 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReparameterization Flow Policy Optimization
Feb 03, 2026Reparameterization Policy Gradient (RPG) has emerged as a powerful paradigm for model-based reinforcement learning, enabling high sample efficiency by backpropagating gradients through differentiable dynamics. However, prior RPG approaches have been predominantly restricted to Gaussian policies, limiting their performance and failing to leverage recent advances in generative models. In this work, we identify that flow policies, which generate actions via differentiable ODE integration, naturally align with the RPG framework, a connection not established in prior work. However, naively exploiting this synergy proves ineffective, often suffering from training instability and a lack of exploration. We propose Reparameterization Flow Policy Optimization (RFO). RFO computes policy gradients by backpropagating jointly through the flow generation process and system dynamics, unlocking high sample efficiency without requiring intractable log-likelihood calculations. RFO includes two tailored regularization terms for stability and exploration. We also propose a variant of RFO with action chunking. Extensive experiments on diverse locomotion and manipulation tasks, involving both rigid and soft bodies with state or visual inputs, demonstrate the effectiveness of RFO. Notably, on a challenging locomotion task controlling a soft-body quadruped, RFO achieves almost $2\times$ the reward of the state-of-the-art baseline.
AgenticTCAD: A LLM-based Multi-Agent Framework for Automated TCAD Code Generation and Device Optimization
Dec 26, 2025With the continued scaling of advanced technology nodes, the design-technology co-optimization (DTCO) paradigm has become increasingly critical, rendering efficient device design and optimization essential. In the domain of TCAD simulation, however, the scarcity of open-source resources hinders language models from generating valid TCAD code. To overcome this limitation, we construct an open-source TCAD dataset curated by experts and fine-tune a domain-specific model for TCAD code generation. Building on this foundation, we propose AgenticTCAD, a natural language - driven multi-agent framework that enables end-to-end automated device design and optimization. Validation on a 2 nm nanosheet FET (NS-FET) design shows that AgenticTCAD achieves the International Roadmap for Devices and Systems (IRDS)-2024 device specifications within 4.2 hours, whereas human experts required 7.1 days with commercial tools.
FashionMAC: Deformation-Free Fashion Image Generation with Fine-Grained Model Appearance Customization
Nov 18, 2025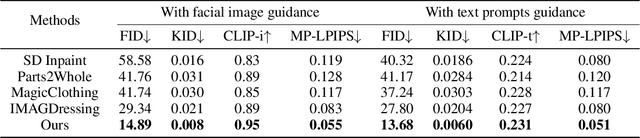
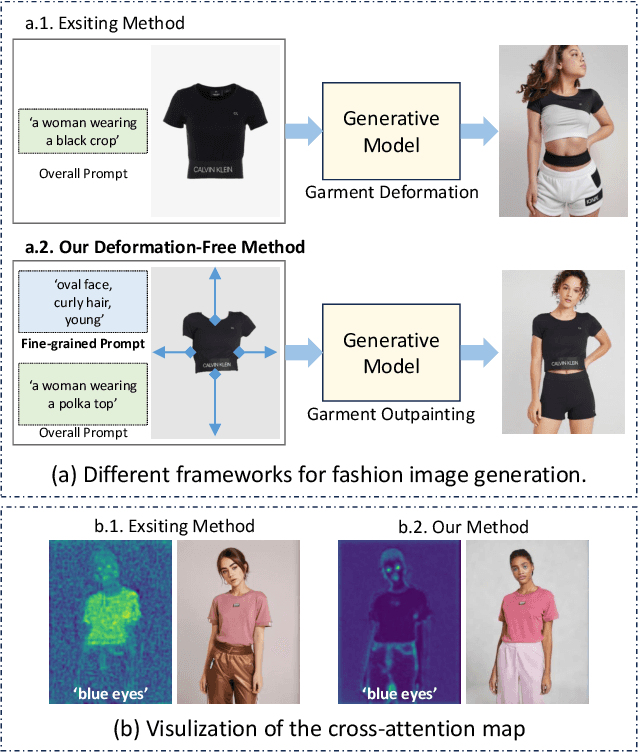

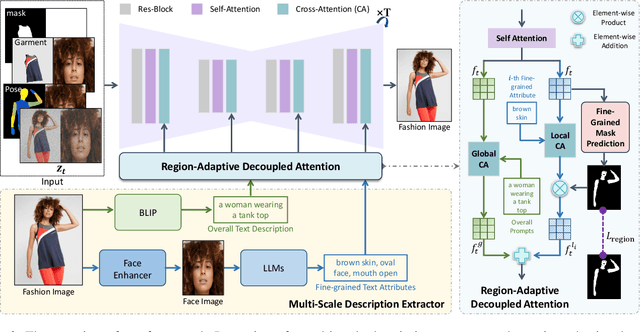
Garment-centric fashion image generation aims to synthesize realistic and controllable human models dressing a given garment, which has attracted growing interest due to its practical applications in e-commerce. The key challenges of the task lie in two aspects: (1) faithfully preserving the garment details, and (2) gaining fine-grained controllability over the model's appearance. Existing methods typically require performing garment deformation in the generation process, which often leads to garment texture distortions. Also, they fail to control the fine-grained attributes of the generated models, due to the lack of specifically designed mechanisms. To address these issues, we propose FashionMAC, a novel diffusion-based deformation-free framework that achieves high-quality and controllable fashion showcase image generation. The core idea of our framework is to eliminate the need for performing garment deformation and directly outpaint the garment segmented from a dressed person, which enables faithful