 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHySparse: A Hybrid Sparse Attention Architecture with Oracle Token Selection and KV Cache Sharing
Feb 03, 2026This work introduces Hybrid Sparse Attention (HySparse), a new architecture that interleaves each full attention layer with several sparse attention layers. While conceptually simple, HySparse strategically derives each sparse layer's token selection and KV caches directly from the preceding full attention layer. This architecture resolves two fundamental limitations of prior sparse attention methods. First, conventional approaches typically rely on additional proxies to predict token importance, introducing extra complexity and potentially suboptimal performance. In contrast, HySparse uses the full attention layer as a precise oracle to identify important tokens. Second, existing sparse attention designs often reduce computation without saving KV cache. HySparse enables sparse attention layers to reuse the full attention KV cache, thereby reducing both computation and memory. We evaluate HySparse on both 7B dense and 80B MoE models. Across all settings, HySparse consistently outperforms both full attention and hybrid SWA baselines. Notably, in the 80B MoE model with 49 total layers, only 5 layers employ full attention, yet HySparse achieves substantial performance gains while reducing KV cache storage by nearly 10x.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Rectified Sparse Attention
Jun 05, 2025Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
Awaker2.5-VL: Stably Scaling MLLMs with Parameter-Efficient Mixture of Experts
Nov 16, 2024As the research of Multimodal Large Language Models (MLLMs) becomes popular, an advancing MLLM model is typically required to handle various textual and visual tasks (e.g., VQA, Detection, OCR, and ChartQA) simultaneously for real-world applications. However, due to the significant differences in representation and distribution among data from various tasks, simply mixing data of all tasks together leads to the well-known``multi-task conflict" issue, resulting in performance degradation across various tasks. To address this issue, we propose Awaker2.5-VL, a Mixture of Experts~(MoE) architecture suitable for MLLM, which acquires the multi-task capabilities through multiple sparsely activated experts. To speed up the training and inference of Awaker2.5-VL, each expert in our model is devised as a low-rank adaptation (LoRA) structure. Extensive experiments on multiple latest benchmarks demonstrate the effectiveness of Awaker2.5-VL. The code and model weight are released in our Project Page: https://github.com/MetabrainAGI/Awaker.
SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs
Oct 17, 2024



Attention is the cornerstone of modern Large Language Models (LLMs). Yet its quadratic complexity limits the efficiency and scalability of LLMs, especially for those with a long-context window. A promising approach addressing this limitation is to leverage the sparsity in attention. However, existing sparsity-based solutions predominantly rely on predefined patterns or heuristics to approximate sparsity. This practice falls short to fully capture the dynamic nature of attention sparsity in language-based tasks. This paper argues that attention sparsity should be learned rather than predefined. To this end, we design SeerAttention, a new Attention mechanism that augments the conventional attention with a learnable gate that adaptively selects significant blocks in an attention map and deems the rest blocks sparse. Such block-level sparsity effectively balances accuracy and speedup. To enable efficient learning of the gating network, we develop a customized FlashAttention implementation that extracts the block-level ground truth of attention map with minimum overhead. SeerAttention not only applies to post-training, but also excels in long-context fine-tuning. Our results show that at post-training stages, SeerAttention significantly outperforms state-of-the-art static or heuristic-based sparse attention methods, while also being more versatile and flexible to adapt to varying context lengths and sparsity ratios. When applied to long-context fine-tuning with YaRN, SeerAttention can achieve a remarkable 90% sparsity ratio at a 32k context length with minimal perplexity loss, offering a 5.67x speedup over FlashAttention-2.
