 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Training in Spiking Neural Networks
Feb 01, 2026The bio-inspired integrate-fire-reset mechanism of spiking neurons constitutes the foundation for efficient processing in Spiking Neural Networks (SNNs). Recent progress in large models demands that spiking neurons support highly parallel computation to scale efficiently on modern GPUs. This work proposes a novel functional perspective that provides general guidance for designing parallel spiking neurons. We argue that the reset mechanism, which induces complex temporal dependencies and hinders parallel training, should be removed. However, any such modification should satisfy two principles: 1) preserving the functions of reset as a core biological mechanism; and 2) enabling parallel training without sacrificing the serial inference ability of spiking neurons, which underpins their efficiency at test time. To this end, we identify the functions of the reset and analyze how to reconcile parallel training with serial inference, upon which we propose a dynamic decay spiking neuron. We conduct comprehensive testing of our method in terms of: 1) Training efficiency and extrapolation capability. On 16k-length sequences, we achieve a 25.6x training speedup over the pioneering parallel spiking neuron, and our models trained on 2k-length can stably perform inference on sequences as long as 30k. 2) Generality. We demonstrate the consistent effectiveness of the proposed method across five task categories (image classification, neuromorphic event processing, time-series forecasting, language modeling, and reinforcement learning), three network architectures (spiking CNN/Transformer/SSMs), and two spike activation modes (spike/integer activation). 3) Energy consumption. The spiking firing of our neuron is lower than that of vanilla and existing parallel spiking neurons.
BrainFuse: a unified infrastructure integrating realistic biological modeling and core AI methodology
Jan 29, 2026Neuroscience and artificial intelligence represent distinct yet complementary pathways to general intelligence. However, amid the ongoing boom in AI research and applications, the translational synergy between these two fields has grown increasingly elusive-hampered by a widening infrastructural incompatibility: modern AI frameworks lack native support for biophysical realism, while neural simulation tools are poorly suited for gradient-based optimization and neuromorphic hardware deployment. To bridge this gap, we introduce BrainFuse, a unified infrastructure that provides comprehensive support for biophysical neural simulation and gradient-based learning. By addressing algorithmic, computational, and deployment challenges, BrainFuse exhibits three core capabilities: (1) algorithmic integration of detailed neuronal dynamics into a differentiable learning framework; (2) system-level optimization that accelerates customizable ion-channel dynamics by up to 3,000x on GPUs; and (3) scalable computation with highly compatible pipelines for neuromorphic hardware deployment. We demonstrate this full-stack design through both AI and neuroscience tasks, from foundational neuron simulation and functional cylinder modeling to real-world deployment and application scenarios. For neuroscience, BrainFuse supports multiscale biological modeling, enabling the deployment of approximately 38,000 Hodgkin-Huxley neurons with 100 million synapses on a single neuromorphic chip while consuming as low as 1.98 W. For AI, BrainFuse facilitates the synergistic application of realistic biological neuron models, demonstrating enhanced robustness to input noise and improved temporal processing endowed by complex HH dynamics. BrainFuse therefore serves as a foundational engine to facilitate cross-disciplinary research and accelerate the development of next-generation bio-inspired intelligent systems.
