 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025
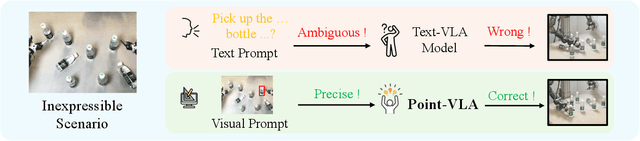
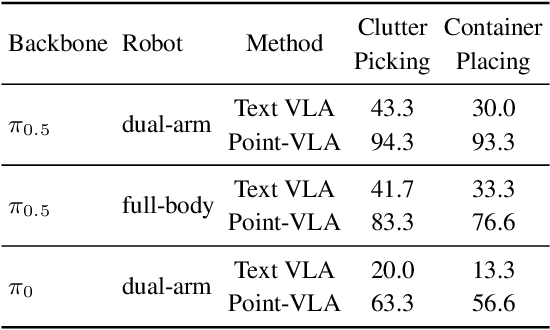
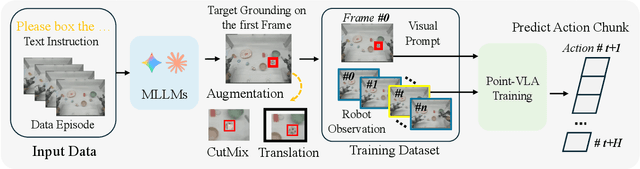
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
End-to-End Hardware Modeling and Sensitivity Optimization of Photoacoustic Signal Readout Chains
Nov 12, 2025The sensitivity of the acoustic detection subsystem in photoacoustic imaging (PAI) critically affects image quality. However, previous studies often focused only on front-end acoustic components or back-end electronic components, overlooking end-to-end coupling among the transducer, cable, and receiver. This work develops a complete analytical model for system-level sensitivity optimization based on the Krimholtz, Leedom, and Matthaei (KLM) model. The KLM model is rederived from first principles of linear piezoelectric constitutive equations, 1D wave equations and transmission line theory to clarify its physical basis and applicable conditions. By encapsulating the acoustic components into a controlled voltage source and extending the model to include lumped-parameter representations of cable and receiver, an end-to-end equivalent circuit is established. Analytical expressions for the system transfer functions are derived, revealing the coupling effects among key parameters such as transducer element area (EA), cable length (CL), and receiver impedance (RI). Experimental results validate the model with an average error below 5%. Additionally, a low-frequency tailing phenomenon arising from exceeding the 1D vibration assumption is identified and analyzed, illustrating the importance of understanding the model's applicable conditions and providing a potential pathway for artifact suppression. This work offers a comprehensive framework for optimizing detection sensitivity and improving image fidelity in PAI systems.
Neural Fields for Adaptive Photoacoustic Computed Tomography
Sep 17, 2024