Co-designing a Sub-millisecond Latency Event-based Eye Tracking System with Submanifold Sparse CNN
Apr 22, 2024Eye-tracking technology is integral to numerous consumer electronics applications, particularly in the realm of virtual and augmented reality (VR/AR). These applications demand solutions that excel in three crucial aspects: low-latency, low-power consumption, and precision. Yet, achieving optimal performance across all these fronts presents a formidable challenge, necessitating a balance between sophisticated algorithms and efficient backend hardware implementations. In this study, we tackle this challenge through a synergistic software/hardware co-design of the system with an event camera. Leveraging the inherent sparsity of event-based input data, we integrate a novel sparse FPGA dataflow accelerator customized for submanifold sparse convolution neural networks (SCNN). The SCNN implemented on the accelerator can efficiently extract the embedding feature vector from each representation of event slices by only processing the non-zero activations. Subsequently, these vectors undergo further processing by a gated recurrent unit (GRU) and a fully connected layer on the host CPU to generate the eye centers. Deployment and evaluation of our system reveal outstanding performance metrics. On the Event-based Eye-Tracking-AIS2024 dataset, our system achieves 81% p5 accuracy, 99.5% p10 accuracy, and 3.71 Mean Euclidean Distance with 0.7 ms latency while only consuming 2.29 mJ per inference. Notably, our solution opens up opportunities for future eye-tracking systems. Code is available at https://github.com/CASR-HKU/ESDA/tree/eye_tracking.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024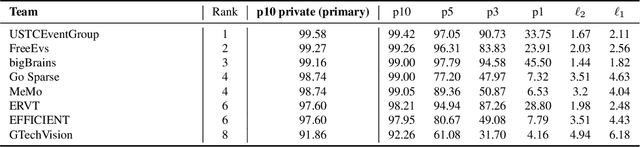
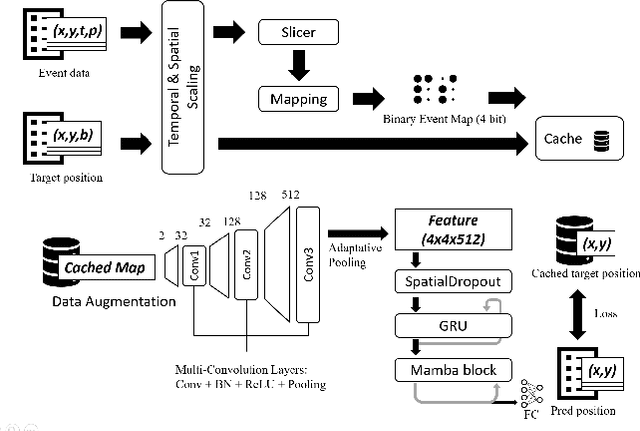
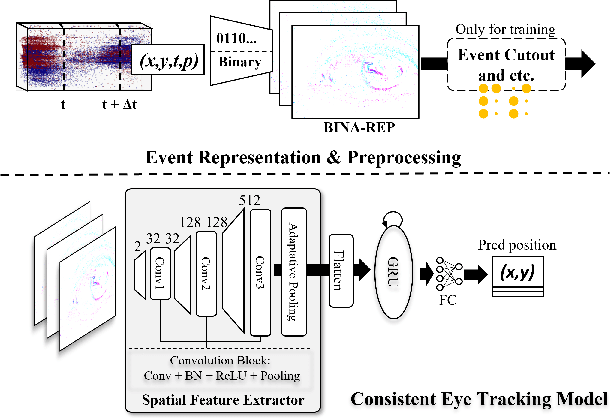

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023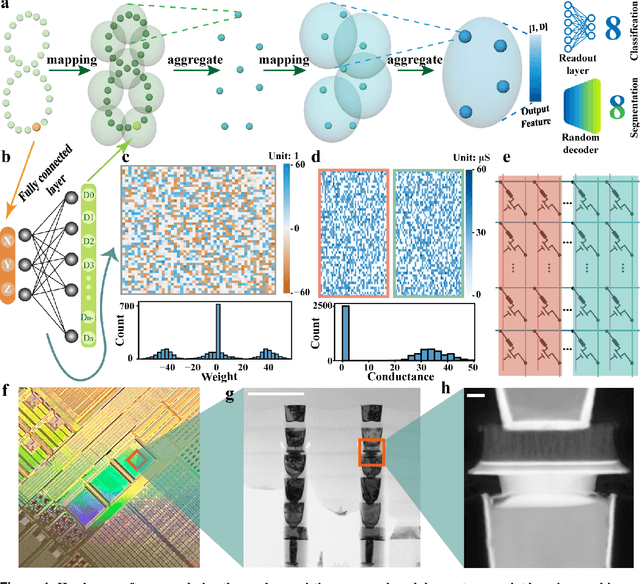
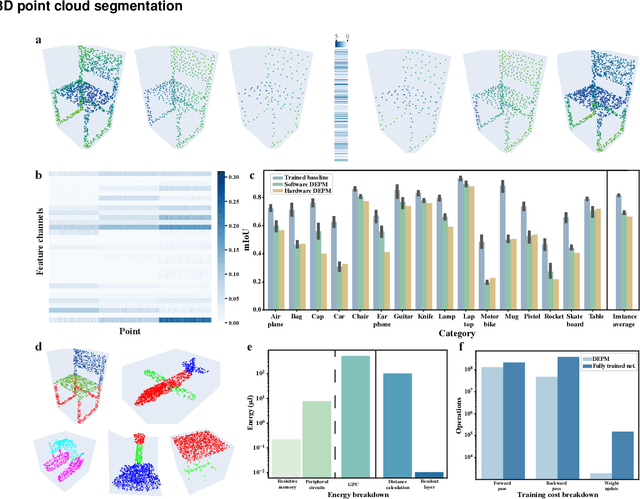
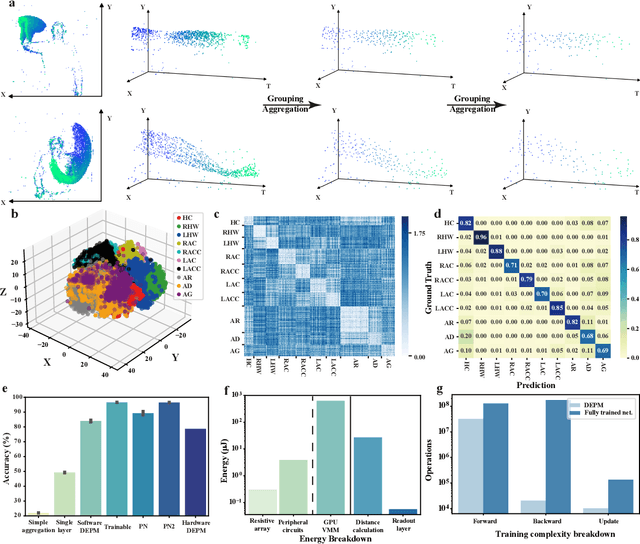
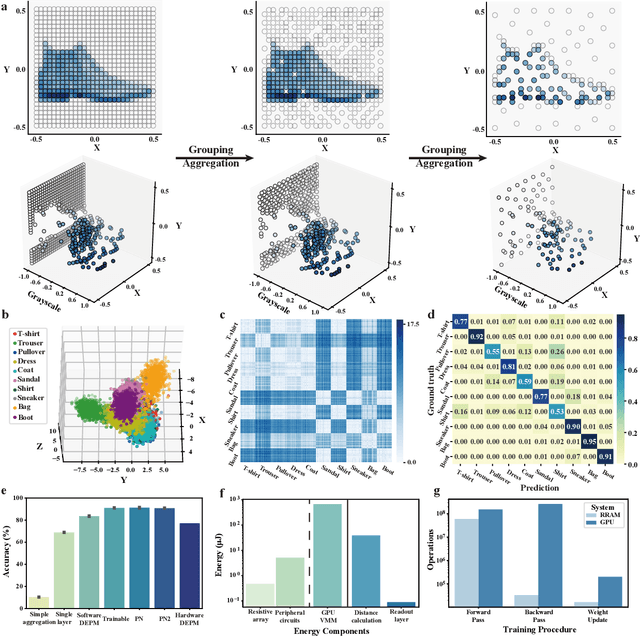
Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.