 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
VIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
LLM-in-Sandbox Elicits General Agentic Intelligence
Jan 22, 2026We introduce LLM-in-Sandbox, enabling LLMs to explore within a code sandbox (i.e., a virtual computer), to elicit general intelligence in non-code domains. We first demonstrate that strong LLMs, without additional training, exhibit generalization capabilities to leverage the code sandbox for non-code tasks. For example, LLMs spontaneously access external resources to acquire new knowledge, leverage the file system to handle long contexts, and execute scripts to satisfy formatting requirements. We further show that these agentic capabilities can be enhanced through LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL), which uses only non-agentic data to train models for sandbox exploration. Experiments demonstrate that LLM-in-Sandbox, in both training-free and post-trained settings, achieves robust generalization spanning mathematics, physics, chemistry, biomedicine, long-context understanding, and instruction following. Finally, we analyze LLM-in-Sandbox's efficiency from computational and system perspectives, and open-source it as a Python package to facilitate real-world deployment.
Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge
Jan 13, 2026Large language models often solve complex reasoning tasks more effectively with Chain-of-Thought (CoT), but at the cost of long, low-bandwidth token sequences. Humans, by contrast, often reason softly by maintaining a distribution over plausible next steps. Motivated by this, we propose Multiplex Thinking, a stochastic soft reasoning mechanism that, at each thinking step, samples K candidate tokens and aggregates their embeddings into a single continuous multiplex token. This preserves the vocabulary embedding prior and the sampling dynamics of standard discrete generation, while inducing a tractable probability distribution over multiplex rollouts. Consequently, multiplex trajectories can be directly optimized with on-policy reinforcement learning (RL). Importantly, Multiplex Thinking is self-adaptive: when the model is confident, the multiplex token is nearly discrete and behaves like standard CoT; when it is uncertain, it compactly represents multiple plausible next steps without increasing sequence length. Across challenging math reasoning benchmarks, Multiplex Thinking consistently outperforms strong discrete CoT and RL baselines from Pass@1 through Pass@1024, while producing shorter sequences. The code and checkpoints are available at https://github.com/GMLR-Penn/Multiplex-Thinking.
Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Jan 12, 2026Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question-answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Black-Box On-Policy Distillation of Large Language Models
Nov 13, 2025Black-box distillation creates student large language models (LLMs) by learning from a proprietary teacher model's text outputs alone, without access to its internal logits or parameters. In this work, we introduce Generative Adversarial Distillation (GAD), which enables on-policy and black-box distillation. GAD frames the student LLM as a generator and trains a discriminator to distinguish its responses from the teacher LLM's, creating a minimax game. The discriminator acts as an on-policy reward model that co-evolves with the student, providing stable, adaptive feedback. Experimental results show that GAD consistently surpasses the commonly used sequence-level knowledge distillation. In particular, Qwen2.5-14B-Instruct (student) trained with GAD becomes comparable to its teacher, GPT-5-Chat, on the LMSYS-Chat automatic evaluation. The results establish GAD as a promising and effective paradigm for black-box LLM distillation.
