 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Sensing and Covert Communication In Low-Altitude Networks: A Smart Radio Environment Perspective
Jun 01, 2026The rise of low-altitude economies and 6G is driving the evolution of low-altitude networks (LANs), making communication security a pressing concern. Unlike traditional security approaches, covert communication offers enhanced protection by hiding the transmission behavior itself. Integrated sensing and communication (ISAC), a key technology of 6G, efficiently supports both sensing and communication tasks through hardware integration, thereby promising significant gains for covert communication. Nevertheless, the complexity and dynamics of urban environments pose critical challenges. Drawing on the latest advances in smart radio environment (SRE) technologies, this paper introduces them into integrated sensing and covert communication (ISACC) to suppress covert channel fading and counteract sensing precision loss in LANs. We first survey the applications and state-of-the-art findings of ISACC in LANs, highlighting key practical challenges. Subsequently, we introduce the core concept of SRE and elaborate on its enabling techniques across four dimensions. To deliver more insights, we explore potential pathways for integrating SRE into ISACC. To maximize covert throughput, a reinforcement learning-based case study is conducted by jointly optimizing flight trajectory, jamming power, movable antenna position, bandwidth allocation, and beamforming vectors. Simulation results show that the proposed scheme achieves superior performance compared to the benchmark. Finally, some open challenges and potential directions are discussed.
HySparse: A Hybrid Sparse Attention Architecture with Oracle Token Selection and KV Cache Sharing
Feb 03, 2026This work introduces Hybrid Sparse Attention (HySparse), a new architecture that interleaves each full attention layer with several sparse attention layers. While conceptually simple, HySparse strategically derives each sparse layer's token selection and KV caches directly from the preceding full attention layer. This architecture resolves two fundamental limitations of prior sparse attention methods. First, conventional approaches typically rely on additional proxies to predict token importance, introducing extra complexity and potentially suboptimal performance. In contrast, HySparse uses the full attention layer as a precise oracle to identify important tokens. Second, existing sparse attention designs often reduce computation without saving KV cache. HySparse enables sparse attention layers to reuse the full attention KV cache, thereby reducing both computation and memory. We evaluate HySparse on both 7B dense and 80B MoE models. Across all settings, HySparse consistently outperforms both full attention and hybrid SWA baselines. Notably, in the 80B MoE model with 49 total layers, only 5 layers employ full attention, yet HySparse achieves substantial performance gains while reducing KV cache storage by nearly 10x.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Bitnet.cpp: Efficient Edge Inference for Ternary LLMs
Feb 17, 2025The advent of 1-bit large language models (LLMs), led by BitNet b1.58, has spurred interest in ternary LLMs. Despite this, research and practical applications focusing on efficient edge inference for ternary LLMs remain scarce. To bridge this gap, we introduce Bitnet.cpp, an inference system optimized for BitNet b1.58 and ternary LLMs. Given that mixed-precision matrix multiplication (mpGEMM) constitutes the bulk of inference time in ternary LLMs, Bitnet.cpp incorporates a novel mpGEMM library to facilitate sub-2-bits-per-weight, efficient and lossless inference. The library features two core solutions: Ternary Lookup Table (TL), which addresses spatial inefficiencies of previous bit-wise methods, and Int2 with a Scale (I2_S), which ensures lossless edge inference, both enabling high-speed inference. Our experiments show that Bitnet.cpp achieves up to a 6.25x increase in speed over full-precision baselines and up to 2.32x over low-bit baselines, setting new benchmarks in the field. Additionally, we expand TL to element-wise lookup table (ELUT) for low-bit LLMs in the appendix, presenting both theoretical and empirical evidence of its considerable potential. Bitnet.cpp is publicly available at https://github.com/microsoft/BitNet/tree/paper , offering a sophisticated solution for the efficient and practical deployment of edge LLMs.
LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration
Aug 12, 2024As large language model (LLM) inference demands ever-greater resources, there is a rapid growing trend of using low-bit weights to shrink memory usage and boost inference efficiency. However, these low-bit LLMs introduce the need for mixed-precision matrix multiplication (mpGEMM), which is a crucial yet under-explored operation that involves multiplying lower-precision weights with higher-precision activations. Unfortunately, current hardware does not natively support mpGEMM, resulting in indirect and inefficient dequantization-based implementations. To address the mpGEMM requirements in low-bit LLMs, we explored the lookup table (LUT)-based approach for mpGEMM. However, a conventional LUT implementation falls short of its potential. To fully harness the power of LUT-based mpGEMM, we introduce LUT Tensor Core, a software-hardware co-design optimized for low-bit LLM inference. Specifically, we introduce software-based operator fusion and table symmetrization techniques to optimize table precompute and table storage, respectively. Then, LUT Tensor Core proposes the hardware design featuring an elongated tiling shape design to enhance table reuse and a bit-serial design to support various precision combinations in mpGEMM. Moreover, we design an end-to-end compilation stack with new instructions for LUT-based mpGEMM, enabling efficient LLM compilation and optimizations. The evaluation on low-bit LLMs (e.g., BitNet, LLAMA) shows that LUT Tensor Core achieves more than a magnitude of improvements on both compute density and energy efficiency.
T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge
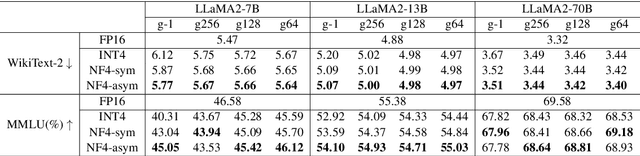
Jun 25, 2024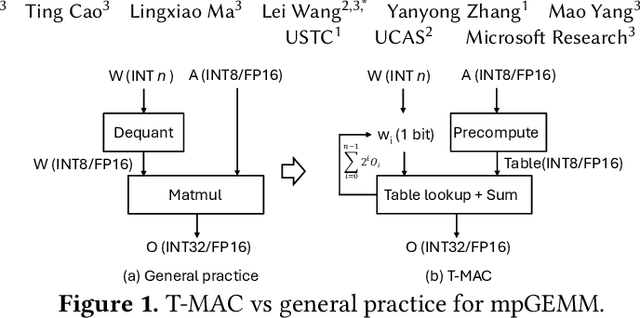