preservation of the intricate garment details. Moreover, we propose a novel region-adaptive decoupled attention (RADA) mechanism along with a chained mask injection strategy to achieve fine-grained appearance controllability over the synthesized human models. Specifically, RADA adaptively predicts the generated regions for each fine-grained text attribute and enforces the text attribute to focus on the predicted regions by a chained mask injection strategy, significantly enhancing the visual fidelity and the controllability. Extensive experiments validate the superior performance of our framework compared to existing state-of-the-art methods.
End-to-End Multi-Person Pose Estimation with Pose-Aware Video Transformer
Nov 17, 2025Existing multi-person video pose estimation methods typically adopt a two-stage pipeline: detecting individuals in each frame, followed by temporal modeling for single-person pose estimation. This design relies on heuristic operations such as detection, RoI cropping, and non-maximum suppression (NMS), limiting both accuracy and efficiency. In this paper, we present a fully end-to-end framework for multi-person 2D pose estimation in videos, effectively eliminating heuristic operations. A key challenge is to associate individuals across frames under complex and overlapping temporal trajectories. To address this, we introduce a novel Pose-Aware Video transformEr Network (PAVE-Net), which features a spatial encoder to model intra-frame relations and a spatiotemporal pose decoder to capture global dependencies across frames. To achieve accurate temporal association, we propose a pose-aware attention mechanism that enables each pose query to selectively aggregate features corresponding to the same individual across consecutive frames.Additionally, we explicitly model spatiotemporal dependencies among pose keypoints to improve accuracy. Notably, our approach is the first end-to-end method for multi-frame 2D human pose estimation.Extensive experiments show that PAVE-Net substantially outperforms prior image-based end-to-end methods, achieving a \textbf{6.0} mAP improvement on PoseTrack2017, and delivers accuracy competitive with state-of-the-art two-stage video-based approaches, while offering significant gains in efficiency.Project page: https://github.com/zgspose/PAVENet
Complex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
OM2P: Offline Multi-Agent Mean-Flow Policy
Aug 08, 2025Generative models, especially diffusion and flow-based models, have been promising in offline multi-agent reinforcement learning. However, integrating powerful generative models into this framework poses unique challenges. In particular, diffusion and flow-based policies suffer from low sampling efficiency due to their iterative generation processes, making them impractical in time-sensitive or resource-constrained settings. To tackle these difficulties, we propose OM2P (Offline Multi-Agent Mean-Flow Policy), a novel offline MARL algorithm to achieve efficient one-step action sampling. To address the misalignment between generative objectives and reward maximization, we introduce a reward-aware optimization scheme that integrates a carefully-designed mean-flow matching loss with Q-function supervision. Additionally, we design a generalized timestep distribution and a derivative-free estimation strategy to reduce memory overhead and improve training stability. Empirical evaluations on Multi-Agent Particle and MuJoCo benchmarks demonstrate that OM2P achieves superior performance, with up to a 3.8x reduction in GPU memory usage and up to a 10.8x speed-up in training time. Our approach represents the first to successfully integrate mean-flow model into offline MARL, paving the way for practical and scalable generative policies in cooperative multi-agent settings.
