 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine: A Hybrid Self-Supervised Method for Non-rigid 3D Shape Matching
Jun 25, 2026Non-rigid 3D shape matching is a fundamental task in computer vision and graphics. In this paper, we propose a hybrid self-supervised method based on a coarse-to-fine strategy, which ensures consistency between the coarse mapping and the refined correspondence produced by our refinement module. The architecture features a dual-branch design, consisting of two symmetric functional map learning streams: one based on the Laplacian basis and the other utilizing the elastic basis. Extensive experiments show that our approach not only maintains computational efficiency, but also achieves state-of-the-art performance across a variety of challenging scenarios, including non-isometric deformations and topological noise. Finally, we rigorously demonstrate that contrastive energies promote feature discrimination. Furthermore, integrating these energies with existing methods yields consistent improvements, validating the overall efficacy of our approach. Our code is available at https://github.com/LuoFeifan77/Coarse-to-Fine-Hybrid-Self-Supervised-Matching.
Multi-domain Multi-modal Document Classification Benchmark with a Multi-level Taxonomy
May 11, 2026Document classification forms the backbone of modern enterprise content management, yet existing benchmarks remain trapped in oversimplified paradigms -- single domain settings with flat label structures -- that bear little resemblance to the hierarchical, multi-modal, and cross-domain nature of real-world business documents. This gap not only misrepresents practical complexity but also stifles progress toward industrially viable document intelligence. To bridge this gap, we construct the first Multi-level, Multi-domain, Multi-modal document classification Benchmark (MMM-Bench). MMM-Bench includes (1) a deeply hierarchical taxonomy spanning five levels that capture the authentic organizational logic of business documentation; and (2) 5,990 real-world multi-modal documents meticulously curated from 12 commercial domains in Alibaba. Each document is manually annotated with a complete hierarchical path by domain experts. We establish comprehensive baselines on MMM-Bench, which consists of open-weight models and API-based models. Through systematic experiments, we identify four fundamental challenges within MMM-Bench and propose corresponding insights. To provide a solid foundation for advancing research in multi-level, multi-domain document classification, we release all of the data and the evaluation toolkit of MMM-Bench at https://github.com/MMMDC-Bench/MMMDC-Bench.
TimeOmni-VL: Unified Models for Time Series Understanding and Generation
Feb 19, 2026Recent time series modeling faces a sharp divide between numerical generation and semantic understanding, with research showing that generation models often rely on superficial pattern matching, while understanding-oriented models struggle with high-fidelity numerical output. Although unified multimodal models (UMMs) have bridged this gap in vision, their potential for time series remains untapped. We propose TimeOmni-VL, the first vision-centric framework that unifies time series understanding and generation through two key innovations: (1) Fidelity-preserving bidirectional mapping between time series and images (Bi-TSI), which advances Time Series-to-Image (TS2I) and Image-to-Time Series (I2TS) conversions to ensure near-lossless transformations. (2) Understanding-guided generation. We introduce TSUMM-Suite, a novel dataset consists of six understanding tasks rooted in time series analytics that are coupled with two generation tasks. With a calibrated Chain-of-Thought, TimeOmni-VL is the first to leverage time series understanding as an explicit control signal for high-fidelity generation. Experiments confirm that this unified approach significantly improves both semantic understanding and numerical precision, establishing a new frontier for multimodal time series modeling.
