 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr.~RTL: Autonomous Agentic RTL Optimization through Tool-Grounded Self-Improvement
Apr 16, 2026Recent advances in large language models (LLMs) have sparked growing interest in automatic RTL optimization for better performance, power, and area (PPA). However, existing methods are still far from realistic RTL optimization. Their evaluation settings are often unrealistic: they are tested on manually degraded, small-scale RTL designs and rely on weak open-source tools. Their optimization methods are also limited, relying on coarse design-level feedback and simple pre-defined rewriting rules. To address these limitations, we present Dr. RTL, an agentic framework for RTL timing optimization in a realistic evaluation environment, with continual self-improvement through reusable optimization skills. We establish a realistic evaluation setting with more challenging RTL designs and an industrial EDA workflow. Within this setting, Dr. RTL performs closed-loop optimization through a multi-agent framework for critical-path analysis, parallel RTL rewriting, and tool-based evaluation. We further introduce group-relative skill learning, which compares parallel RTL rewrites and distills the optimization experience into an interpretable skill library. Currently, this library contains 47 pattern--strategy entries for cross-design reuse to improve PPA and accelerate convergence, and it can continue evolving over time. Evaluated on 20 real-world RTL designs, Dr. RTL achieves average WNS/TNS improvements of 21\%/17\% with a 6\% area reduction over the industry-leading commercial synthesis tool.
A 28nm 0.22 μJ/token memory-compute-intensity-aware CNN-Transformer accelerator with hybrid-attention-based layer-fusion and cascaded pruning for semanticsegmentation
Dec 19, 2025This work presents a 28nm 13.93mm2 CNN-Transformer accelerator for semantic segmentation, achieving 3.86-to-10.91x energy reduction over previous designs. It features a hybrid attention unit, layer-fusion scheduler, and cascaded feature-map pruner, with peak energy efficiency of 52.90TOPS/W (INT8).
* 3 pages,7 pages, 2025 IEEE International Solid-State Circuits Conference (ISSCC)
A 137.5 TOPS/W SRAM Compute-in-Memory Macro with 9-b Memory Cell-Embedded ADCs and Signal Margin Enhancement Techniques for AI Edge Applications
Jul 19, 2023In this paper, we propose a high-precision SRAM-based CIM macro that can perform 4x4-bit MAC operations and yield 9-bit signed output. The inherent discharge branches of SRAM cells are utilized to apply time-modulated MAC and 9-bit ADC readout operations on two bit-line capacitors. The same principle is used for both MAC and A-to-D conversion ensuring high linearity and thus supporting large number of analog MAC accumulations. The memory cell-embedded ADC eliminates the use of separate ADCs and enhances energy and area efficiency. Additionally, two signal margin enhancement techniques, namely the MAC-folding and boosted-clipping schemes, are proposed to further improve the CIM computation accuracy.
DyBit: Dynamic Bit-Precision Numbers for Efficient Quantized Neural Network Inference
Feb 24, 2023To accelerate the inference of deep neural networks (DNNs), quantization with low-bitwidth numbers is actively researched. A prominent challenge is to quantize the DNN models into low-bitwidth numbers without significant accuracy degradation, especially at very low bitwidths (< 8 bits). This work targets an adaptive data representation with variable-length encoding called DyBit. DyBit can dynamically adjust the precision and range of separate bit-field to be adapted to the DNN weights/activations distribution. We also propose a hardware-aware quantization framework with a mixed-precision accelerator to trade-off the inference accuracy and speedup. Experimental results demonstrate that the inference accuracy via DyBit is 1.997% higher than the state-of-the-art at 4-bit quantization, and the proposed framework can achieve up to 8.1x speedup compared with the original model.
