 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDFFDNet: Towards Accurate and Efficient Unsupervised Multi-Grid Image Registration
Sep 09, 2025Previous deep image registration methods that employ single homography, multi-grid homography, or thin-plate spline often struggle with real scenes containing depth disparities due to their inherent limitations. To address this, we propose an Exponential-Decay Free-Form Deformation Network (EDFFDNet), which employs free-form deformation with an exponential-decay basis function. This design achieves higher efficiency and performs well in scenes with depth disparities, benefiting from its inherent locality. We also introduce an Adaptive Sparse Motion Aggregator (ASMA), which replaces the MLP motion aggregator used in previous methods. By transforming dense interactions into sparse ones, ASMA reduces parameters and improves accuracy. Additionally, we propose a progressive correlation refinement strategy that leverages global-local correlation patterns for coarse-to-fine motion estimation, further enhancing efficiency and accuracy. Experiments demonstrate that EDFFDNet reduces parameters, memory, and total runtime by 70.5%, 32.6%, and 33.7%, respectively, while achieving a 0.5 dB PSNR gain over the state-of-the-art method. With an additional local refinement stage,EDFFDNet-2 further improves PSNR by 1.06 dB while maintaining lower computational costs. Our method also demonstrates strong generalization ability across datasets, outperforming previous deep learning methods.
Representation Alignment Contrastive Regularization for Multi-Object Tracking
Apr 03, 2024Achieving high-performance in multi-object tracking algorithms heavily relies on modeling spatio-temporal relationships during the data association stage. Mainstream approaches encompass rule-based and deep learning-based methods for spatio-temporal relationship modeling. While the former relies on physical motion laws, offering wider applicability but yielding suboptimal results for complex object movements, the latter, though achieving high-performance, lacks interpretability and involves complex module designs. This work aims to simplify deep learning-based spatio-temporal relationship models and introduce interpretability into features for data association. Specifically, a lightweight single-layer transformer encoder is utilized to model spatio-temporal relationships. To make features more interpretative, two contrastive regularization losses based on representation alignment are proposed, derived from spatio-temporal consistency rules. By applying weighted summation to affinity matrices, the aligned features can seamlessly integrate into the data association stage of the original tracking workflow. Experimental results showcase that our model enhances the majority of existing tracking networks' performance without excessive complexity, with minimal increase in training overhead and nearly negligible computational and storage costs.
Hierarchical Contrast for Unsupervised Skeleton-based Action Representation Learning
Dec 05, 2022This paper targets unsupervised skeleton-based action representation learning and proposes a new Hierarchical Contrast (HiCo) framework. Different from the existing contrastive-based solutions that typically represent an input skeleton sequence into instance-level features and perform contrast holistically, our proposed HiCo represents the input into multiple-level features and performs contrast in a hierarchical manner. Specifically, given a human skeleton sequence, we represent it into multiple feature vectors of different granularities from both temporal and spatial domains via sequence-to-sequence (S2S) encoders and unified downsampling modules. Besides, the hierarchical contrast is conducted in terms of four levels: instance level, domain level, clip level, and part level. Moreover, HiCo is orthogonal to the S2S encoder, which allows us to flexibly embrace state-of-the-art S2S encoders. Extensive experiments on four datasets, i.e., NTU-60, NTU-120, PKU-MMD I and II, show that HiCo achieves a new state-of-the-art for unsupervised skeleton-based action representation learning in two downstream tasks including action recognition and retrieval, and its learned action representation is of good transferability. Besides, we also show that our framework is effective for semi-supervised skeleton-based action recognition. Our code is available at https://github.com/HuiGuanLab/HiCo.
