 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery as Anchor: Scenario-Adaptive User Representation via Large Language Model
Feb 17, 2026Industrial-scale user representation learning requires balancing robust universality with acute task-sensitivity. However, existing paradigms primarily yield static, task-agnostic embeddings that struggle to reconcile the divergent requirements of downstream scenarios within unified vector spaces. Furthermore, heterogeneous multi-source data introduces inherent noise and modality conflicts, degrading representation. We propose Query-as-Anchor, a framework shifting user modeling from static encoding to dynamic, query-aware synthesis. To empower Large Language Models (LLMs) with deep user understanding, we first construct UserU, an industrial-scale pre-training dataset that aligns multi-modal behavioral sequences with user understanding semantics, and our Q-Anchor Embedding architecture integrates hierarchical coarse-to-fine encoders into dual-tower LLMs via joint contrastive-autoregressive optimization for query-aware user representation. To bridge the gap between general pre-training and specialized business logic, we further introduce Cluster-based Soft Prompt Tuning to enforce discriminative latent structures, effectively aligning model attention with scenario-specific modalities. For deployment, anchoring queries at sequence termini enables KV-cache-accelerated inference with negligible incremental latency. Evaluations on 10 Alipay industrial benchmarks show consistent SOTA performance, strong scalability, and efficient deployment. Large-scale online A/B testing in Alipay's production system across two real-world scenarios further validates its practical effectiveness. Our code is prepared for public release and will be available at: https://github.com/JhCircle/Q-Anchor.
How Do Decoder-Only LLMs Perceive Users? Rethinking Attention Masking for User Representation Learning
Feb 11, 2026Decoder-only large language models are increasingly used as behavioral encoders for user representation learning, yet the impact of attention masking on the quality of user embeddings remains underexplored. In this work, we conduct a systematic study of causal, hybrid, and bidirectional attention masks within a unified contrastive learning framework trained on large-scale real-world Alipay data that integrates long-horizon heterogeneous user behaviors. To improve training dynamics when transitioning from causal to bidirectional attention, we propose Gradient-Guided Soft Masking, a gradient-based pre-warmup applied before a linear scheduler that gradually opens future attention during optimization. Evaluated on 9 industrial user cognition benchmarks covering prediction, preference, and marketing sensitivity tasks, our approach consistently yields more stable training and higher-quality bidirectional representations compared with causal, hybrid, and scheduler-only baselines, while remaining compatible with decoder pretraining. Overall, our findings highlight the importance of masking design and training transition in adapting decoder-only LLMs for effective user representation learning. Our code is available at https://github.com/JhCircle/Deepfind-GGSM.
VideoAfford: Grounding 3D Affordance from Human-Object-Interaction Videos via Multimodal Large Language Model
Feb 10, 20263D affordance grounding aims to highlight the actionable regions on 3D objects, which is crucial for robotic manipulation. Previous research primarily focused on learning affordance knowledge from static cues such as language and images, which struggle to provide sufficient dynamic interaction context that can reveal temporal and causal cues. To alleviate this predicament, we collect a comprehensive video-based 3D affordance dataset, \textit{VIDA}, which contains 38K human-object-interaction videos covering 16 affordance types, 38 object categories, and 22K point clouds. Based on \textit{VIDA}, we propose a strong baseline: VideoAfford, which activates multimodal large language models with additional affordance segmentation capabilities, enabling both world knowledge reasoning and fine-grained affordance grounding within a unified framework. To enhance action understanding capability, we leverage a latent action encoder to extract dynamic interaction priors from HOI videos. Moreover, we introduce a \textit{spatial-aware} loss function to enable VideoAfford to obtain comprehensive 3D spatial knowledge. Extensive experimental evaluations demonstrate that our model significantly outperforms well-established methods and exhibits strong open-world generalization with affordance reasoning abilities. All datasets and code will be publicly released to advance research in this area.