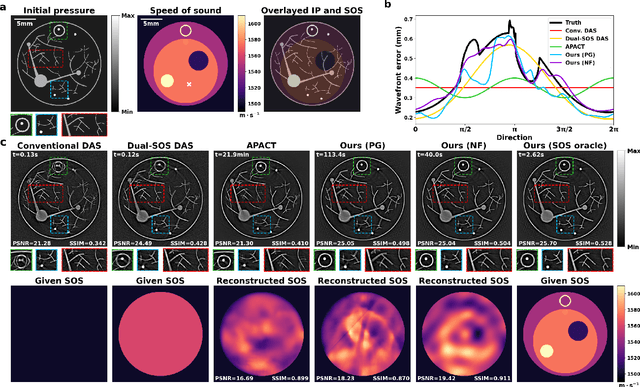
Photoacoustic computed tomography (PACT) is a non-invasive imaging modality with wide medical applications. Conventional PACT image reconstruction algorithms suffer from wavefront distortion caused by the heterogeneous speed of sound (SOS) in tissue, which leads to image degradation. Accounting for these effects improves image quality, but measuring the SOS distribution is experimentally expensive. An alternative approach is to perform joint reconstruction of the initial pressure image and SOS using only the PA signals. Existing joint reconstruction methods come with limitations: high computational cost, inability to directly recover SOS, and reliance on inaccurate simplifying assumptions. Implicit neural representation, or neural fields, is an emerging technique in computer vision to learn an efficient and continuous representation of physical fields with a coordinate-based neural network. In this work, we introduce NF-APACT, an efficient self-supervised framework utilizing neural fields to estimate the SOS in service of an accurate and robust multi-channel deconvolution. Our method removes SOS aberrations an order of magnitude faster and more accurately than existing methods. We demonstrate the success of our method on a novel numerical phantom as well as an experimentally collected phantom and in vivo data. Our code and numerical phantom are available at https://github.com/Lukeli0425/NF-APACT.
Streamlined Photoacoustic Image Processing with Foundation Models: A Training-Free Solution
Apr 11, 2024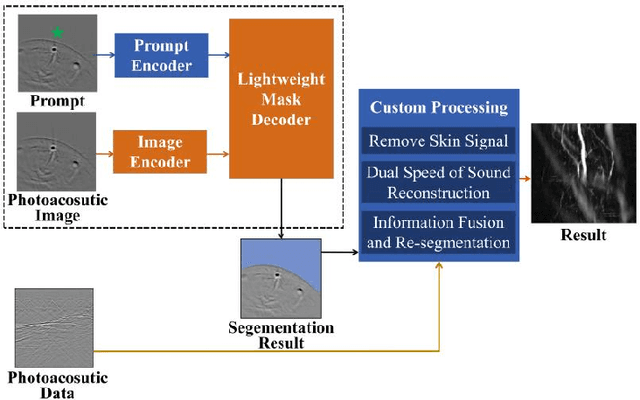


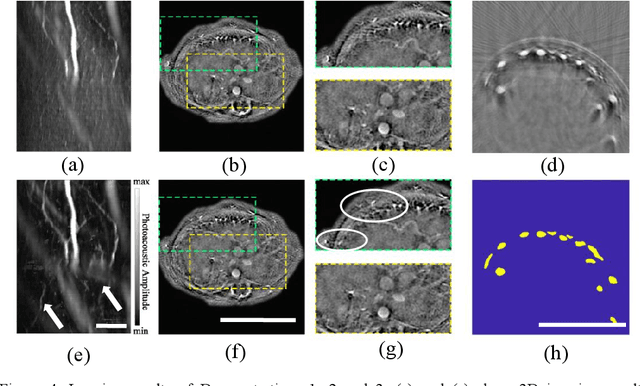
Foundation models have rapidly evolved and have achieved significant accomplishments in computer vision tasks. Specifically, the prompt mechanism conveniently allows users to integrate image prior information into the model, making it possible to apply models without any training. Therefore, we propose a method based on foundation models and zero training to solve the tasks of photoacoustic (PA) image segmentation. We employed the segment anything model (SAM) by setting simple prompts and integrating the model's outputs with prior knowledge of the imaged objects to accomplish various tasks, including: (1) removing the skin signal in three-dimensional PA image rendering; (2) dual speed-of-sound reconstruction, and (3) segmentation of finger blood vessels. Through these demonstrations, we have concluded that deep learning can be directly applied in PA imaging without the requirement for network design and training. This potentially allows for a hands-on, convenient approach to achieving efficient and accurate segmentation of PA images. This letter serves as a comprehensive tutorial, facilitating the mastery of the technique through the provision of code and sample datasets.
Learning Series-Parallel Lookup Tables for Efficient Image Super-Resolution
Jul 26, 2022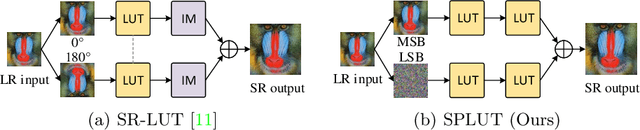