LGAN: An Efficient High-Order Graph Neural Network via the Line Graph Aggregation
Dec 11, 2025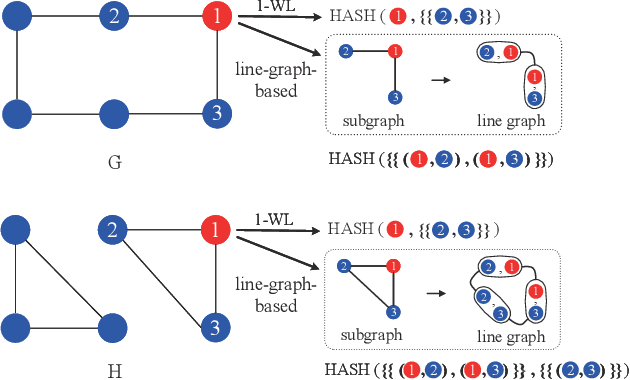
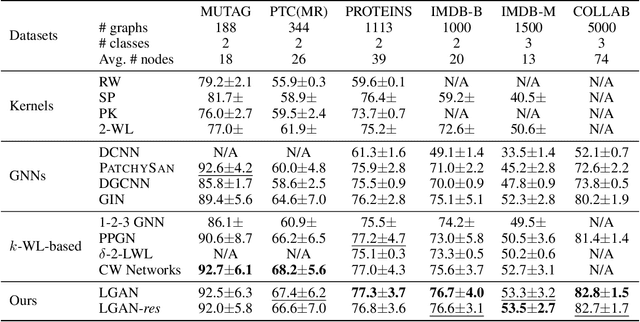
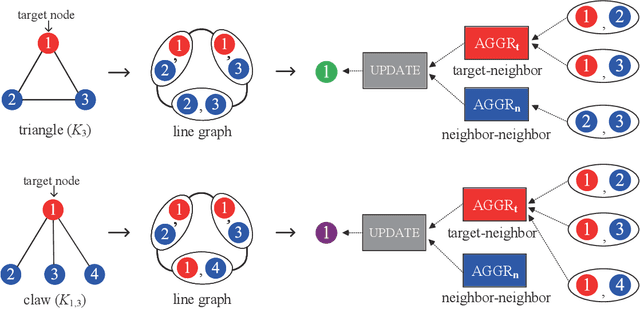
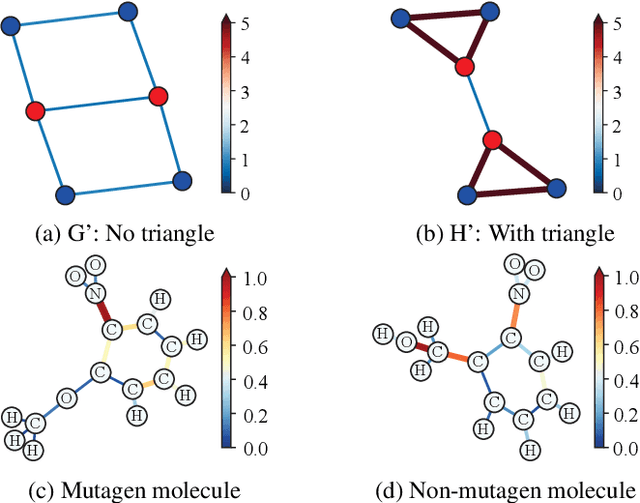
Graph Neural Networks (GNNs) have emerged as a dominant paradigm for graph classification. Specifically, most existing GNNs mainly rely on the message passing strategy between neighbor nodes, where the expressivity is limited by the 1-dimensional Weisfeiler-Lehman (1-WL) test. Although a number of k-WL-based GNNs have been proposed to overcome this limitation, their computational cost increases rapidly with k, significantly restricting the practical applicability. Moreover, since the k-WL models mainly operate on node tuples, these k-WL-based GNNs cannot retain fine-grained node- or edge-level semantics required by attribution methods (e.g., Integrated Gradients), leading to the less interpretable problem. To overcome the above shortcomings, in this paper, we propose a novel Line Graph Aggregation Network (LGAN), that constructs a line graph from the induced subgraph centered at each node to perform the higher-order aggregation. We theoretically prove that the LGAN not only possesses the greater expressive power than the 2-WL under injective aggregation assumptions, but also has lower time complexity. Empirical evaluations on benchmarks demonstrate that the LGAN outperforms state-of-the-art k-WL-based GNNs, while offering better interpretability.