The Era of Agentic Organization: Learning to Organize with Language Models
Oct 30, 2025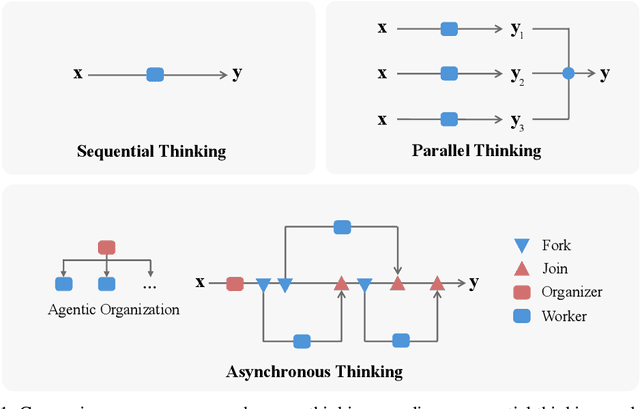

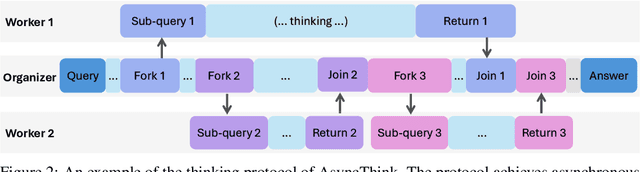
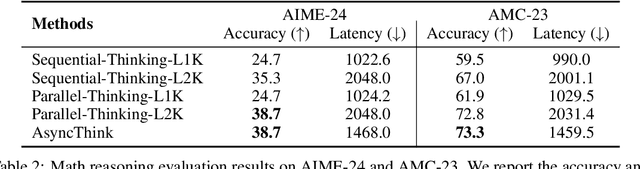
We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence. To realize this vision, we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with large language models, which organizes the internal thinking process into concurrently executable structures. Specifically, we propose a thinking protocol where an organizer dynamically assigns sub-queries to workers, merges intermediate knowledge, and produces coherent solutions. More importantly, the thinking structure in this protocol can be further optimized through reinforcement learning. Experiments demonstrate that AsyncThink achieves 28% lower inference latency compared to parallel thinking while improving accuracy on mathematical reasoning. Moreover, AsyncThink generalizes its learned asynchronous thinking capabilities, effectively tackling unseen tasks without additional training.
Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts
Oct 27, 2025Recent advances in reinforcement learning (RL) have substantially improved the training of large-scale language models, leading to significant gains in generation quality and reasoning ability. However, most existing research focuses on dense models, while RL training for Mixture-of-Experts (MoE) architectures remains underexplored. To address the instability commonly observed in MoE training, we propose a novel router-aware approach to optimize importance sampling (IS) weights in off-policy RL. Specifically, we design a rescaling strategy guided by router logits, which effectively reduces gradient variance and mitigates training divergence. Experimental results demonstrate that our method significantly improves both the convergence stability and the final performance of MoE models, highlighting the potential of RL algorithmic innovations tailored to MoE architectures and providing a promising direction for efficient training of large-scale expert models.
11Plus-Bench: Demystifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis
Aug 27, 2025For human cognitive process, spatial reasoning and perception are closely entangled, yet the nature of this interplay remains underexplored in the evaluation of multimodal large language models (MLLMs). While recent MLLM advancements show impressive performance on reasoning, their capacity for human-like spatial cognition remains an open question. In this work, we introduce a systematic evaluation framework to assess the spatial reasoning abilities of state-of-the-art MLLMs relative to human performance. Central to our work is 11Plus-Bench, a high-quality benchmark derived from realistic standardized spatial aptitude tests. 11Plus-Bench also features fine-grained expert annotations of both perceptual complexity and reasoning process, enabling detailed instance-level analysis of model behavior. Through extensive experiments across 14 MLLMs and human evaluation, we find that current MLLMs exhibit early signs of spatial cognition. Despite a large performance gap compared to humans, MLLMs' cognitive profiles resemble those of humans in that cognitive effort correlates strongly with reasoning-related complexity. However, instance-level performance in MLLMs remains largely random, whereas human correctness is highly predictable and shaped by abstract pattern complexity. These findings highlight both emerging capabilities and limitations in current MLLMs' spatial reasoning capabilities and provide actionable insights for advancing model design.
LongReasonArena: A Long Reasoning Benchmark for Large Language Models
Aug 26, 2025Existing long-context benchmarks for Large Language Models (LLMs) focus on evaluating comprehension of long inputs, while overlooking the evaluation of long reasoning abilities. To address this gap, we introduce LongReasonArena, a benchmark specifically designed to assess the long reasoning capabilities of LLMs. Our tasks require models to solve problems by executing multi-step algorithms that reflect key aspects of long reasoning, such as retrieval and backtracking. By controlling the inputs, the required reasoning length can be arbitrarily scaled, reaching up to 1 million tokens of reasoning for the most challenging tasks. Extensive evaluation results demonstrate that LongReasonArena presents a significant challenge for both open-source and proprietary LLMs. For instance, Deepseek-R1 achieves only 7.5% accuracy on our task. Further analysis also reveals that the accuracy exhibits a linear decline with respect to the logarithm of the expected number of reasoning steps. Our code and data is available at https://github.com/LongReasonArena/LongReasonArena.