 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Intention to Action Prediction: A Comprehensive Benchmark for Intention-driven End-to-End Autonomous Driving
Dec 13, 2025Current end-to-end autonomous driving systems operate at a level of intelligence akin to following simple steering commands. However, achieving genuinely intelligent autonomy requires a paradigm shift: moving from merely executing low-level instructions to understanding and fulfilling high-level, abstract human intentions. This leap from a command-follower to an intention-fulfiller, as illustrated in our conceptual framework, is hindered by a fundamental challenge: the absence of a standardized benchmark to measure and drive progress on this complex task. To address this critical gap, we introduce Intention-Drive, the first comprehensive benchmark designed to evaluate the ability to translate high-level human intent into safe and precise driving actions. Intention-Drive features two core contributions: (1) a new dataset of complex scenarios paired with corresponding natural language intentions, and (2) a novel evaluation protocol centered on the Intent Success Rate (ISR), which assesses the semantic fulfillment of the human's goal beyond simple geometric accuracy. Through an extensive evaluation of a spectrum of baseline models on Intention-Drive, we reveal a significant performance deficit, showing that the baseline model struggle to achieve the comprehensive scene and intention understanding required for this advanced task.
RVLF: A Reinforcing Vision-Language Framework for Gloss-Free Sign Language Translation
Dec 08, 2025Gloss-free sign language translation (SLT) is hindered by two key challenges: **inadequate sign representation** that fails to capture nuanced visual cues, and **sentence-level semantic misalignment** in current LLM-based methods, which limits translation quality. To address these issues, we propose a three-stage **r**einforcing **v**ision-**l**anguage **f**ramework (**RVLF**). We build a large vision-language model (LVLM) specifically designed for sign language, and then combine it with reinforcement learning (RL) to adaptively enhance translation performance. First, for a sufficient representation of sign language, RVLF introduces an effective semantic representation learning mechanism that fuses skeleton-based motion cues with semantically rich visual features extracted via DINOv2, followed by instruction tuning to obtain a strong SLT-SFT baseline. Then, to improve sentence-level semantic misalignment, we introduce a GRPO-based optimization strategy that fine-tunes the SLT-SFT model with a reward function combining translation fidelity (BLEU) and sentence completeness (ROUGE), yielding the optimized model termed SLT-GRPO. Our conceptually simple framework yields substantial gains under the gloss-free SLT setting without pre-training on any external large-scale sign language datasets, improving BLEU-4 scores by +5.1, +1.11, +1.4, and +1.61 on the CSL-Daily, PHOENIX-2014T, How2Sign, and OpenASL datasets, respectively. To the best of our knowledge, this is the first work to incorporate GRPO into SLT. Extensive experiments and ablation studies validate the effectiveness of GRPO-based optimization in enhancing both translation quality and semantic consistency.
Sim4Seg: Boosting Multimodal Multi-disease Medical Diagnosis Segmentation with Region-Aware Vision-Language Similarity Masks
Nov 10, 2025Despite significant progress in pixel-level medical image analysis, existing medical image segmentation models rarely explore medical segmentation and diagnosis tasks jointly. However, it is crucial for patients that models can provide explainable diagnoses along with medical segmentation results. In this paper, we introduce a medical vision-language task named Medical Diagnosis Segmentation (MDS), which aims to understand clinical queries for medical images and generate the corresponding segmentation masks as well as diagnostic results. To facilitate this task, we first present the Multimodal Multi-disease Medical Diagnosis Segmentation (M3DS) dataset, containing diverse multimodal multi-disease medical images paired with their corresponding segmentation masks and diagnosis chain-of-thought, created via an automated diagnosis chain-of-thought generation pipeline. Moreover, we propose Sim4Seg, a novel framework that improves the performance of diagnosis segmentation by taking advantage of the Region-Aware Vision-Language Similarity to Mask (RVLS2M) module. To improve overall performance, we investigate a test-time scaling strategy for MDS tasks. Experimental results demonstrate that our method outperforms the baselines in both segmentation and diagnosis.
