of 0.104 on SeaThru-NeRF, with ~65% reduction in floating artifacts.
Rethinking Visual Layer Selection in Multimodal LLMs
Apr 30, 2025Multimodal large language models (MLLMs) have achieved impressive performance across a wide range of tasks, typically using CLIP-ViT as their visual encoder due to its strong text-image alignment capabilities. While prior studies suggest that different CLIP-ViT layers capture different types of information, with shallower layers focusing on fine visual details and deeper layers aligning more closely with textual semantics, most MLLMs still select visual features based on empirical heuristics rather than systematic analysis. In this work, we propose a Layer-wise Representation Similarity approach to group CLIP-ViT layers with similar behaviors into {shallow, middle, and deep} categories and assess their impact on MLLM performance. Building on this foundation, we revisit the visual layer selection problem in MLLMs at scale, training LLaVA-style models ranging from 1.4B to 7B parameters. Through extensive experiments across 10 datasets and 4 tasks, we find that: (1) deep layers are essential for OCR tasks; (2) shallow and middle layers substantially outperform deep layers on reasoning tasks involving counting, positioning, and object localization; (3) a lightweight fusion of features across shallow, middle, and deep layers consistently outperforms specialized fusion baselines and single-layer selections, achieving gains on 9 out of 10 datasets. Our work offers the first principled study of visual layer selection in MLLMs, laying the groundwork for deeper investigations into visual representation learning for MLLMs.
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Mar 03, 2025In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model's appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.