Efficient Spike-driven Transformer for High-performance Drone-View Geo-Localization
Dec 22, 2025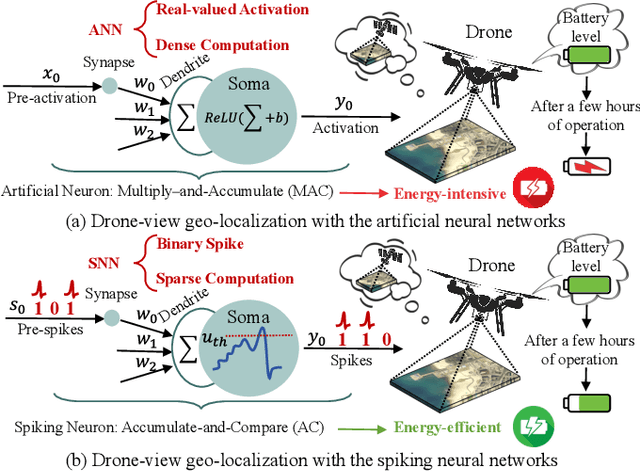
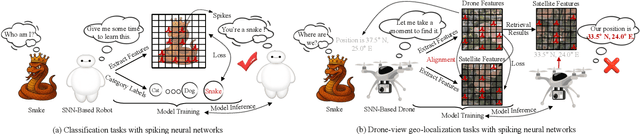
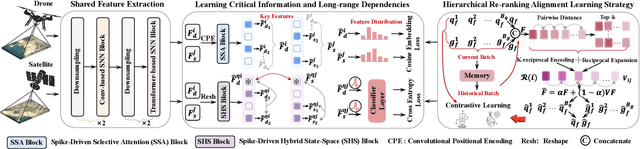
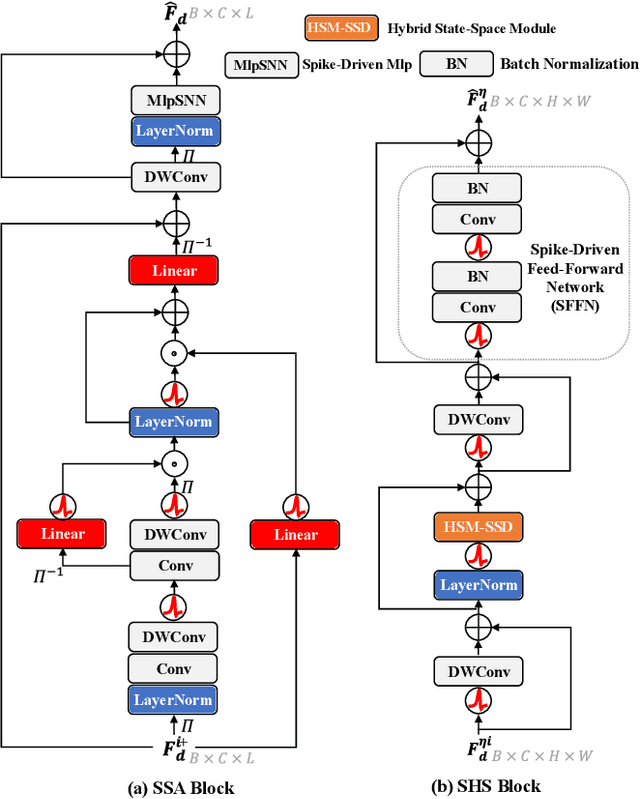
Traditional drone-view geo-localization (DVGL) methods based on artificial neural networks (ANNs) have achieved remarkable performance. However, ANNs rely on dense computation, which results in high power consumption. In contrast, spiking neural networks (SNNs), which benefit from spike-driven computation, inherently provide low power consumption. Regrettably, the potential of SNNs for DVGL has yet to be thoroughly investigated. Meanwhile, the inherent sparsity of spike-driven computation for representation learning scenarios also results in loss of critical information and difficulties in learning long-range dependencies when aligning heterogeneous visual data sources. To address these, we propose SpikeViMFormer, the first SNN framework designed for DVGL. In this framework, a lightweight spike-driven transformer backbone is adopted to extract coarse-grained features. To mitigate the loss of critical information, the spike-driven selective attention (SSA) block is designed, which uses a spike-driven gating mechanism to achieve selective feature enhancement and highlight discriminative regions. Furthermore, a spike-driven hybrid state space (SHS) block is introduced to learn long-range dependencies using a hybrid state space. Moreover, only the backbone is utilized during the inference stage to reduce computational cost. To ensure backbone effectiveness, a novel hierarchical re-ranking alignment learning (HRAL) strategy is proposed. It refines features via neighborhood re-ranking and maintains cross-batch consistency to directly optimize the backbone. Experimental results demonstrate that SpikeViMFormer outperforms state-of-the-art SNNs. Compared with advanced ANNs, it also achieves competitive performance.Our code is available at https://github.com/ISChenawei/SpikeViMFormer
Breaking the Modality Wall: Time-step Mixup for Efficient Spiking Knowledge Transfer from Static to Event Domain
Nov 15, 2025The integration of event cameras and spiking neural networks (SNNs) promises energy-efficient visual intelligence, yet scarce event data and the sparsity of DVS outputs hinder effective training. Prior knowledge transfers from RGB to DVS often underperform because the distribution gap between modalities is substantial. In this work, we present Time-step Mixup Knowledge Transfer (TMKT), a cross-modal training framework with a probabilistic Time-step Mixup (TSM) strategy. TSM exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time steps to produce a smooth curriculum within each sequence, which reduces gradient variance and stabilizes optimization with theoretical analysis. To employ auxiliary supervision from TSM, TMKT introduces two lightweight modality-aware objectives, Modality Aware Guidance (MAG) for per-frame source supervision and Mixup Ratio Perception (MRP) for sequence-level mix ratio estimation, which explicitly align temporal features with the mixing schedule. TMKT enables smoother knowledge transfer, helps mitigate modality mismatch during training, and achieves superior performance in spiking image classification tasks. Extensive experiments across diverse benchmarks and multiple SNN backbones, together with ablations, demonstrate the effectiveness of our method.
SpikingBrain Technical Report: Spiking Brain-inspired Large Models