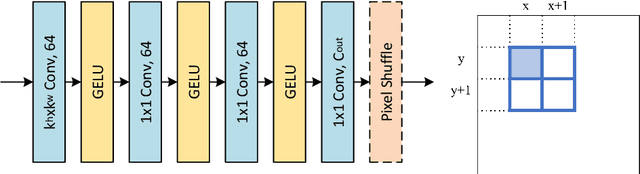
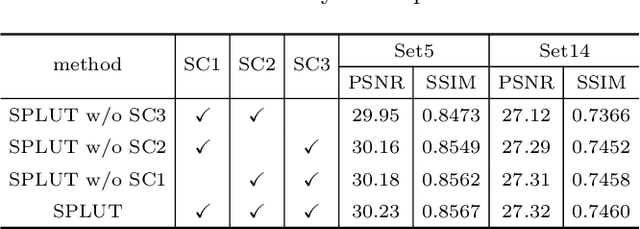
Lookup table (LUT) has shown its efficacy in low-level vision tasks due to the valuable characteristics of low computational cost and hardware independence. However, recent attempts to address the problem of single image super-resolution (SISR) with lookup tables are highly constrained by the small receptive field size. Besides, their frameworks of single-layer lookup tables limit the extension and generalization capacities of the model. In this paper, we propose a framework of series-parallel lookup tables (SPLUT) to alleviate the above issues and achieve efficient image super-resolution. On the one hand, we cascade multiple lookup tables to enlarge the receptive field of each extracted feature vector. On the other hand, we propose a parallel network which includes two branches of cascaded lookup tables which process different components of the input low-resolution images. By doing so, the two branches collaborate with each other and compensate for the precision loss of discretizing input pixels when establishing lookup tables. Compared to previous lookup table-based methods, our framework has stronger representation abilities with more flexible architectures. Furthermore, we no longer need interpolation methods which introduce redundant computations so that our method can achieve faster inference speed. Extensive experimental results on five popular benchmark datasets show that our method obtains superior SISR performance in a more efficient way. The code is available at https://github.com/zhjy2016/SPLUT.
Weakly Supervised High-Fidelity Clothing Model Generation
Dec 14, 2021
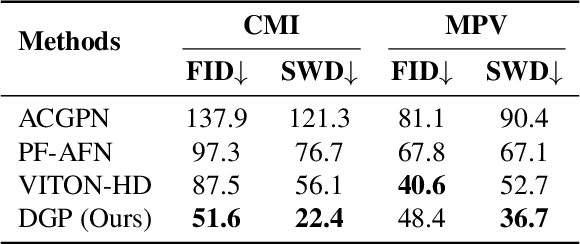
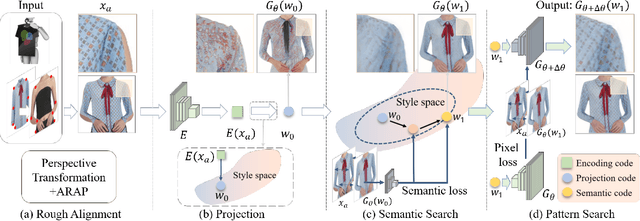

The development of online economics arouses the demand of generating images of models on product clothes, to display new clothes and promote sales. However, the expensive proprietary model images challenge the existing image virtual try-on methods in this scenario, as most of them need to be trained on considerable amounts of model images accompanied with paired clothes images. In this paper, we propose a cheap yet scalable weakly-supervised method called Deep Generative Projection (DGP) to address this specific scenario. Lying in the heart of the proposed method is to imitate the process of human predicting the wearing effect, which is an unsupervised imagination based on life experience rather than computation rules learned from supervisions. Here a pretrained StyleGAN is used to capture the practical experience of wearing. Experiments show that projecting the rough alignment of clothing and body onto the StyleGAN space can yield photo-realistic wearing results. Experiments on real scene proprietary model images demonstrate the superiority of DGP over several state-of-the-art supervised methods when generating clothing model images.
Structure-Preserving Image Super-Resolution
Sep 26, 2021