TheraMind: A Strategic and Adaptive Agent for Longitudinal Psychological Counseling
Oct 29, 2025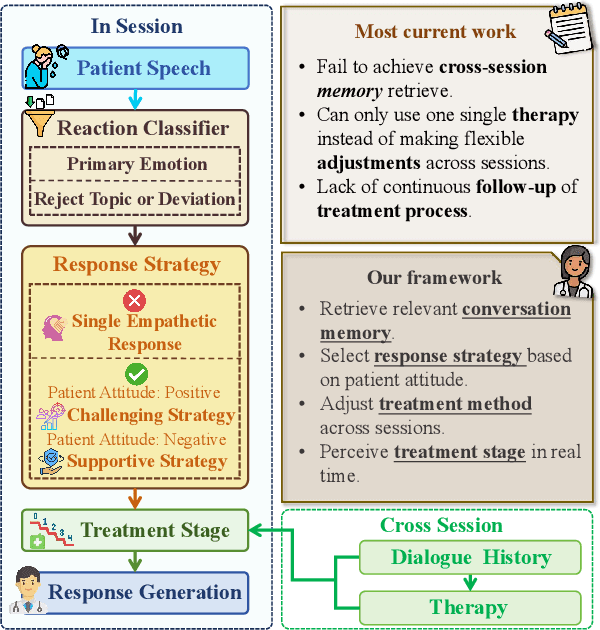
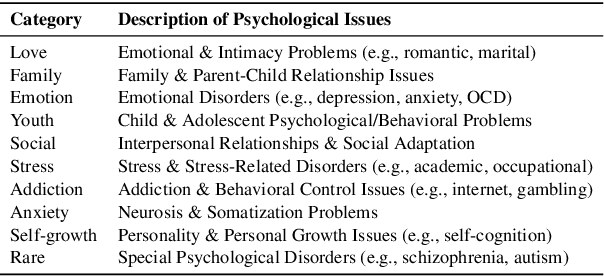
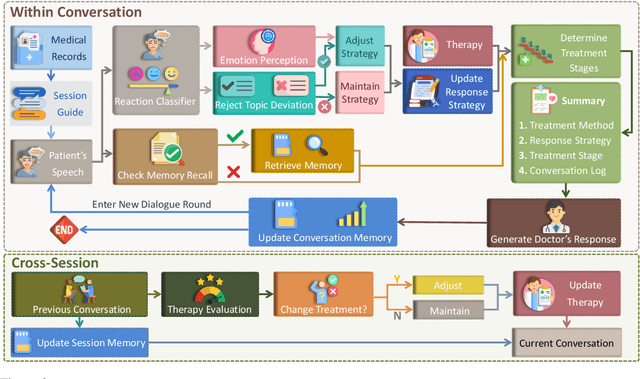
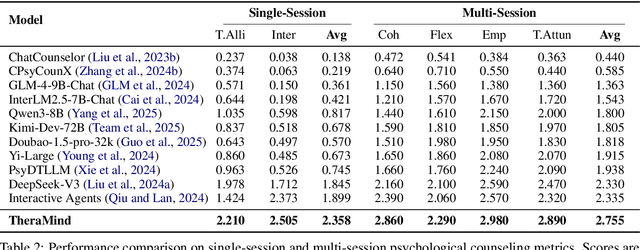
Large language models (LLMs) in psychological counseling have attracted increasing attention. However, existing approaches often lack emotional understanding, adaptive strategies, and the use of therapeutic methods across multiple sessions with long-term memory, leaving them far from real clinical practice. To address these critical gaps, we introduce TheraMind, a strategic and adaptive agent for longitudinal psychological counseling. The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning. The Intra-Session Loop perceives the patient's emotional state to dynamically select response strategies while leveraging cross-session memory to ensure continuity. Crucially, the Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions. We validate our approach in a high-fidelity simulation environment grounded in real clinical cases. Extensive evaluations show that TheraMind outperforms other methods, especially on multi-session metrics like Coherence, Flexibility, and Therapeutic Attunement, validating the effectiveness of its dual-loop design in emulating strategic, adaptive, and longitudinal therapeutic behavior. The code is publicly available at https://0mwwm0.github.io/TheraMind/.