Sep 05, 2025Mainstream Transformer-based large language models face major efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly, limiting long-context processing. Building large models on non-NVIDIA platforms also poses challenges for stable and efficient training. To address this, we introduce SpikingBrain, a family of brain-inspired models designed for efficient long-context training and inference. SpikingBrain leverages the MetaX GPU cluster and focuses on three aspects: (1) Model Architecture: linear and hybrid-linear attention architectures with adaptive spiking neurons; (2) Algorithmic Optimizations: an efficient, conversion-based training pipeline and a dedicated spike coding framework; (3) System Engineering: customized training frameworks, operator libraries, and parallelism strategies tailored to MetaX hardware. Using these techniques, we develop two models: SpikingBrain-7B, a linear LLM, and SpikingBrain-76B, a hybrid-linear MoE LLM. These models demonstrate the feasibility of large-scale LLM development on non-NVIDIA platforms. SpikingBrain achieves performance comparable to open-source Transformer baselines while using only about 150B tokens for continual pre-training. Our models significantly improve long-sequence training efficiency and deliver inference with (partially) constant memory and event-driven spiking behavior. For example, SpikingBrain-7B attains over 100x speedup in Time to First Token for 4M-token sequences. Training remains stable for weeks on hundreds of MetaX C550 GPUs, with the 7B model reaching a Model FLOPs Utilization of 23.4 percent. The proposed spiking scheme achieves 69.15 percent sparsity, enabling low-power operation. Overall, this work demonstrates the potential of brain-inspired mechanisms to drive the next generation of efficient and scalable large model design.
Scaling Linear Attention with Sparse State Expansion
Jul 22, 2025The Transformer architecture, despite its widespread success, struggles with long-context scenarios due to quadratic computation and linear memory growth. While various linear attention variants mitigate these efficiency constraints by compressing context into fixed-size states, they often degrade performance in tasks such as in-context retrieval and reasoning. To address this limitation and achieve more effective context compression, we propose two key innovations. First, we introduce a row-sparse update formulation for linear attention by conceptualizing state updating as information classification. This enables sparse state updates via softmax-based top-$k$ hard classification, thereby extending receptive fields and reducing inter-class interference. Second, we present Sparse State Expansion (SSE) within the sparse framework, which expands the contextual state into multiple partitions, effectively decoupling parameter size from state capacity while maintaining the sparse classification paradigm. Our design, supported by efficient parallelized implementations, yields effective classification and discriminative state representations. We extensively validate SSE in both pure linear and hybrid (SSE-H) architectures across language modeling, in-context retrieval, and mathematical reasoning benchmarks. SSE demonstrates strong retrieval performance and scales favorably with state size. Moreover, after reinforcement learning (RL) training, our 2B SSE-H model achieves state-of-the-art mathematical reasoning performance among small reasoning models, scoring 64.7 on AIME24 and 51.3 on AIME25, significantly outperforming similarly sized open-source Transformers. These results highlight SSE as a promising and efficient architecture for long-context modeling.