PaperX: A Unified Framework for Multimodal Academic Presentation Generation with Scholar DAG
Feb 05, 2026Transforming scientific papers into multimodal presentation content is essential for research dissemination but remains labor intensive. Existing automated solutions typically treat each format as an isolated downstream task, leading to redundant processing and semantic inconsistency. We introduce PaperX, a unified framework that models academic presentation generation as a structural transformation and rendering process. Central to our approach is the Scholar DAG, an intermediate representation that decouples the paper's logical structure from its final presentation syntax. By applying adaptive graph traversal strategies, PaperX generates diverse, high quality outputs from a single source. Comprehensive evaluations demonstrate that our framework achieves the state of the art performance in content fidelity and aesthetic quality while significantly improving cost efficiency compared to specialized single task agents.
Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning
Jan 07, 2026The integration of large language models (LLMs) with external tools has significantly expanded the capabilities of AI agents. However, as the diversity of both LLMs and tools increases, selecting the optimal model-tool combination becomes a high-dimensional optimization challenge. Existing approaches often rely on a single model or fixed tool-calling logic, failing to exploit the performance variations across heterogeneous model-tool pairs. In this paper, we present ATLAS (Adaptive Tool-LLM Alignment and Synergistic Invocation), a dual-path framework for dynamic tool usage in cross-domain complex reasoning. ATLAS operates via a dual-path approach: (1) \textbf{training-free cluster-based routing} that exploits empirical priors for domain-specific alignment, and (2) \textbf{RL-based multi-step routing} that explores autonomous trajectories for out-of-distribution generalization. Extensive experiments across 15 benchmarks demonstrate that our method outperforms closed-source models like GPT-4o, surpassing existing routing methods on both in-distribution (+10.1%) and out-of-distribution (+13.1%) tasks. Furthermore, our framework shows significant gains in visual reasoning by orchestrating specialized multi-modal tools.
Affordance-R1: Reinforcement Learning for Generalizable Affordance Reasoning in Multimodal Large Language Model
Aug 08, 2025Affordance grounding focuses on predicting the specific regions of objects that are associated with the actions to be performed by robots. It plays a vital role in the fields of human-robot interaction, human-object interaction, embodied manipulation, and embodied perception. Existing models often neglect the affordance shared among different objects because they lack the Chain-of-Thought(CoT) reasoning abilities, limiting their out-of-domain (OOD) generalization and explicit reasoning capabilities. To address these challenges, we propose Affordance-R1, the first unified affordance grounding framework that integrates cognitive CoT guided Group Relative Policy Optimization (GRPO) within a reinforcement learning paradigm. Specifically, we designed a sophisticated affordance function, which contains format, perception, and cognition rewards to effectively guide optimization directions. Furthermore, we constructed a high-quality affordance-centric reasoning dataset, ReasonAff, to support training. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Affordance-R1 achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Comprehensive experiments demonstrate that our model outperforms well-established methods and exhibits open-world generalization. To the best of our knowledge, Affordance-R1 is the first to integrate GRPO-based RL with reasoning into affordance reasoning. The code of our method and our dataset is released on https://github.com/hq-King/Affordance-R1.
Draw ALL Your Imagine: A Holistic Benchmark and Agent Framework for Complex Instruction-based Image Generation
May 30, 2025



Recent advancements in text-to-image (T2I) generation have enabled models to produce high-quality images from textual descriptions. However, these models often struggle with complex instructions involving multiple objects, attributes, and spatial relationships. Existing benchmarks for evaluating T2I models primarily focus on general text-image alignment and fail to capture the nuanced requirements of complex, multi-faceted prompts. Given this gap, we introduce LongBench-T2I, a comprehensive benchmark specifically designed to evaluate T2I models under complex instructions. LongBench-T2I consists of 500 intricately designed prompts spanning nine diverse visual evaluation dimensions, enabling a thorough assessment of a model's ability to follow complex instructions. Beyond benchmarking, we propose an agent framework (Plan2Gen) that facilitates complex instruction-driven image generation without requiring additional model training. This framework integrates seamlessly with existing T2I models, using large language models to interpret and decompose complex prompts, thereby guiding the generation process more effectively. As existing evaluation metrics, such as CLIPScore, fail to adequately capture the nuances of complex instructions, we introduce an evaluation toolkit that automates the quality assessment of generated images using a set of multi-dimensional metrics. The data and code are released at https://github.com/yczhou001/LongBench-T2I.
