 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthSim: Towards Authentic and Effective Safety-critical Scenario Generation for Autonomous Driving Tests
Feb 28, 2025Generating adversarial safety-critical scenarios is a pivotal method for testing autonomous driving systems, as it identifies potential weaknesses and enhances system robustness and reliability. However, existing approaches predominantly emphasize unrestricted collision scenarios, prompting non-player character (NPC) vehicles to attack the ego vehicle indiscriminately. These works overlook these scenarios' authenticity, rationality, and relevance, resulting in numerous extreme, contrived, and largely unrealistic collision events involving aggressive NPC vehicles. To rectify this issue, we propose a three-layer relative safety region model, which partitions the area based on danger levels and increases the likelihood of NPC vehicles entering relative boundary regions. This model directs NPC vehicles to engage in adversarial actions within relatively safe boundary regions, thereby augmenting the scenarios' authenticity. We introduce AuthSim, a comprehensive platform for generating authentic and effective safety-critical scenarios by integrating the three-layer relative safety region model with reinforcement learning. To our knowledge, this is the first attempt to address the authenticity and effectiveness of autonomous driving system test scenarios comprehensively. Extensive experiments demonstrate that AuthSim outperforms existing methods in generating effective safety-critical scenarios. Notably, AuthSim achieves a 5.25% improvement in average cut-in distance and a 27.12% enhancement in average collision interval time, while maintaining higher efficiency in generating effective safety-critical scenarios compared to existing methods. This underscores its significant advantage in producing authentic scenarios over current methodologies.
Towards Efficient Full 8-bit Integer DNN Online Training on Resource-limited Devices without Batch Normalization
May 27, 2021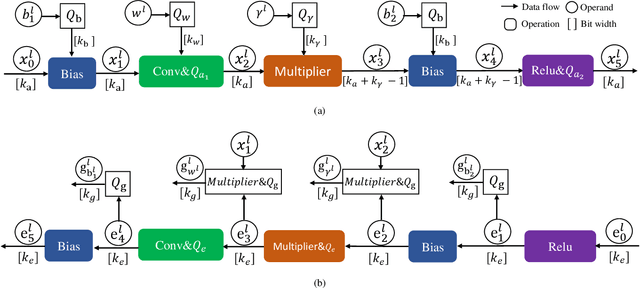

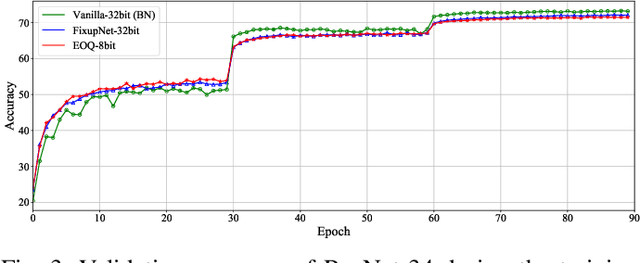

Huge computational costs brought by convolution and batch normalization (BN) have caused great challenges for the online training and corresponding applications of deep neural networks (DNNs), especially in resource-limited devices. Existing works only focus on the convolution or BN acceleration and no solution can alleviate both problems with satisfactory performance. Online training has gradually become a trend in resource-limited devices like mobile phones while there is still no complete technical scheme with acceptable model performance, processing speed, and computational cost. In this research, an efficient online-training quantization framework termed EOQ is proposed by combining Fixup initialization and a novel quantization scheme for DNN model compression and acceleration. Based on the proposed framework, we have successfully realized full 8-bit integer network training and removed BN in large-scale DNNs. Especially, weight updates are quantized to 8-bit integers for the first time. Theoretical analyses of EOQ utilizing Fixup initialization for removing BN have been further given using a novel Block Dynamical Isometry theory with weaker assumptions. Benefiting from rational quantization strategies and the absence of BN, the full 8-bit networks based on EOQ can achieve state-of-the-art accuracy and immense advantages in computational cost and processing speed. What is more, the design of deep learning chips can be profoundly simplified for the absence of unfriendly square root operations in BN. Beyond this, EOQ has been evidenced to be more advantageous in small-batch online training with fewer batch samples. In summary, the EOQ framework is specially designed for reducing the high cost of convolution and BN in network training, demonstrating a broad application prospect of online training in resource-limited devices.
Training and Inference for Integer-Based Semantic Segmentation Network
Nov 30, 2020Semantic segmentation has been a major topic in research and industry in recent years. However, due to the computation complexity of pixel-wise prediction and backpropagation algorithm, semantic segmentation has been demanding in computation resources, resulting in slow training and inference speed and large storage space to store models. Existing schemes that speed up segmentation network change the network structure and come with noticeable accuracy degradation. However, neural network quantization can be used to reduce computation load while maintaining comparable accuracy and original network structure. Semantic segmentation networks are different from traditional deep convolutional neural networks (DCNNs) in many ways, and this topic has not been thoroughly explored in existing works. In this paper, we propose a new quantization framework for training and inference of segmentation networks, where parameters and operations are constrained to 8-bit integer-based values for the first time. Full quantization of the data flow and the removal of square and root operations in batch normalization give our framework the ability to perform inference on fixed-point devices. Our proposed framework is evaluated on mainstream semantic segmentation networks like FCN-VGG16 and DeepLabv3-ResNet50, achieving comparable accuracy against floating-point framework on ADE20K dataset and PASCAL VOC 2012 dataset.
Restoring Negative Information in Few-Shot Object Detection
Oct 26, 2020