SVL: Spike-based Vision-language Pretraining for Efficient 3D Open-world Understanding
May 23, 2025Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing SNNs still exhibit a significant performance gap compared to Artificial Neural Networks (ANNs) due to inadequate pre-training strategies. These limitations manifest as restricted generalization ability, task specificity, and a lack of multimodal understanding, particularly in challenging tasks such as multimodal question answering and zero-shot 3D classification. To overcome these challenges, we propose a Spike-based Vision-Language (SVL) pretraining framework that empowers SNNs with open-world 3D understanding while maintaining spike-driven efficiency. SVL introduces two key components: (i) Multi-scale Triple Alignment (MTA) for label-free triplet-based contrastive learning across 3D, image, and text modalities, and (ii) Re-parameterizable Vision-Language Integration (Rep-VLI) to enable lightweight inference without relying on large text encoders. Extensive experiments show that SVL achieves a top-1 accuracy of 85.4% in zero-shot 3D classification, surpassing advanced ANN models, and consistently outperforms prior SNNs on downstream tasks, including 3D classification (+6.1%), DVS action recognition (+2.1%), 3D detection (+1.1%), and 3D segmentation (+2.1%) with remarkable efficiency. Moreover, SVL enables SNNs to perform open-world 3D question answering, sometimes outperforming ANNs. To the best of our knowledge, SVL represents the first scalable, generalizable, and hardware-friendly paradigm for 3D open-world understanding, effectively bridging the gap between SNNs and ANNs in complex open-world understanding tasks. Code is available https://github.com/bollossom/SVL.
SpikeVideoFormer: An Efficient Spike-Driven Video Transformer with Hamming Attention and $\mathcal{O}(T)$ Complexity
May 15, 2025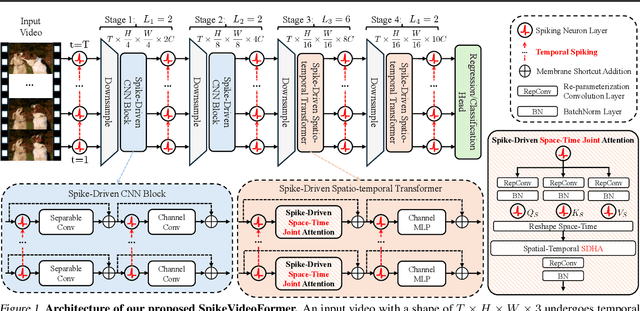
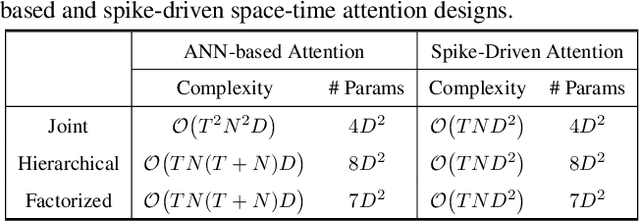

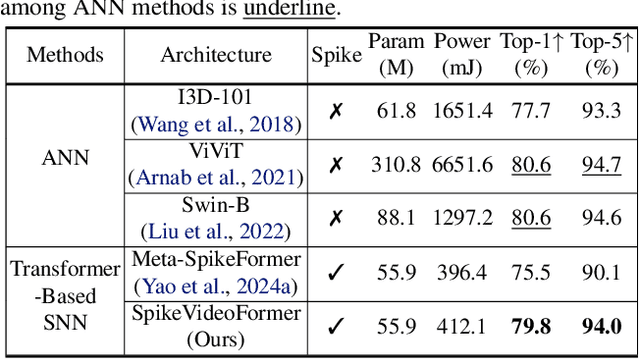
Spiking Neural Networks (SNNs) have shown competitive performance to Artificial Neural Networks (ANNs) in various vision tasks, while offering superior energy efficiency. However, existing SNN-based Transformers primarily focus on single-image tasks, emphasizing spatial features while not effectively leveraging SNNs' efficiency in video-based vision tasks. In this paper, we introduce SpikeVideoFormer, an efficient spike-driven video Transformer, featuring linear temporal complexity $\mathcal{O}(T)$. Specifically, we design a spike-driven Hamming attention (SDHA) which provides a theoretically guided adaptation from traditional real-valued attention to spike-driven attention. Building on SDHA, we further analyze various spike-driven space-time attention designs and identify an optimal scheme that delivers appealing performance for video tasks, while maintaining only linear temporal complexity. The generalization ability and efficiency of our model are demonstrated across diverse downstream video tasks, including classification, human pose tracking, and semantic segmentation. Empirical results show our method achieves state-of-the-art (SOTA) performance compared to existing SNN approaches, with over 15\% improvement on the latter two tasks. Additionally, it matches the performance of recent ANN-based methods while offering significant efficiency gains, achieving $\times 16$, $\times 10$ and $\times 5$ improvements on the three tasks. https://github.com/JimmyZou/SpikeVideoFormer