MaskAnyNet: Rethinking Masked Image Regions as Valuable Information in Supervised Learning
Nov 16, 2025In supervised learning, traditional image masking faces two key issues: (i) discarded pixels are underutilized, leading to a loss of valuable contextual information; (ii) masking may remove small or critical features, especially in fine-grained tasks. In contrast, masked image modeling (MIM) has demonstrated that masked regions can be reconstructed from partial input, revealing that even incomplete data can exhibit strong contextual consistency with the original image. This highlights the potential of masked regions as sources of semantic diversity. Motivated by this, we revisit the image masking approach, proposing to treat masked content as auxiliary knowledge rather than ignored. Based on this, we propose MaskAnyNet, which combines masking with a relearning mechanism to exploit both visible and masked information. It can be easily extended to any model with an additional branch to jointly learn from the recomposed masked region. This approach leverages the semantic diversity of the masked regions to enrich features and preserve fine-grained details. Experiments on CNN and Transformer backbones show consistent gains across multiple benchmarks. Further analysis confirms that the proposed method improves semantic diversity through the reuse of masked content.
Ontology-Enhanced Knowledge Graph Completion using Large Language Models
Jul 28, 2025Large Language Models (LLMs) have been extensively adopted in Knowledge Graph Completion (KGC), showcasing significant research advancements. However, as black-box models driven by deep neural architectures, current LLM-based KGC methods rely on implicit knowledge representation with parallel propagation of erroneous knowledge, thereby hindering their ability to produce conclusive and decisive reasoning outcomes. We aim to integrate neural-perceptual structural information with ontological knowledge, leveraging the powerful capabilities of LLMs to achieve a deeper understanding of the intrinsic logic of the knowledge. We propose an ontology enhanced KGC method using LLMs -- OL-KGC. It first leverages neural perceptual mechanisms to effectively embed structural information into the textual space, and then uses an automated extraction algorithm to retrieve ontological knowledge from the knowledge graphs (KGs) that needs to be completed, which is further transformed into a textual format comprehensible to LLMs for providing logic guidance. We conducted extensive experiments on three widely-used benchmarks -- FB15K-237, UMLS and WN18RR. The experimental results demonstrate that OL-KGC significantly outperforms existing mainstream KGC methods across multiple evaluation metrics, achieving state-of-the-art performance.
T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models
May 05, 2025Text-to-Time Series generation holds significant potential to address challenges such as data sparsity, imbalance, and limited availability of multimodal time series datasets across domains. While diffusion models have achieved remarkable success in Text-to-X (e.g., vision and audio data) generation, their use in time series generation remains in its nascent stages. Existing approaches face two critical limitations: (1) the lack of systematic exploration of general-proposed time series captions, which are often domain-specific and struggle with generalization; and (2) the inability to generate time series of arbitrary lengths, limiting their applicability to real-world scenarios. In this work, we first categorize time series captions into three levels: point-level, fragment-level, and instance-level. Additionally, we introduce a new fragment-level dataset containing over 600,000 high-resolution time series-text pairs. Second, we propose Text-to-Series (T2S), a diffusion-based framework that bridges the gap between natural language and time series in a domain-agnostic manner. T2S employs a length-adaptive variational autoencoder to encode time series of varying lengths into consistent latent embeddings. On top of that, T2S effectively aligns textual representations with latent embeddings by utilizing Flow Matching and employing Diffusion Transformer as the denoiser. We train T2S in an interleaved paradigm across multiple lengths, allowing it to generate sequences of any desired length. Extensive evaluations demonstrate that T2S achieves state-of-the-art performance across 13 datasets spanning 12 domains.