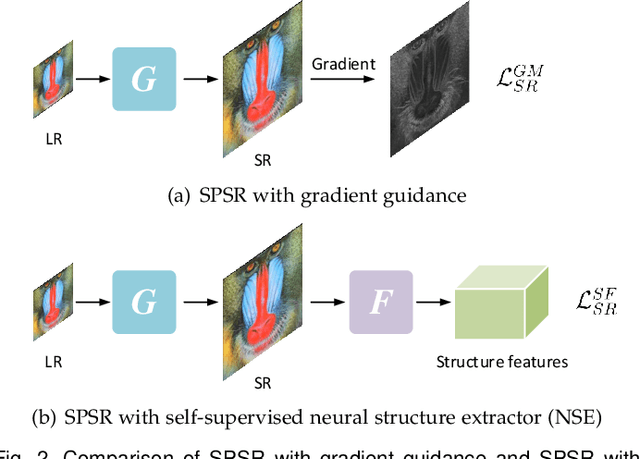

Structures matter in single image super-resolution (SISR). Benefiting from generative adversarial networks (GANs), recent studies have promoted the development of SISR by recovering photo-realistic images. However, there are still undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super-resolution (SPSR) method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Firstly, we propose SPSR with gradient guidance (SPSR-G) by exploiting gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss to impose a second-order restriction on the super-resolved images, which helps generative networks concentrate more on geometric structures. Secondly, since the gradient maps are handcrafted and may only be able to capture limited aspects of structural information, we further extend SPSR-G by introducing a learnable neural structure extractor (NSE) to unearth richer local structures and provide stronger supervision for SR. We propose two self-supervised structure learning methods, contrastive prediction and solving jigsaw puzzles, to train the NSEs. Our methods are model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results on five benchmark datasets show that the proposed methods outperform state-of-the-art perceptual-driven SR methods under LPIPS, PSNR, and SSIM metrics. Visual results demonstrate the superiority of our methods in restoring structures while generating natural SR images. Code is available at https://github.com/Maclory/SPSR.
Rank-Consistency Deep Hashing for Scalable Multi-Label Image Search
Feb 02, 2021
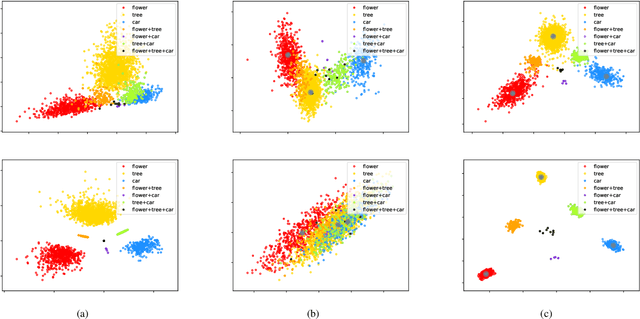

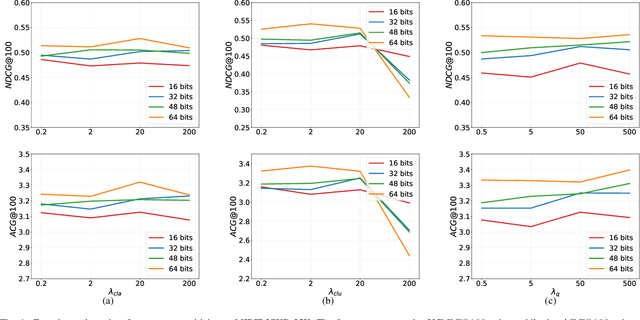
As hashing becomes an increasingly appealing technique for large-scale image retrieval, multi-label hashing is also attracting more attention for the ability to exploit multi-level semantic contents. In this paper, we propose a novel deep hashing method for scalable multi-label image search. Unlike existing approaches with conventional objectives such as contrast and triplet losses, we employ a rank list, rather than pairs or triplets, to provide sufficient global supervision information for all the samples. Specifically, a new rank-consistency objective is applied to align the similarity orders from two spaces, the original space and the hamming space. A powerful loss function is designed to penalize the samples whose semantic similarity and hamming distance are mismatched in two spaces. Besides, a multi-label softmax cross-entropy loss is presented to enhance the discriminative power with a concise formulation of the derivative function. In order to manipulate the neighborhood structure of the samples with different labels, we design a multi-label clustering loss to cluster the hashing vectors of the samples with the same labels by reducing the distances between the samples and their multiple corresponding class centers. The state-of-the-art experimental results achieved on three public multi-label datasets, MIRFLICKR-25K, IAPRTC12 and NUS-WIDE, demonstrate the effectiveness of the proposed method.
Structure-Preserving Super Resolution with Gradient Guidance
Mar 29, 2020
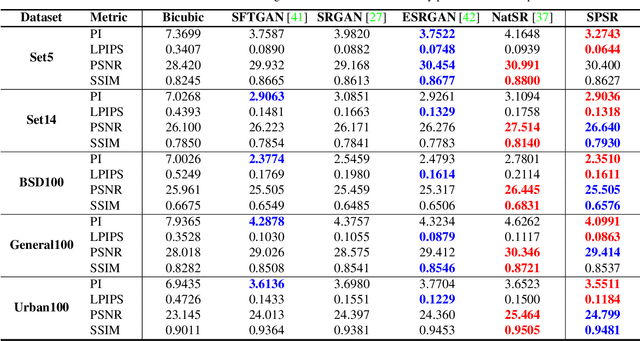
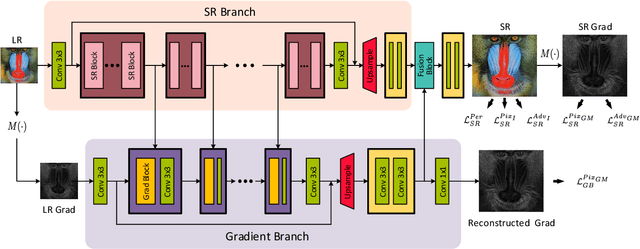