Few-shot learning has recently emerged as a new challenge in the deep learning field: unlike conventional methods that train the deep neural networks (DNNs) with a large number of labeled data, it asks for the generalization of DNNs on new classes with few annotated samples. Recent advances in few-shot learning mainly focus on image classification while in this paper we focus on object detection. The initial explorations in few-shot object detection tend to simulate a classification scenario by using the positive proposals in images with respect to certain object class while discarding the negative proposals of that class. Negatives, especially hard negatives, however, are essential to the embedding space learning in few-shot object detection. In this paper, we restore the negative information in few-shot object detection by introducing a new negative- and positive-representative based metric learning framework and a new inference scheme with negative and positive representatives. We build our work on a recent few-shot pipeline RepMet with several new modules to encode negative information for both training and testing. Extensive experiments on ImageNet-LOC and PASCAL VOC show our method substantially improves the state-of-the-art few-shot object detection solutions. Our code is available at https://github.com/yang-yk/NP-RepMet.
Transfer Learning in General Lensless Imaging through Scattering Media
Dec 28, 2019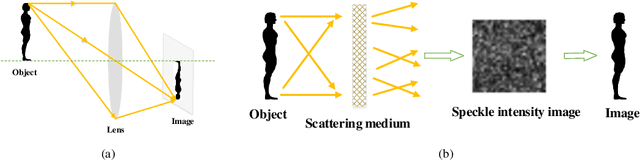
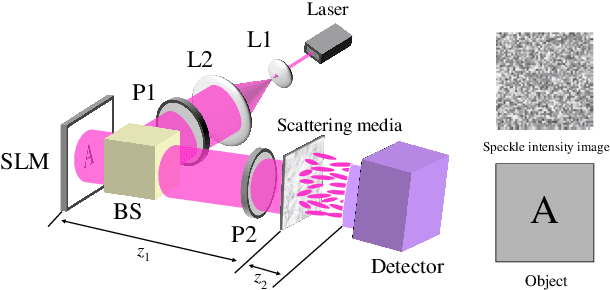
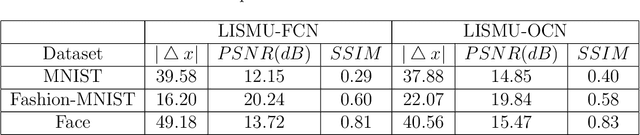

Recently deep neural networks (DNNs) have been successfully introduced to the field of lensless imaging through scattering media. By solving an inverse problem in computational imaging, DNNs can overcome several shortcomings in the conventional lensless imaging through scattering media methods, namely, high cost, poor quality, complex control, and poor anti-interference. However, for training, a large number of training samples on various datasets have to be collected, with a DNN trained on one dataset generally performing poorly for recovering images from another dataset. The underlying reason is that lensless imaging through scattering media is a high dimensional regression problem and it is difficult to obtain an analytical solution. In this work, transfer learning is proposed to address this issue. Our main idea is to train a DNN on a relatively complex dataset using a large number of training samples and fine-tune the last few layers using very few samples from other datasets. Instead of the thousands of samples required to train from scratch, transfer learning alleviates the problem of costly data acquisition. Specifically, considering the difference in sample sizes and similarity among datasets, we propose two DNN architectures, namely LISMU-FCN and LISMU-OCN, and a balance loss function designed for balancing smoothness and sharpness. LISMU-FCN, with much fewer parameters, can achieve imaging across similar datasets while LISMU-OCN can achieve imaging across significantly different datasets. What's more, we establish a set of simulation algorithms which are close to the real experiment, and it is of great significance and practical value in the research on lensless scattering imaging. In summary, this work provides a new solution for lensless imaging through scattering media using transfer learning in DNNs.
DashNet: A Hybrid Artificial and Spiking Neural Network for High-speed Object Tracking
Sep 15, 2019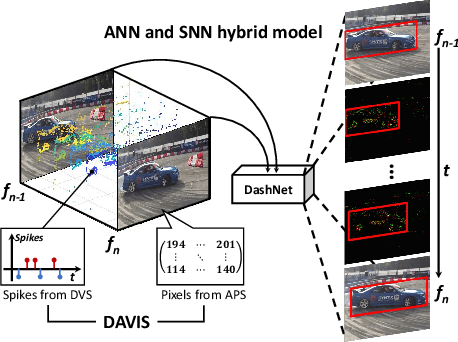

