 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERHallu: Evaluating and Mitigating Event Relation Hallucination in Video Large Language Models
Jan 15, 2026Video Large Language Models (VideoLLMs) exhibit various types of hallucinations. Existing research has primarily focused on hallucinations involving the presence of events, objects, and scenes in videos, while largely neglecting event relation hallucination. In this paper, we introduce a novel benchmark for evaluating the Video Event Relation Hallucination, named VERHallu. This benchmark focuses on causal, temporal, and subevent relations between events, encompassing three types of tasks: relation classification, question answering, and counterfactual question answering, for a comprehensive evaluation of event relation hallucination. Additionally, it features counterintuitive video scenarios that deviate from typical pretraining distributions, with each sample accompanied by human-annotated candidates covering both vision-language and pure language biases. Our analysis reveals that current state-of-the-art VideoLLMs struggle with dense-event relation reasoning, often relying on prior knowledge due to insufficient use of frame-level cues. Although these models demonstrate strong grounding capabilities for key events, they often overlook the surrounding subevents, leading to an incomplete and inaccurate understanding of event relations. To tackle this, we propose a Key-Frame Propagating (KFP) strategy, which reallocates frame-level attention within intermediate layers to enhance multi-event understanding. Experiments show it effectively mitigates the event relation hallucination without affecting inference speed.
Towards Efficient General Feature Prediction in Masked Skeleton Modeling
Sep 03, 2025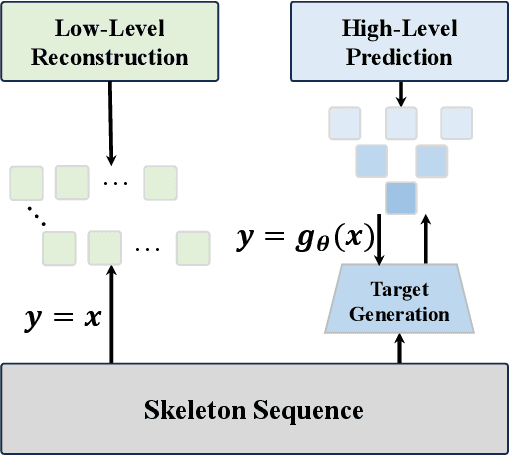
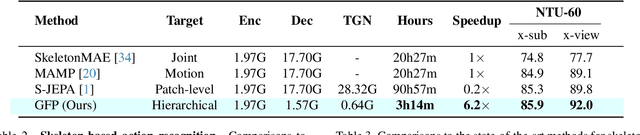
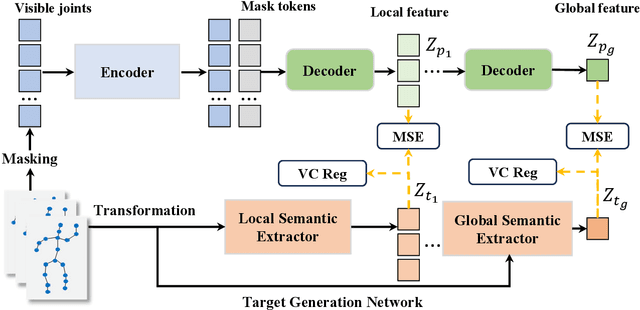
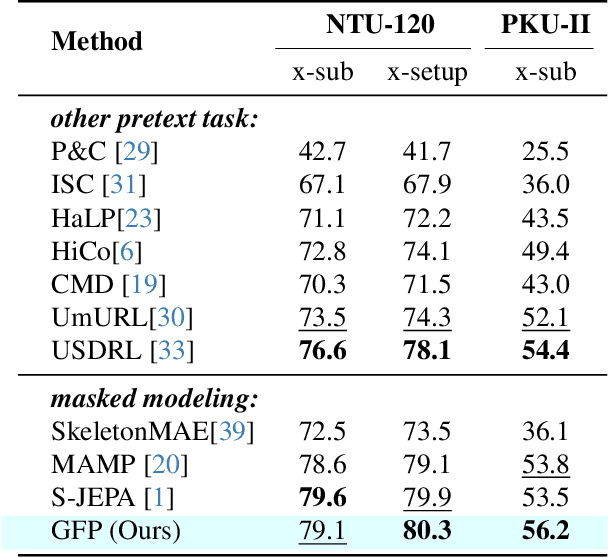
Recent advances in the masked autoencoder (MAE) paradigm have significantly propelled self-supervised skeleton-based action recognition. However, most existing approaches limit reconstruction targets to raw joint coordinates or their simple variants, resulting in computational redundancy and limited semantic representation. To address this, we propose a novel General Feature Prediction framework (GFP) for efficient mask skeleton modeling. Our key innovation is replacing conventional low-level reconstruction with high-level feature prediction that spans from local motion patterns to global semantic representations. Specifically, we introduce a collaborative learning framework where a lightweight target generation network dynamically produces diversified supervision signals across spatial-temporal hierarchies, avoiding reliance on pre-computed offline features. The framework incorporates constrained optimization to ensure feature diversity while preventing model collapse. Experiments on NTU RGB+D 60, NTU RGB+D 120 and PKU-MMD demonstrate the benefits of our approach: Computational efficiency (with 6.2$\times$ faster training than standard masked skeleton modeling methods) and superior representation quality, achieving state-of-the-art performance in various downstream tasks.