Structures matter in single image super resolution (SISR). Recent studies benefiting from generative adversarial network (GAN) have promoted the development of SISR by recovering photo-realistic images. However, there are always undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super resolution method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Specifically, we exploit gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss which imposes a second-order restriction on the super-resolved images. Along with the previous image-space loss functions, the gradient-space objectives help generative networks concentrate more on geometric structures. Moreover, our method is model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results show that we achieve the best PI and LPIPS performance and meanwhile comparable PSNR and SSIM compared with state-of-the-art perceptual-driven SR methods. Visual results demonstrate our superiority in restoring structures while generating natural SR images.
Deep Face Super-Resolution with Iterative Collaboration between Attentive Recovery and Landmark Estimation
Mar 29, 2020
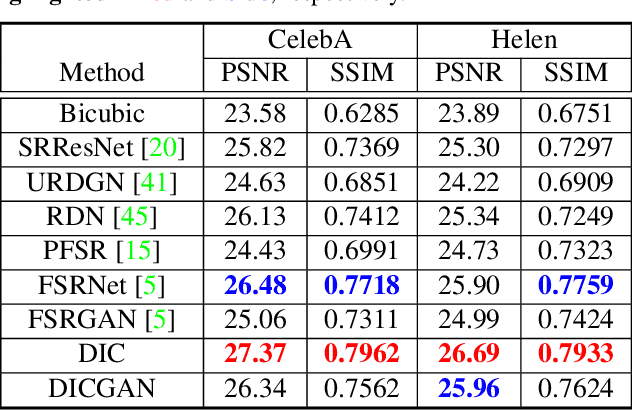


Recent works based on deep learning and facial priors have succeeded in super-resolving severely degraded facial images. However, the prior knowledge is not fully exploited in existing methods, since facial priors such as landmark and component maps are always estimated by low-resolution or coarsely super-resolved images, which may be inaccurate and thus affect the recovery performance. In this paper, we propose a deep face super-resolution (FSR) method with iterative collaboration between two recurrent networks which focus on facial image recovery and landmark estimation respectively. In each recurrent step, the recovery branch utilizes the prior knowledge of landmarks to yield higher-quality images which facilitate more accurate landmark estimation in turn. Therefore, the iterative information interaction between two processes boosts the performance of each other progressively. Moreover, a new attentive fusion module is designed to strengthen the guidance of landmark maps, where facial components are generated individually and aggregated attentively for better restoration. Quantitative and qualitative experimental results show the proposed method significantly outperforms state-of-the-art FSR methods in recovering high-quality face images.