Semantic Causality-Aware Vision-Based 3D Occupancy Prediction
Sep 10, 2025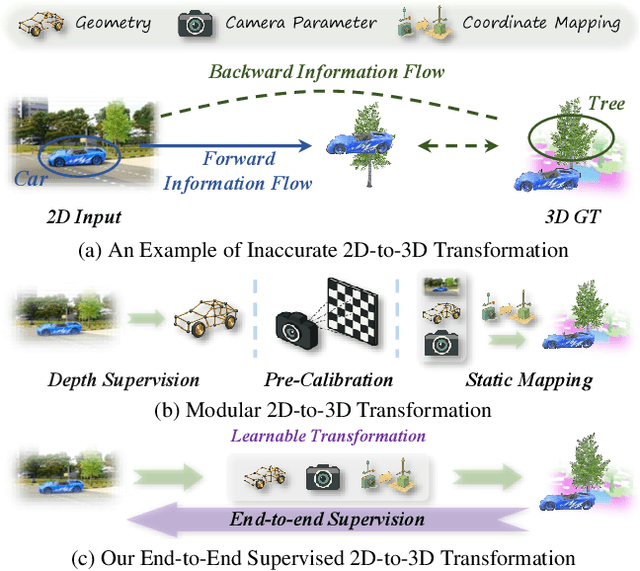

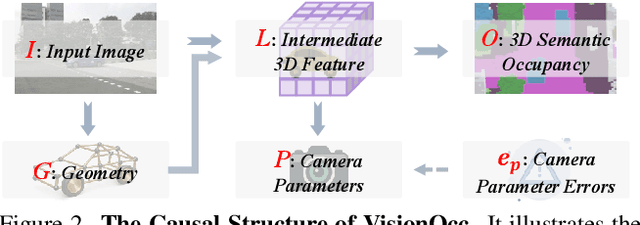
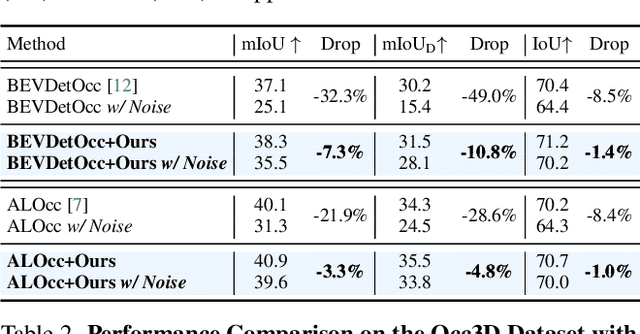
Vision-based 3D semantic occupancy prediction is a critical task in 3D vision that integrates volumetric 3D reconstruction with semantic understanding. Existing methods, however, often rely on modular pipelines. These modules are typically optimized independently or use pre-configured inputs, leading to cascading errors. In this paper, we address this limitation by designing a novel causal loss that enables holistic, end-to-end supervision of the modular 2D-to-3D transformation pipeline. Grounded in the principle of 2D-to-3D semantic causality, this loss regulates the gradient flow from 3D voxel representations back to the 2D features. Consequently, it renders the entire pipeline differentiable, unifying the learning process and making previously non-trainable components fully learnable. Building on this principle, we propose the Semantic Causality-Aware 2D-to-3D Transformation, which comprises three components guided by our causal loss: Channel-Grouped Lifting for adaptive semantic mapping, Learnable Camera Offsets for enhanced robustness against camera perturbations, and Normalized Convolution for effective feature propagation. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the Occ3D benchmark, demonstrating significant robustness to camera perturbations and improved 2D-to-3D semantic consistency.
MAM: Modular Multi-Agent Framework for Multi-Modal Medical Diagnosis via Role-Specialized Collaboration
Jun 24, 2025Recent advancements in medical Large Language Models (LLMs) have showcased their powerful reasoning and diagnostic capabilities. Despite their success, current unified multimodal medical LLMs face limitations in knowledge update costs, comprehensiveness, and flexibility. To address these challenges, we introduce the Modular Multi-Agent Framework for Multi-Modal Medical Diagnosis (MAM). Inspired by our empirical findings highlighting the benefits of role assignment and diagnostic discernment in LLMs, MAM decomposes the medical diagnostic process into specialized roles: a General Practitioner, Specialist Team, Radiologist, Medical Assistant, and Director, each embodied by an LLM-based agent. This modular and collaborative framework enables efficient knowledge updates and leverages existing medical LLMs and knowledge bases. Extensive experimental evaluations conducted on a wide range of publicly accessible multimodal medical datasets, incorporating text, image, audio, and video modalities, demonstrate that MAM consistently surpasses the performance of modality-specific LLMs. Notably, MAM achieves significant performance improvements ranging from 18% to 365% compared to baseline models. Our code is released at https://github.com/yczhou001/MAM.