Research on reinforcement learning based warehouse robot navigation algorithm in complex warehouse layout
Nov 09, 2024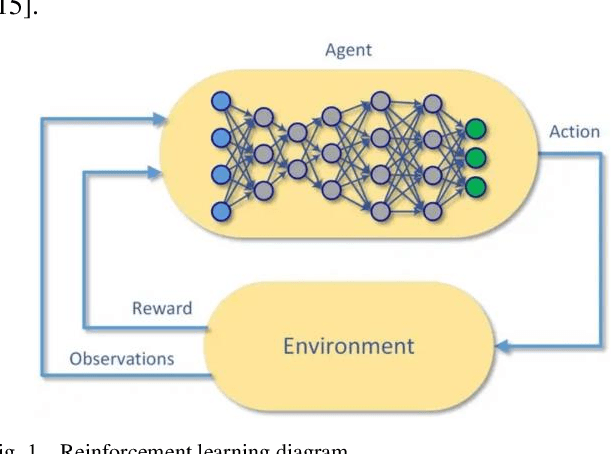
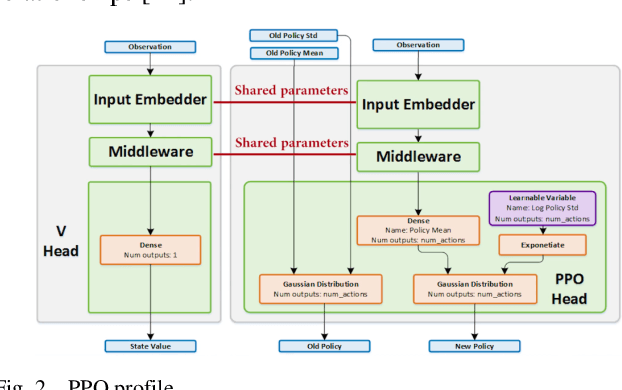
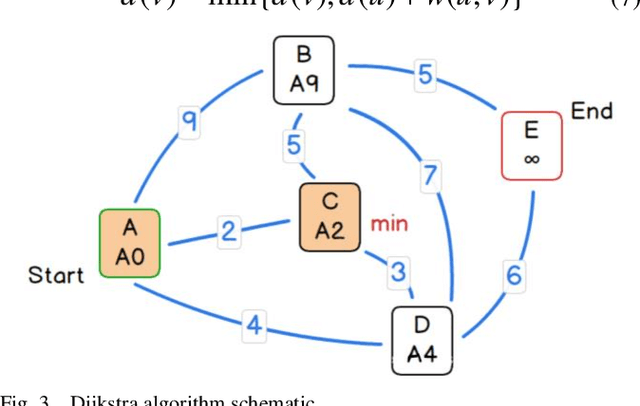
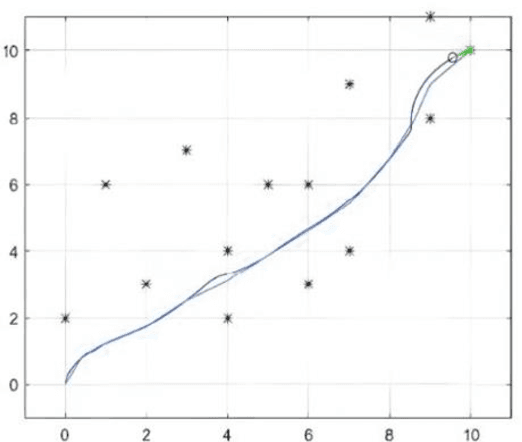
In this paper, how to efficiently find the optimal path in complex warehouse layout and make real-time decision is a key problem. This paper proposes a new method of Proximal Policy Optimization (PPO) and Dijkstra's algorithm, Proximal policy-Dijkstra (PP-D). PP-D method realizes efficient strategy learning and real-time decision making through PPO, and uses Dijkstra algorithm to plan the global optimal path, thus ensuring high navigation accuracy and significantly improving the efficiency of path planning. Specifically, PPO enables robots to quickly adapt and optimize action strategies in dynamic environments through its stable policy updating mechanism. Dijkstra's algorithm ensures global optimal path planning in static environment. Finally, through the comparison experiment and analysis of the proposed framework with the traditional algorithm, the results show that the PP-D method has significant advantages in improving the accuracy of navigation prediction and enhancing the robustness of the system. Especially in complex warehouse layout, PP-D method can find the optimal path more accurately and reduce collision and stagnation. This proves the reliability and effectiveness of the robot in the study of complex warehouse layout navigation algorithm.