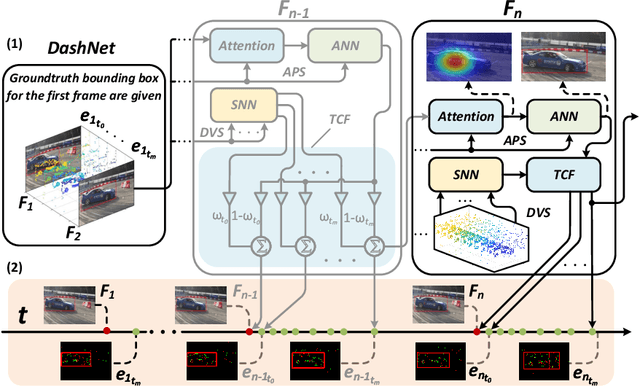
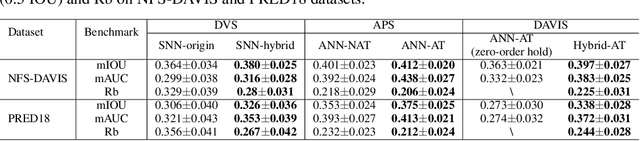
Computer-science-oriented artificial neural networks (ANNs) have achieved tremendous success in a variety of scenarios via powerful feature extraction and high-precision data operations. It is well known, however, that ANNs usually suffer from expensive processing resources and costs. In contrast, neuroscience-oriented spiking neural networks (SNNs) are promising for energy-efficient information processing benefit from the event-driven spike activities, whereas, they are yet be evidenced to achieve impressive effectiveness on real complicated tasks. How to combine the advantage of these two model families is an open question of great interest. Two significant challenges need to be addressed: (1) lack of benchmark datasets including both ANN-oriented (frames) and SNN-oriented (spikes) signal resources; (2) the difficulty in jointly processing the synchronous activation from ANNs and event-driven spikes from SNNs. In this work, we proposed a hybrid paradigm, named as DashNet, to demonstrate the advantages of combining ANNs and SNNs in a single model. A simulator and benchmark dataset NFS-DAVIS is built, and a temporal complementary filter (TCF) and attention module are designed to address the two mentioned challenges, respectively. In this way, it is shown that DashNet achieves the record-breaking speed of 2083FPS on neuromorphic chips and the best tracking performance on NFS-DAVIS and PRED18 datasets. To the best of our knowledge, DashNet is the first framework that can integrate and process ANNs and SNNs in a hybrid paradigm, which provides a novel solution to achieve both effectiveness and efficiency for high-speed object tracking.
Training High-Performance and Large-Scale Deep Neural Networks with Full 8-bit Integers
Sep 05, 2019


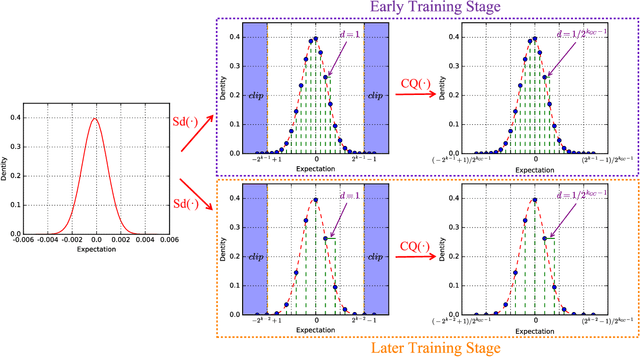
Deep neural network (DNN) quantization converting floating-point (FP) data in the network to integers (INT) is an effective way to shrink the model size for memory saving and simplify the operations for compute acceleration. Recently, researches on DNN quantization develop from inference to training, laying a foundation for the online training on accelerators. However, existing schemes leaving batch normalization (BN) untouched during training are mostly incomplete quantization that still adopts high precision FP in some parts of the data paths. Currently, there is no solution that can use only low bit-width INT data during the whole training process of large-scale DNNs with acceptable accuracy. In this work, through decomposing all the computation steps in DNNs and fusing three special quantization functions to satisfy the different precision requirements, we propose a unified complete quantization framework termed as "WAGEUBN" to quantize DNNs involving all data paths including W (Weights), A (Activation), G (Gradient), E (Error), U (Update), and BN. Moreover, the Momentum optimizer is also quantized to realize a completely quantized framework. Experiments on ResNet18/34/50 models demonstrate that WAGEUBN can achieve competitive accuracy on ImageNet dataset. For the first time, the study of quantization in large-scale DNNs is advanced to the full 8-bit INT level. In this way, all the operations in the training and inference can be bit-wise operations, pushing towards faster processing speed, decreased memory cost, and higher energy efficiency. Our throughout quantization framework has great potential for future efficient portable devices with online learning ability.