Human Activity Recognition using RGB-Event based Sensors: A Multi-modal Heat Conduction Model and A Benchmark Dataset
Apr 08, 2025



Human Activity Recognition (HAR) primarily relied on traditional RGB cameras to achieve high-performance activity recognition. However, the challenging factors in real-world scenarios, such as insufficient lighting and rapid movements, inevitably degrade the performance of RGB cameras. To address these challenges, biologically inspired event cameras offer a promising solution to overcome the limitations of traditional RGB cameras. In this work, we rethink human activity recognition by combining the RGB and event cameras. The first contribution is the proposed large-scale multi-modal RGB-Event human activity recognition benchmark dataset, termed HARDVS 2.0, which bridges the dataset gaps. It contains 300 categories of everyday real-world actions with a total of 107,646 paired videos covering various challenging scenarios. Inspired by the physics-informed heat conduction model, we propose a novel multi-modal heat conduction operation framework for effective activity recognition, termed MMHCO-HAR. More in detail, given the RGB frames and event streams, we first extract the feature embeddings using a stem network. Then, multi-modal Heat Conduction blocks are designed to fuse the dual features, the key module of which is the multi-modal Heat Conduction Operation layer. We integrate RGB and event embeddings through a multi-modal DCT-IDCT layer while adaptively incorporating the thermal conductivity coefficient via FVEs into this module. After that, we propose an adaptive fusion module based on a policy routing strategy for high-performance classification. Comprehensive experiments demonstrate that our method consistently performs well, validating its effectiveness and robustness. The source code and benchmark dataset will be released on https://github.com/Event-AHU/HARDVS/tree/HARDVSv2
Autoregressive Image Generation with Randomized Parallel Decoding
Mar 13, 2025We introduce ARPG, a novel visual autoregressive model that enables randomized parallel generation, addressing the inherent limitations of conventional raster-order approaches, which hinder inference efficiency and zero-shot generalization due to their sequential, predefined token generation order. Our key insight is that effective random-order modeling necessitates explicit guidance for determining the position of the next predicted token. To this end, we propose a novel guided decoding framework that decouples positional guidance from content representation, encoding them separately as queries and key-value pairs. By directly incorporating this guidance into the causal attention mechanism, our approach enables fully random-order training and generation, eliminating the need for bidirectional attention. Consequently, ARPG readily generalizes to zero-shot tasks such as image inpainting, outpainting, and resolution expansion. Furthermore, it supports parallel inference by concurrently processing multiple queries using a shared KV cache. On the ImageNet-1K 256 benchmark, our approach attains an FID of 1.94 with only 64 sampling steps, achieving over a 20-fold increase in throughput while reducing memory consumption by over 75% compared to representative recent autoregressive models at a similar scale.