Weighted Diversified Sampling for Efficient Data-Driven Single-Cell Gene-Gene Interaction Discovery
Oct 21, 2024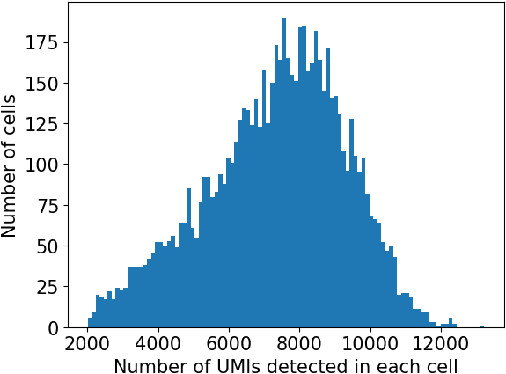
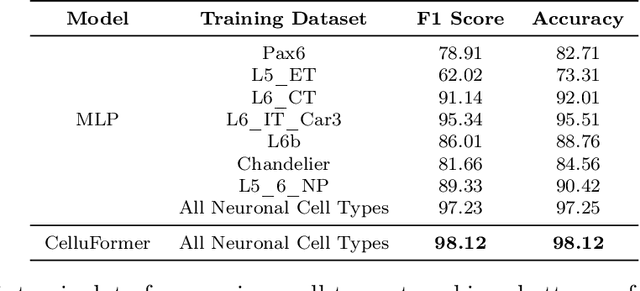
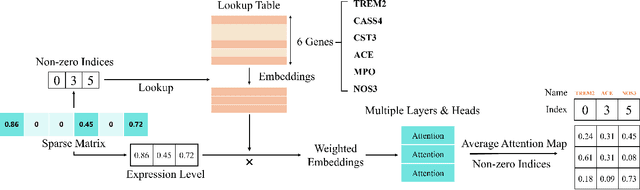
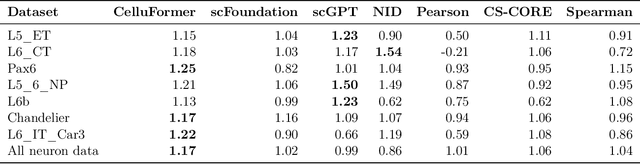
Gene-gene interactions play a crucial role in the manifestation of complex human diseases. Uncovering significant gene-gene interactions is a challenging task. Here, we present an innovative approach utilizing data-driven computational tools, leveraging an advanced Transformer model, to unearth noteworthy gene-gene interactions. Despite the efficacy of Transformer models, their parameter intensity presents a bottleneck in data ingestion, hindering data efficiency. To mitigate this, we introduce a novel weighted diversified sampling algorithm. This algorithm computes the diversity score of each data sample in just two passes of the dataset, facilitating efficient subset generation for interaction discovery. Our extensive experimentation demonstrates that by sampling a mere 1\% of the single-cell dataset, we achieve performance comparable to that of utilizing the entire dataset.
GPTON: Generative Pre-trained Transformers enhanced with Ontology Narration for accurate annotation of biological data
Oct 12, 2024

By leveraging GPT-4 for ontology narration, we developed GPTON to infuse structured knowledge into LLMs through verbalized ontology terms, achieving accurate text and ontology annotations for over 68% of gene sets in the top five predictions. Manual evaluations confirm GPTON's robustness, highlighting its potential to harness LLMs and structured knowledge to significantly advance biomedical research beyond gene set annotation.