ComplexBench-Edit: Benchmarking Complex Instruction-Driven Image Editing via Compositional Dependencies
Jun 15, 2025Text-driven image editing has achieved remarkable success in following single instructions. However, real-world scenarios often involve complex, multi-step instructions, particularly ``chain'' instructions where operations are interdependent. Current models struggle with these intricate directives, and existing benchmarks inadequately evaluate such capabilities. Specifically, they often overlook multi-instruction and chain-instruction complexities, and common consistency metrics are flawed. To address this, we introduce ComplexBench-Edit, a novel benchmark designed to systematically assess model performance on complex, multi-instruction, and chain-dependent image editing tasks. ComplexBench-Edit also features a new vision consistency evaluation method that accurately assesses non-modified regions by excluding edited areas. Furthermore, we propose a simple yet powerful Chain-of-Thought (CoT)-based approach that significantly enhances the ability of existing models to follow complex instructions. Our extensive experiments demonstrate ComplexBench-Edit's efficacy in differentiating model capabilities and highlight the superior performance of our CoT-based method in handling complex edits. The data and code are released at https://github.com/llllly26/ComplexBench-Edit.
Draw ALL Your Imagine: A Holistic Benchmark and Agent Framework for Complex Instruction-based Image Generation
May 30, 2025Recent advancements in text-to-image (T2I) generation have enabled models to produce high-quality images from textual descriptions. However, these models often struggle with complex instructions involving multiple objects, attributes, and spatial relationships. Existing benchmarks for evaluating T2I models primarily focus on general text-image alignment and fail to capture the nuanced requirements of complex, multi-faceted prompts. Given this gap, we introduce LongBench-T2I, a comprehensive benchmark specifically designed to evaluate T2I models under complex instructions. LongBench-T2I consists of 500 intricately designed prompts spanning nine diverse visual evaluation dimensions, enabling a thorough assessment of a model's ability to follow complex instructions. Beyond benchmarking, we propose an agent framework (Plan2Gen) that facilitates complex instruction-driven image generation without requiring additional model training. This framework integrates seamlessly with existing T2I models, using large language models to interpret and decompose complex prompts, thereby guiding the generation process more effectively. As existing evaluation metrics, such as CLIPScore, fail to adequately capture the nuances of complex instructions, we introduce an evaluation toolkit that automates the quality assessment of generated images using a set of multi-dimensional metrics. The data and code are released at https://github.com/yczhou001/LongBench-T2I.
Safety Alignment via Constrained Knowledge Unlearning
May 24, 2025Despite significant progress in safety alignment, large language models (LLMs) remain susceptible to jailbreak attacks. Existing defense mechanisms have not fully deleted harmful knowledge in LLMs, which allows such attacks to bypass safeguards and produce harmful outputs. To address this challenge, we propose a novel safety alignment strategy, Constrained Knowledge Unlearning (CKU), which focuses on two primary objectives: knowledge localization and retention, and unlearning harmful knowledge. CKU works by scoring neurons in specific multilayer perceptron (MLP) layers to identify a subset U of neurons associated with useful knowledge. During the unlearning process, CKU prunes the gradients of neurons in U to preserve valuable knowledge while effectively mitigating harmful content. Experimental results demonstrate that CKU significantly enhances model safety without compromising overall performance, offering a superior balance between safety and utility compared to existing methods. Additionally, our analysis of neuron knowledge sensitivity across various MLP layers provides valuable insights into the mechanics of safety alignment and model knowledge editing.
Self-Rewarding Large Vision-Language Models for Optimizing Prompts in Text-to-Image Generation
May 22, 2025Text-to-image models are powerful for producing high-quality images based on given text prompts, but crafting these prompts often requires specialized vocabulary. To address this, existing methods train rewriting models with supervision from large amounts of manually annotated data and trained aesthetic assessment models. To alleviate the dependence on data scale for model training and the biases introduced by trained models, we propose a novel prompt optimization framework, designed to rephrase a simple user prompt into a sophisticated prompt to a text-to-image model. Specifically, we employ the large vision language models (LVLMs) as the solver to rewrite the user prompt, and concurrently, employ LVLMs as a reward model to score the aesthetics and alignment of the images generated by the optimized prompt. Instead of laborious human feedback, we exploit the prior knowledge of the LVLM to provide rewards, i.e., AI feedback. Simultaneously, the solver and the reward model are unified into one model and iterated in reinforcement learning to achieve self-improvement by giving a solution and judging itself. Results on two popular datasets demonstrate that our method outperforms other strong competitors.