Can Pruning Improve Reasoning? Revisiting Long-CoT Compression with Capability in Mind for Better Reasoning
May 20, 2025



Long chain-of-thought (Long-CoT) reasoning improves accuracy in LLMs, yet its verbose, self-reflective style often hinders effective distillation into small language models (SLMs). We revisit Long-CoT compression through the lens of capability alignment and ask: Can pruning improve reasoning? We propose Prune-on-Logic, a structure-aware framework that transforms Long-CoT into logic graphs and selectively prunes low-utility reasoning steps under self-verification constraints. Through systematic analysis across three pruning strategies -- targeting entire chains, core reasoning, and verification -- we find that pruning verification steps yields consistent accuracy gains while reducing inference cost, outperforming token-level baselines and uncompressed fine-tuning. In contrast, pruning reasoning or all-chain steps degrades performance, revealing that small models benefit not from shorter CoTs, but from semantically leaner ones. Our findings highlight pruning as a structural optimization strategy for aligning CoT reasoning with SLM capacity.
Less is More: Enhancing Structured Multi-Agent Reasoning via Quality-Guided Distillation
Apr 23, 2025

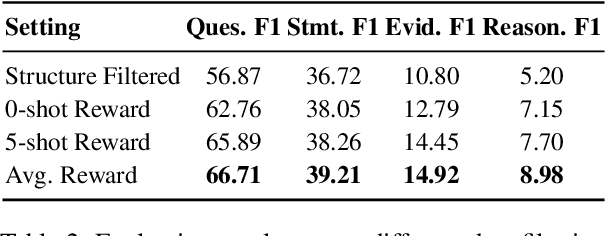

The XLLM@ACL2025 Shared Task-III formulates a low-resource structural reasoning task that challenges LLMs to generate interpretable, step-by-step rationales with minimal labeled data. We present Less is More, the third-place winning approach in the XLLM@ACL2025 Shared Task-III, which focuses on structured reasoning from only 24 labeled examples. Our approach leverages a multi-agent framework with reverse-prompt induction, retrieval-augmented reasoning synthesis via GPT-4o, and dual-stage reward-guided filtering to distill high-quality supervision across three subtasks: question parsing, CoT parsing, and step-level verification. All modules are fine-tuned from Meta-Llama-3-8B-Instruct under a unified LoRA+ setup. By combining structure validation with reward filtering across few-shot and zero-shot prompts, our pipeline consistently improves structure reasoning quality. These results underscore the value of controllable data distillation in enhancing structured inference under low-resource constraints. Our code is available at https://github.com/Jiahao-Yuan/Less-is-More.
Draw with Thought: Unleashing Multimodal Reasoning for Scientific Diagram Generation
Apr 13, 2025Scientific diagrams are vital tools for communicating structured knowledge across disciplines. However, they are often published as static raster images, losing symbolic semantics and limiting reuse. While Multimodal Large Language Models (MLLMs) offer a pathway to bridging vision and structure, existing methods lack semantic control and structural interpretability, especially on complex diagrams. We propose Draw with Thought (DwT), a training-free framework that guides MLLMs to reconstruct diagrams into editable mxGraph XML code through cognitively-grounded Chain-of-Thought reasoning. DwT enables interpretable and controllable outputs without model fine-tuning by dividing the task into two stages: Coarse-to-Fine Planning, which handles perceptual structuring and semantic specification, and Structure-Aware Code Generation, enhanced by format-guided refinement. To support evaluation, we release Plot2XML, a benchmark of 247 real-world scientific diagrams with gold-standard XML annotations. Extensive experiments across eight MLLMs show that our approach yields high-fidelity, semantically aligned, and structurally valid reconstructions, with human evaluations confirming strong alignment in both accuracy and visual aesthetics, offering a scalable solution for converting static visuals into executable representations and advancing machine understanding of scientific graphics.