H2Learn: High-Efficiency Learning Accelerator for High-Accuracy Spiking Neural Networks
Jul 25, 2021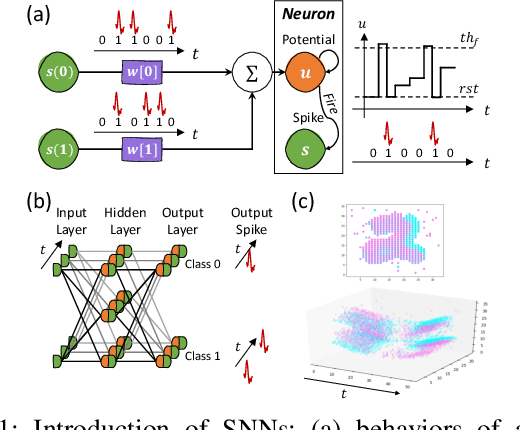
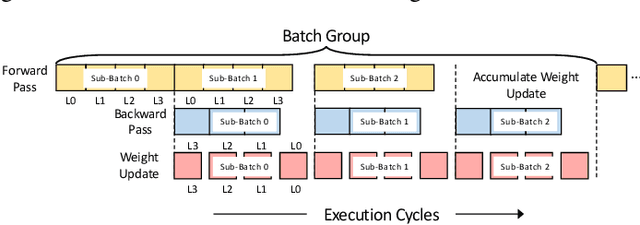
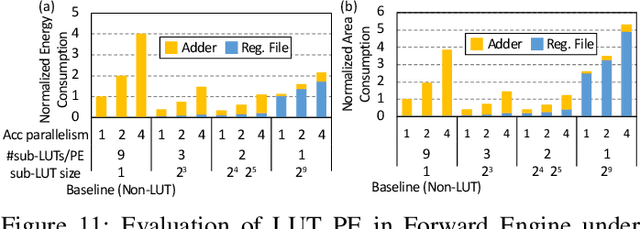
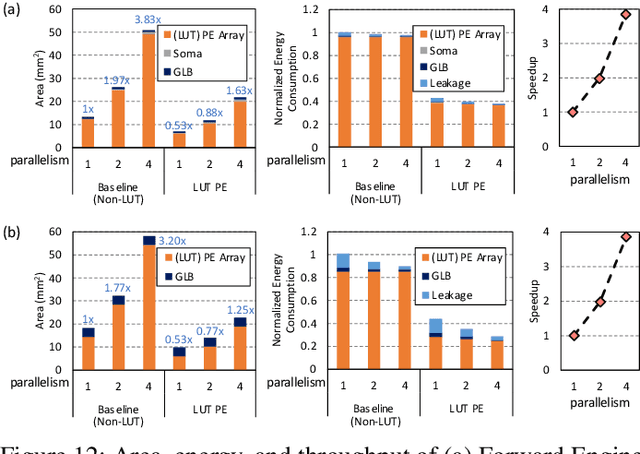
Although spiking neural networks (SNNs) take benefits from the bio-plausible neural modeling, the low accuracy under the common local synaptic plasticity learning rules limits their application in many practical tasks. Recently, an emerging SNN supervised learning algorithm inspired by backpropagation through time (BPTT) from the domain of artificial neural networks (ANNs) has successfully boosted the accuracy of SNNs and helped improve the practicability of SNNs. However, current general-purpose processors suffer from low efficiency when performing BPTT for SNNs due to the ANN-tailored optimization. On the other hand, current neuromorphic chips cannot support BPTT because they mainly adopt local synaptic plasticity rules for simplified implementation. In this work, we propose H2Learn, a novel architecture that can achieve high efficiency for BPTT-based SNN learning which ensures high accuracy of SNNs. At the beginning, we characterized the behaviors of BPTT-based SNN learning. Benefited from the binary spike-based computation in the forward pass and the weight update, we first design lookup table (LUT) based processing elements in Forward Engine and Weight Update Engine to make accumulations implicit and to fuse the computations of multiple input points. Second, benefited from the rich sparsity in the backward pass, we design a dual-sparsity-aware Backward Engine which exploits both input and output sparsity. Finally, we apply a pipeline optimization between different engines to build an end-to-end solution for the BPTT-based SNN learning. Compared with the modern NVIDIA V100 GPU, H2Learn achieves 7.38x area saving, 5.74-10.20x speedup, and 5.25-7.12x energy saving on several benchmark datasets.