Unified Multi-modal Unsupervised Representation Learning for Skeleton-based Action Understanding
Nov 06, 2023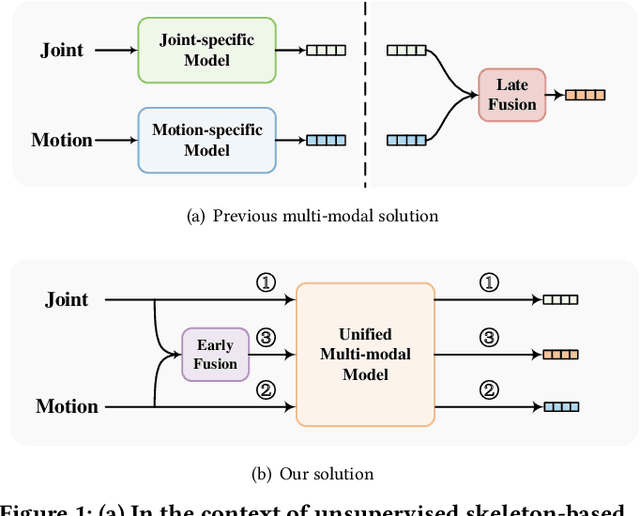
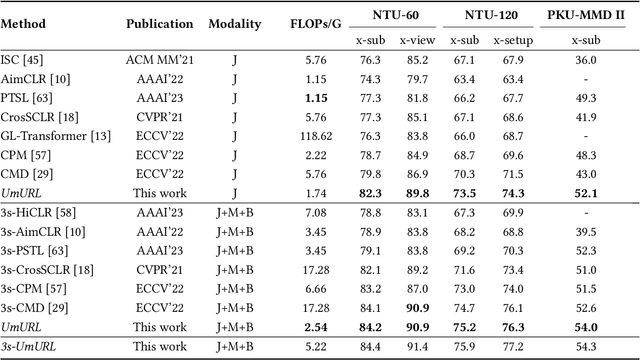
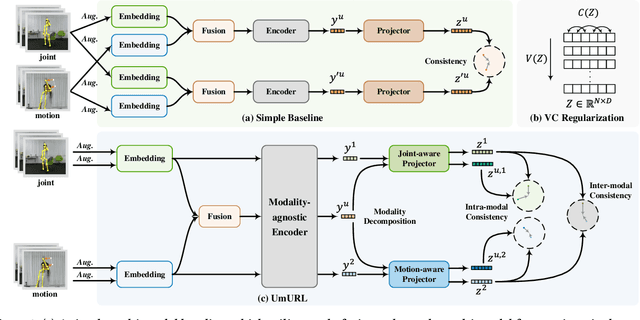
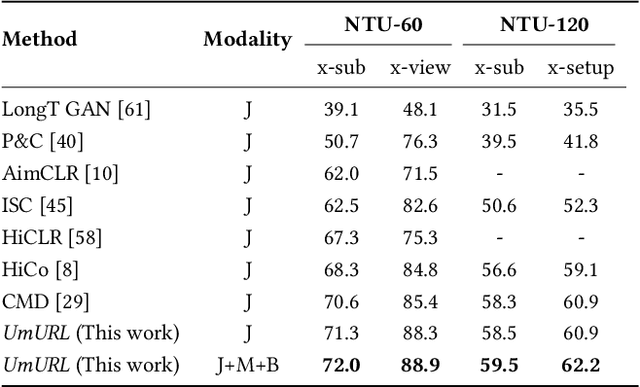
Unsupervised pre-training has shown great success in skeleton-based action understanding recently. Existing works typically train separate modality-specific models, then integrate the multi-modal information for action understanding by a late-fusion strategy. Although these approaches have achieved significant performance, they suffer from the complex yet redundant multi-stream model designs, each of which is also limited to the fixed input skeleton modality. To alleviate these issues, in this paper, we propose a Unified Multimodal Unsupervised Representation Learning framework, called UmURL, which exploits an efficient early-fusion strategy to jointly encode the multi-modal features in a single-stream manner. Specifically, instead of designing separate modality-specific optimization processes for uni-modal unsupervised learning, we feed different modality inputs into the same stream with an early-fusion strategy to learn their multi-modal features for reducing model complexity. To ensure that the fused multi-modal features do not exhibit modality bias, i.e., being dominated by a certain modality input, we further propose both intra- and inter-modal consistency learning to guarantee that the multi-modal features contain the complete semantics of each modal via feature decomposition and distinct alignment. In this manner, our framework is able to learn the unified representations of uni-modal or multi-modal skeleton input, which is flexible to different kinds of modality input for robust action understanding in practical cases. Extensive experiments conducted on three large-scale datasets, i.e., NTU-60, NTU-120, and PKU-MMD II, demonstrate that UmURL is highly efficient, possessing the approximate complexity with the uni-modal methods, while achieving new state-of-the-art performance across various downstream task scenarios in skeleton-based action representation learning.
Hierarchical Contrast for Unsupervised Skeleton-based Action Representation Learning
Dec 05, 2022This paper targets unsupervised skeleton-based action representation learning and proposes a new Hierarchical Contrast (HiCo) framework. Different from the existing contrastive-based solutions that typically represent an input skeleton sequence into instance-level features and perform contrast holistically, our proposed HiCo represents the input into multiple-level features and performs contrast in a hierarchical manner. Specifically, given a human skeleton sequence, we represent it into multiple feature vectors of different granularities from both temporal and spatial domains via sequence-to-sequence (S2S) encoders and unified downsampling modules. Besides, the hierarchical contrast is conducted in terms of four levels: instance level, domain level, clip level, and part level. Moreover, HiCo is orthogonal to the S2S encoder, which allows us to flexibly embrace state-of-the-art S2S encoders. Extensive experiments on four datasets, i.e., NTU-60, NTU-120, PKU-MMD I and II, show that HiCo achieves a new state-of-the-art for unsupervised skeleton-based action representation learning in two downstream tasks including action recognition and retrieval, and its learned action representation is of good transferability. Besides, we also show that our framework is effective for semi-supervised skeleton-based action recognition. Our code is available at https://github.com/HuiGuanLab/HiCo.