Reparameterization Proximal Policy Optimization
Aug 08, 2025



Reparameterization policy gradient (RPG) is promising for improving sample efficiency by leveraging differentiable dynamics. However, a critical barrier is its training instability, where high-variance gradients can destabilize the learning process. To address this, we draw inspiration from Proximal Policy Optimization (PPO), which uses a surrogate objective to enable stable sample reuse in the model-free setting. We first establish a connection between this surrogate objective and RPG, which has been largely unexplored and is non-trivial. Then, we bridge this gap by demonstrating that the reparameterization gradient of a PPO-like surrogate objective can be computed efficiently using backpropagation through time. Based on this key insight, we propose Reparameterization Proximal Policy Optimization (RPO), a stable and sample-efficient RPG-based method. RPO enables multiple epochs of stable sample reuse by optimizing a clipped surrogate objective tailored for RPG, while being further stabilized by Kullback-Leibler (KL) divergence regularization and remaining fully compatible with existing variance reduction methods. We evaluate RPO on a suite of challenging locomotion and manipulation tasks, where experiments demonstrate that our method achieves superior sample efficiency and strong performance.
A Memetic Walrus Algorithm with Expert-guided Strategy for Adaptive Curriculum Sequencing
Jun 16, 2025Adaptive Curriculum Sequencing (ACS) is essential for personalized online learning, yet current approaches struggle to balance complex educational constraints and maintain optimization stability. This paper proposes a Memetic Walrus Optimizer (MWO) that enhances optimization performance through three key innovations: (1) an expert-guided strategy with aging mechanism that improves escape from local optima; (2) an adaptive control signal framework that dynamically balances exploration and exploitation; and (3) a three-tier priority mechanism for generating educationally meaningful sequences. We formulate ACS as a multi-objective optimization problem considering concept coverage, time constraints, and learning style compatibility. Experiments on the OULAD dataset demonstrate MWO's superior performance, achieving 95.3% difficulty progression rate (compared to 87.2% in baseline methods) and significantly better convergence stability (standard deviation of 18.02 versus 28.29-696.97 in competing algorithms). Additional validation on benchmark functions confirms MWO's robust optimization capability across diverse scenarios. The results demonstrate MWO's effectiveness in generating personalized learning sequences while maintaining computational efficiency and solution quality.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Proxy-Free GFlowNet
May 26, 2025Generative Flow Networks (GFlowNets) are a promising class of generative models designed to sample diverse, high-reward structures by modeling distributions over compositional objects. In many real-world applications, obtaining the reward function for such objects is expensive, time-consuming, or requires human input, making it necessary to train GFlowNets from historical datasets. Most existing methods adopt a model-based approach, learning a proxy model from the dataset to approximate the reward function. However, this strategy inherently ties the quality of the learned policy to the accuracy of the proxy, introducing additional complexity and uncertainty into the training process. To overcome these limitations, we propose \textbf{Trajectory-Distilled GFlowNet (TD-GFN)}, a \emph{proxy-free} training framework that eliminates the need for out-of-dataset reward queries. Our method is motivated by the key observation that different edges in the associated directed acyclic graph (DAG) contribute unequally to effective policy learning. TD-GFN leverages inverse reinforcement learning to estimate edge-level rewards from the offline dataset, which are then used to ingeniously prune the DAG and guide backward trajectory sampling during training. This approach directs the policy toward high-reward regions while reducing the complexity of model fitting. Empirical results across multiple tasks show that TD-GFN trains both efficiently and reliably, significantly outperforming existing baselines in convergence speed and sample quality.