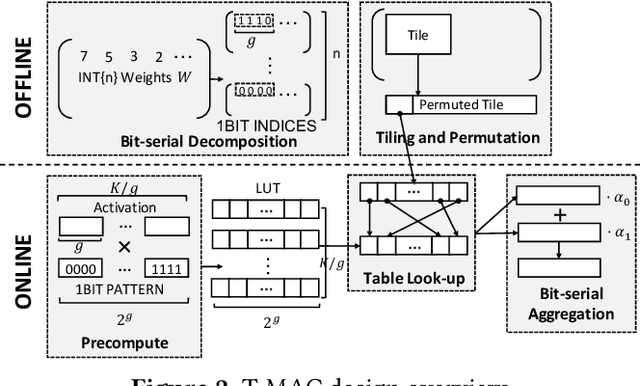

The deployment of Large Language Models (LLMs) on edge devices is increasingly important to enhance on-device intelligence. Weight quantization is crucial for reducing the memory footprint of LLMs on devices. However, low-bit LLMs necessitate mixed precision matrix multiplication (mpGEMM) of low precision weights and high precision activations during inference. Existing systems, lacking native support for mpGEMM, resort to dequantize weights for high precision computation. Such an indirect way can lead to a significant inference overhead. In this paper, we introduce T-MAC, an innovative lookup table(LUT)-based method designed for efficient low-bit LLM (i.e., weight-quantized LLM) inference on CPUs. T-MAC directly supports mpGEMM without dequantization, while simultaneously eliminating multiplications and reducing additions required. Specifically, T-MAC transforms the traditional data-type-centric multiplication to bit-wise table lookup, and enables a unified and scalable mpGEMM solution. Our LUT-based kernels scale linearly to the weight bit-width. Evaluated on low-bit Llama and BitNet models, T-MAC demonstrates up to 4x increase in throughput and 70% reduction in energy consumption compared to llama.cpp. For BitNet-b1.58-3B, T-MAC delivers a token generation throughput of 30 tokens/s with a single core and 71 tokens/s with eight cores on M2-Ultra, and 11 tokens/s on lower-end devices like Raspberry Pi 5, which significantly exceeds the adult average reading speed. T-MAC with LUT-based computing paradigm, paves the way for the practical deployment of low-bit LLMs on resource-constrained edge devices without compromising computational efficiency. The system is open-sourced at https://github.com/microsoft/T-MAC.
AFPQ: Asymmetric Floating Point Quantization for LLMs
Nov 03, 2023


Large language models (LLMs) show great performance in various tasks, but face deployment challenges from limited memory capacity and bandwidth. Low-bit weight quantization can save memory and accelerate inference. Although floating-point (FP) formats show good performance in LLM quantization, they tend to perform poorly with small group sizes or sub-4 bits. We find the reason is that the absence of asymmetry in previous FP quantization makes it unsuitable for handling asymmetric value distribution of LLM weight tensors. In this work, we propose asymmetric FP quantization (AFPQ), which sets separate scales for positive and negative values. Our method leads to large accuracy improvements and can be easily plugged into other quantization methods, including GPTQ and AWQ, for better performance. Besides, no additional storage is needed compared with asymmetric integer (INT) quantization. The code is available at https://github.com/zhangsichengsjtu/AFPQ.
Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference
Aug 23, 2023Large language models (LLMs) based on transformers have made significant strides in recent years, the success of which is driven by scaling up their model size. Despite their high algorithmic performance, the computational and memory requirements of LLMs present unprecedented challenges. To tackle the high compute requirements of LLMs, the Mixture-of-Experts (MoE) architecture was introduced which is able to scale its model size without proportionally scaling up its computational requirements. Unfortunately, MoE's high memory demands and dynamic activation of sparse experts restrict its applicability to real-world problems. Previous solutions that offload MoE's memory-hungry expert parameters to CPU memory fall short because the latency to migrate activated experts from CPU to GPU incurs high performance overhead. Our proposed Pre-gated MoE system effectively tackles the compute and memory challenges of conventional MoE architectures using our algorithm-system co-design. Pre-gated MoE employs our novel pre-gating function which alleviates the dynamic nature of sparse expert activation, allowing our proposed system to address the large memory footprint of MoEs while also achieving high performance. We demonstrate that Pre-gated MoE is able to improve performance, reduce GPU memory consumption, while also maintaining the same level of model quality. These features allow our Pre-gated MoE system to cost-effectively deploy large-scale LLMs using just a single GPU with high performance.