Partially Relevant Video Retrieval
Aug 26, 2022
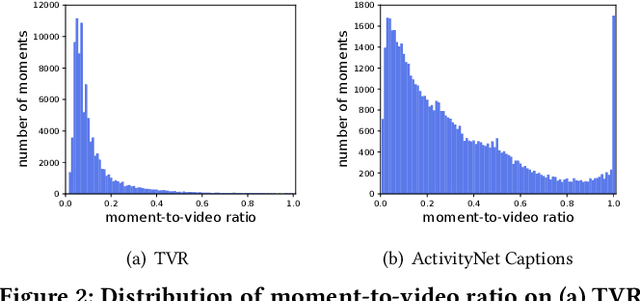
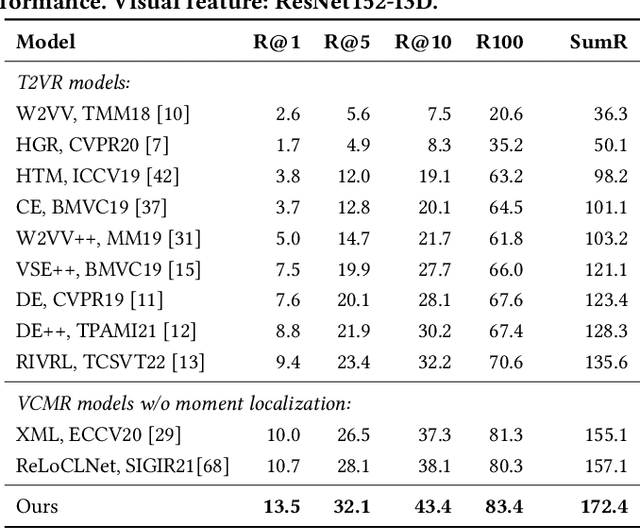
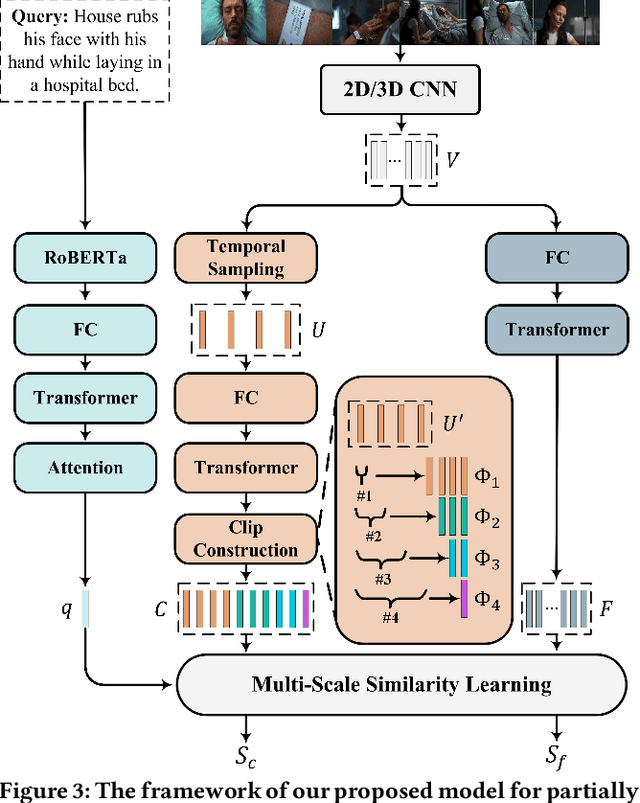
Current methods for text-to-video retrieval (T2VR) are trained and tested on video-captioning oriented datasets such as MSVD, MSR-VTT and VATEX. A key property of these datasets is that videos are assumed to be temporally pre-trimmed with short duration, whilst the provided captions well describe the gist of the video content. Consequently, for a given paired video and caption, the video is supposed to be fully relevant to the caption. In reality, however, as queries are not known a priori, pre-trimmed video clips may not contain sufficient content to fully meet the query. This suggests a gap between the literature and the real world. To fill the gap, we propose in this paper a novel T2VR subtask termed Partially Relevant Video Retrieval (PRVR). An untrimmed video is considered to be partially relevant w.r.t. a given textual query if it contains a moment relevant to the query. PRVR aims to retrieve such partially relevant videos from a large collection of untrimmed videos. PRVR differs from single video moment retrieval and video corpus moment retrieval, as the latter two are to retrieve moments rather than untrimmed videos. We formulate PRVR as a multiple instance learning (MIL) problem, where a video is simultaneously viewed as a bag of video clips and a bag of video frames. Clips and frames represent video content at different time scales. We propose a Multi-Scale Similarity Learning (MS-SL) network that jointly learns clip-scale and frame-scale similarities for PRVR. Extensive experiments on three datasets (TVR, ActivityNet Captions, and Charades-STA) demonstrate the viability of the proposed method. We also show that our method can be used for improving video corpus moment retrieval.